YOLOv8: Cách mạng hóa nhận diện đối tượng với hiệu suất vượt trội
1. Giới thiệu
YOLO v8 (You Only Look Once, phiên bản 8) là một mô hình phát hiện vật thể tiên tiến, sử dụng kiến trúc mạng nơ-ron sâu để xử lý hình ảnh và xác định các đối tượng trong thời gian thực. Kiến trúc của YOLO v8 có nhiều cải tiến so với các phiên bản trước đó, bao gồm việc sử dụng các khối mạng mạnh mẽ hơn, khả năng phân tích đa tỉ lệ, và cơ chế không cần anchor (anchor-free). YOLO v8 được đánh giá là một trong những phiên bản tiên tiến và mạnh mẽ nhất cho bài toán nhận diện hình ảnh.
2. Kiến trúc mạng
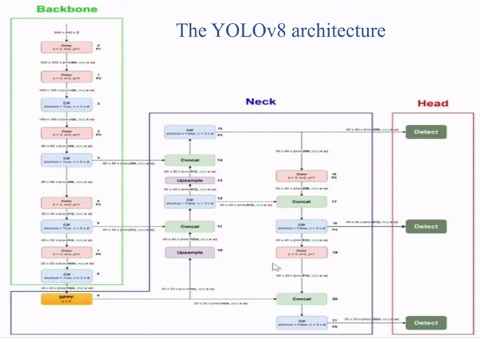
Kiến trúc YOLO v8 chia thành ba thành phần chính: Backbone, Neck, và Head.
- Backbone: Đây là phần đầu của mạng, có nhiệm vụ trích xuất các đặc trưng (features) từ ảnh đầu vào.
- Neck: Phần này thực hiện chức năng tổng hợp các đặc trưng từ nhiều mức độ phân giải khác nhau để tăng cường khả năng nhận diện.
- Head: Phần cuối cùng của mạng, có nhiệm vụ dự đoán vị trí và lớp của các vật thể trong ảnh.
YOLO v8 vẫn giữ nguyên triết lý thiết kế một lần xem (one-stage detection), tức là toàn bộ quá trình dự đoán bounding box và nhận diện được thực hiện trong một bước duy nhất.
2.1. Backbone: CSPNet
Backbone của YOLO v8 sử dụng kiến trúc CSