Imbalanced Dataset: Thách thức và giải pháp trong Machine Learning
1. Giới thiệu
Trong lĩnh vực Machine Learning, một trong những thách thức phổ biến mà các nhà khoa học dữ liệu gặp phải là vấn đề Imbalanced Dataset (Dữ liệu mất cân bằng). Điều này thường xuất hiện trong các ứng dụng thực tế, nơi mà một hoặc nhiều lớp của tập dữ liệu có số lượng mẫu lớn hơn nhiều so với các lớp còn lại.
Ví dụ, trong các bài toán phân loại y tế, số lượng bệnh nhân mắc bệnh cụ thể có thể ít hơn rất nhiều so với số lượng người khỏe mạnh.
Trong bài toán phân loại email, nếu có 10.000 email mà chỉ 500 trong số đó là spam, chúng ta có một tập dữ liệu mất cân bằng. Tỷ lệ mẫu giữa các lớp có thể không đồng đều, và điều này thường gây ra vấn đề lớn trong việc huấn luyện mô hình Machine Learning.
2. Tác động của Imbalanced Dataset đến mô hình Machine Learning
Khi làm việc với Imbalanced Dataset, mô hình Machine Learning có thể gặp phải một số vấn đề nghiêm trọng. Các vấn đề chính bao gồm:
2.1. Thiên vị dự đoán
Mô hình có thể học cách dự đoán lớp chiếm đa số một cách thường xuyên, dẫn đến việc bỏ qua hoặc sai sót khi dự đoán các mẫu thuộc lớp chiếm thiểu số.
2.2. Hiệu suất đánh giá không chính xác
Chỉ số độ chính xác (Accuracy) có thể bị đánh lừa, ví dụ: nếu mô hình dự đoán tất cả các mẫu thuộc lớp chiếm đa số, nó có thể đạt được độ chính xác cao mặc dù không thực sự hiệu quả trong việc phân loại.
2.3. Mất khả năng tổng quát hóa
Mô hình có thể không học được các đặc trưng quan trọng để phân biệt các lớp, đặc biệt là lớp chiếm thiểu số, do đó khả năng tổng quát hóa của mô hình sẽ bị ảnh hưởng nghiêm trọng.
2.4. Ảnh hưởng của Imbalanced Dataset
Giả sử chúng ta có một tập dữ liệu phân loại nhị phân với 95% thuộc lớp A và 5% thuộc lớp B. Nếu một mô hình chỉ đơn giản dự đoán tất cả các mẫu thuộc lớp A, nó sẽ có độ chính xác 95%, nhưng nó hoàn toàn không hữu ích vì không thể nhận diện được các mẫu thuộc lớp B.
3. Các phương pháp đánh giá mô hình với Imbalanced Dataset
Khi làm việc với Imbalanced Dataset, việc sử dụng các phương pháp đánh giá thông thường như độ chính xác (Accuracy) có thể gây hiểu nhầm về hiệu suất thực sự của mô hình. Do đó, cần sử dụng các chỉ số khác phù hợp hơn với đặc thù của dữ liệu mất cân bằng để đánh giá hiệu quả của mô hình. Dưới đây là những phương pháp đánh giá quan trọng khi làm việc với Imbalanced Dataset.
3.1. Confusion Matrix
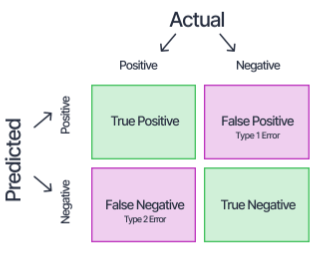
Confusion Matrix là một công cụ quan trọng để phân tích chi tiết các dự đoán của mô hình. Nó cung cấp thông tin về số lượng dự đoán đúng và sai của mô hình trên từng lớp, giúp bạn hiểu rõ hơn về các lỗi của mô hình. Confusion Matrix bao gồm các thành phần sau:
- True Positives (TP): Số mẫu được dự đoán đúng thuộc lớp dương tính.
- False Positives (FP): Số mẫu được dự đoán là dương tính nhưng thực tế thuộc lớp âm tính.
- True Negatives (TN): Số mẫu được dự đoán đúng thuộc lớp âm tính.
- False Negatives (FN): Số mẫu được dự đoán là âm tính nhưng thực tế thuộc lớp dương tính.
Confusion Matrix bạn có thể tính toán các chỉ số như Precision, Recall, và F1-score, những chỉ số này sẽ giúp đánh giá mô hình tốt hơn trong trường hợp dữ liệu mất cân bằng.
3.2. Precision và Recall
Precision và Recall là hai chỉ số đánh giá quan trọng, đặc biệt khi dữ liệu bị mất cân bằng.
- Precision: Được tính bằng tỷ lệ số mẫu dương tính thực sự trong tổng số mẫu được dự đoán là dương tính. Precision đặc biệt quan trọng trong các bài toán mà việc dự đoán sai lớp dương tính (False Positives) có thể gây ra hậu quả nghiêm trọng.
Công thức:
\[ Precision = \frac{TP}{TP + FP} \]
- Recall (Sensitivity, True Positive Rate): Được tính bằng tỷ lệ số mẫu dương tính thực sự được mô hình dự đoán đúng so với tổng số mẫu dương tính trong dữ liệu. Recall rất quan trọng trong các bài toán mà việc bỏ sót các mẫu dương tính thực sự (False Negatives) là vấn đề lớn.
Công thức:
\[ Recall = \frac{TP}{TP + FN} \]
Trong một số tình huống, Precision và Recall có thể có mối quan hệ trái ngược, do đó cần phải cân nhắc giữa chúng khi đánh giá mô hình. Một cách tiếp cận là sử dụng F1-score, một chỉ số tổng hợp cả Precision và Recall.
3.3. F1-score
F1-score là trung bình hài hòa giữa Precision và Recall, giúp cân bằng giữa việc tối ưu hóa hai chỉ số này. Khi Precision và Recall có giá trị chênh lệch lớn, F1-score là chỉ số hữu ích để cung cấp một cái nhìn tổng quát hơn về hiệu suất của mô hình.
- F1-score:
Công thức:
\[ F1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} \]
F1-score đặc biệt hữu ích trong các bài toán mà cả Precision và Recall đều quan trọng, và chúng ta cần một chỉ số duy nhất để so sánh các mô hình hoặc điều chỉnh các siêu tham số.
3.4. ROC Curve và AUC (Area Under the Curve)
ROC Curve (Receiver Operating Characteristic Curve) và AUC (Area Under the Curve) là các công cụ đánh giá khác được sử dụng rộng rãi trong các bài toán phân loại nhị phân, đặc biệt khi dữ liệu mất cân bằng. ROC Curve là đồ thị thể hiện mối quan hệ giữa True Positive Rate (TPR) và False Positive Rate (FPR) ở các ngưỡng phân loại khác nhau.
- True Positive Rate (TPR): Còn được gọi là Recall, đo lường tỷ lệ các mẫu dương tính thực sự được dự đoán đúng.
Công thức:
\[ TPR = \frac{TP}{TP + FN} \]
- False Positive Rate (FPR): Đo lường tỷ lệ các mẫu âm tính thực sự nhưng được dự đoán sai là dương tính.
Công thức:
\[ FPR = \frac{FP}{FP + TN} \]
ROC Curve giúp bạn đánh giá khả năng phân biệt giữa các lớp của mô hình ở nhiều ngưỡng khác nhau. AUC, diện tích dưới đường cong ROC, là một giá trị duy nhất tóm tắt hiệu suất của mô hình; AUC càng gần 1, mô hình càng tốt. AUC là chỉ số đặc biệt hữu ích khi làm việc với Imbalanced Dataset vì nó không phụ thuộc vào tỷ lệ giữa các lớp.
3.5. Precision-Recall Curve
Precision-Recall Curve là một công cụ khác giúp đánh giá mô hình khi dữ liệu mất cân bằng. Đây là đồ thị thể hiện mối quan hệ giữa Precision và Recall ở các ngưỡng khác nhau. Khi dữ liệu bị mất cân bằng nghiêm trọng (ví dụ: khi một lớp rất hiếm), Precision-Recall Curve thường là một công cụ đánh giá tốt hơn so với ROC Curve.
Một cách để tóm tắt hiệu suất của mô hình từ Precision-Recall Curve là tính Average Precision (AP), tương tự như AUC nhưng áp dụng cho Precision-Recall Curve. AP cao thể hiện mô hình có khả năng giữ Precision cao đồng thời tăng Recall.
4. Giải pháp cho vấn đề Imbalanced Dataset
Để giải quyết vấn đề Imbalanced Dataset, có nhiều phương pháp khác nhau được áp dụng trong thực tế. Dưới đây là một số giải pháp phổ biến.
4.1. Resampling
Resampling là một kỹ thuật phổ biến để đối phó với dữ liệu mất cân bằng. Có hai loại Resampling chính:
Over-sampling
Tăng số lượng mẫu thuộc lớp chiếm thiểu số bằng cách sao chép các mẫu hiện có hoặc tạo ra các mẫu mới sử dụng các kỹ thuật như SMOTE (Synthetic Minority Over-sampling Technique). Điều này giúp cân bằng lại tập dữ liệu bằng cách tăng tỷ lệ mẫu thuộc lớp thiểu số.
Under-sampling
Giảm số lượng mẫu thuộc lớp chiếm đa số bằng cách loại bỏ một số mẫu để cân bằng lại với lớp thiểu số. Tuy nhiên, điều này có thể dẫn đến mất thông tin quan trọng.
Dưới đây là ví dụ về sử dụng SMOTE trong PyTorch:
from imblearn.over_sampling import SMOTE
import torch
from torch.utils.data import DataLoader, TensorDataset
# Giả sử chúng ta có dữ liệu X và nhãn y
X = torch.rand((1000, 20)) # 1000 mẫu, 20 đặc trưng
y = torch.cat((torch.zeros(950), torch.ones(50))) # Lớp 0: 950, Lớp 1: 50
# Sử dụng SMOTE để over-sample lớp thiểu số
smote = SMOTE(sampling_strategy='auto')
X_resampled, y_resampled = smote.fit_resample(X.numpy(), y.numpy())
# Chuyển đổi trở lại Tensor
X_resampled = torch.tensor(X_resampled, dtype=torch.float32)
y_resampled = torch.tensor(y_resampled, dtype=torch.long)
# Tạo DataLoader để huấn luyện mô hình
dataset = TensorDataset(X_resampled, y_resampled)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
4.2. Sử dụng các thuật toán nhạy cảm với Imbalanced Dataset
Một số thuật toán Machine Learning có khả năng xử lý tốt với dữ liệu mất cân bằng, chẳng hạn như:
Tree-based methods
Các phương pháp dựa trên cây quyết định như Random Forest hay Gradient Boosting thường phân tách các lớp một cách hiệu quả hơn khi đối mặt với dữ liệu mất cân bằng. Những thuật toán này có thể tìm ra những đặc trưng quan trọng giúp phân biệt giữa các lớp ngay cả khi dữ liệu bị mất cân bằng.
Ensemble methods
Các phương pháp kết hợp nhiều mô hình như Bagging và Boosting có thể cải thiện hiệu suất trên dữ liệu mất cân bằng bằng cách tập trung vào các mẫu khó phân loại, đặc biệt là mẫu thuộc lớp thiểu số.
4.3. Thay đổi trọng số (Cost-sensitive Learning)
Thay đổi trọng số là một phương pháp khác để xử lý dữ liệu mất cân bằng. Trong phương pháp này, các lớp thiểu số được gán trọng số lớn hơn trong hàm mất mát (loss function) để mô hình chú ý hơn đến các lớp thiểu số trong quá trình huấn luyện. Điều này giúp cân bằng lại tác động của các lớp thiểu số và lớp chiếm đa số trong việc tối ưu hóa mô hình. Phương pháp này đặc biệt hữu ích khi không muốn thay đổi số lượng mẫu trong tập dữ liệu (như trong các phương pháp resampling).
Ví dụ về thay đổi trọng số trong PyTorch
Trong PyTorch, bạn có thể dễ dàng áp dụng trọng số lớp trong hàm mất mát như sau:
import torch
import torch.nn as nn
import torch.optim as optim
# Giả sử chúng ta có dữ liệu đầu vào X và nhãn y
X = torch.rand((1000, 20)) # 1000 mẫu, 20 đặc trưng
y = torch.cat((torch.zeros(950), torch.ones(50))) # Lớp 0: 950, Lớp 1: 50
# Định nghĩa mô hình đơn giản
model = nn.Sequential(
nn.Linear(20, 64),
nn.ReLU(),
nn.Linear(64, 2)
)
# Trọng số của các lớp
class_weights = torch.tensor([1.0, 19.0]) # Trọng số lớn hơn cho lớp thiểu số
# Định nghĩa hàm mất mát với trọng số
criterion = nn.CrossEntropyLoss(weight=class_weights)
# Khởi tạo optimizer
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Huấn luyện mô hình (ví dụ đơn giản)
for epoch in range(10):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y.long())
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
Trong ví dụ trên, trọng số lớn hơn được gán cho lớp chiếm thiểu số, làm cho mô hình “quan tâm” hơn đến việc dự đoán chính xác các mẫu của lớp này.
4.4. Sử dụng phương pháp đánh giá thích hợp
Khi đánh giá mô hình trên tập dữ liệu mất cân bằng, việc sử dụng các chỉ số đánh giá như Accuracy không phải lúc nào cũng phản ánh đúng hiệu suất của mô hình. Thay vào đó, cần sử dụng các chỉ số như Precision, Recall, F1-score, và ROC-AUC.
Precision
Được sử dụng để đánh giá tỷ lệ dự đoán chính xác trong các dự đoán dương tính. Đặc biệt quan trọng trong các bài toán mà việc dự đoán sai lớp thiểu số có thể gây hậu quả nghiêm trọng, như chẩn đoán y tế.
Recall
Đo lường khả năng phát hiện tất cả các mẫu thuộc lớp thiểu số. Cao khi mô hình có khả năng phát hiện tất cả các trường hợp thuộc lớp thiểu số, dù cho có nhiều dự đoán sai.
F1-score
Trung bình hài hòa giữa Precision và Recall, mang lại một chỉ số cân bằng hơn khi hai chỉ số này có sự chênh lệch.
ROC-AUC
Chỉ số này đo lường khả năng của mô hình trong việc phân biệt giữa các lớp. Đường cong ROC biểu thị mối quan hệ giữa True Positive Rate (TPR) và False Positive Rate (FPR), và AUC thể hiện diện tích dưới đường cong này. Giá trị AUC càng gần 1, mô hình càng tốt.
4.5. Kỹ thuật Ensemble (Ensemble Techniques)
Các kỹ thuật Ensemble kết hợp nhiều mô hình khác nhau để tạo ra một mô hình mạnh mẽ hơn, có thể khắc phục được các nhược điểm của từng mô hình đơn lẻ. Các phương pháp Ensemble phổ biến bao gồm:
Bagging
Kỹ thuật này bao gồm việc huấn luyện nhiều mô hình độc lập trên các mẫu khác nhau của tập dữ liệu, sau đó kết hợp các kết quả dự đoán của chúng. Một ví dụ nổi bật là Random Forest, nơi nhiều cây quyết định được huấn luyện trên các tập con của dữ liệu và kết quả cuối cùng được xác định dựa trên bình chọn đa số.
Boosting
Khác với Bagging, Boosting huấn luyện các mô hình một cách tuần tự, trong đó mỗi mô hình mới được huấn luyện để khắc phục lỗi của mô hình trước đó. Gradient Boosting và AdaBoost là những ví dụ điển hình. Boosting thường có khả năng tốt hơn trong việc phát hiện các mẫu thiểu số do sự nhấn mạnh vào các mẫu khó phân loại.
Stacking
Trong Stacking, các mô hình khác nhau được huấn luyện trên cùng một tập dữ liệu, và các dự đoán của chúng được sử dụng như đầu vào cho một mô hình “meta-model” để tạo ra dự đoán cuối cùng. Kỹ thuật này có thể tạo ra những kết quả mạnh mẽ hơn bằng cách khai thác điểm mạnh của từng mô hình thành phần.
4.6. Data Augmentation
Data Augmentation là một kỹ thuật tạo ra các mẫu dữ liệu mới từ các mẫu dữ liệu hiện có bằng cách áp dụng các phép biến đổi như xoay, lật, hoặc thay đổi độ sáng, đặc biệt phổ biến trong các bài toán xử lý ảnh. Phương pháp này giúp tăng số lượng mẫu thuộc lớp thiểu số mà không cần thu thập thêm dữ liệu mới, từ đó giúp cân bằng tập dữ liệu và cải thiện hiệu suất của mô hình.
Ví dụ về Data Augmentation trong PyTorch
Ví dụ sau đây minh họa cách áp dụng Data Augmentation cho hình ảnh trong PyTorch:
import torch
from torchvision import transforms
from PIL import Image
# Định nghĩa các phép biến đổi
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2)
])
# Giả sử chúng ta có một hình ảnh đầu vào
img = Image.open('path/to/image.jpg')
# Áp dụng Data Augmentation
augmented_img = transform(img)
# Chuyển đổi hình ảnh thành tensor để sử dụng trong mô hình
augmented_tensor = transforms.ToTensor()(augmented_img)
Trong ví dụ này, các phép biến đổi như lật ngang, xoay, và điều chỉnh màu sắc được áp dụng để tạo ra các phiên bản mới của hình ảnh gốc, giúp tăng tính đa dạng của dữ liệu huấn luyện.
5. Kết luận
Imbalanced Dataset là một thách thức lớn trong Machine Learning, nhưng không phải là một trở ngại không thể vượt qua. Bằng cách áp dụng các kỹ thuật phù hợp như Resampling, thay đổi trọng số, sử dụng các thuật toán nhạy cảm với dữ liệu mất cân bằng, và kết hợp nhiều phương pháp, chúng ta có thể cải thiện đáng kể hiệu suất của mô hình.
Quan trọng hơn cả là việc hiểu rõ về bản chất của vấn đề và lựa chọn những phương pháp phù hợp với đặc thù của từng bài toán cụ thể. Điều này sẽ giúp bạn xây dựng những mô hình không chỉ chính xác mà còn đủ linh hoạt để xử lý dữ liệu thực tế, nơi mà dữ liệu mất cân bằng thường xuyên xuất hiện.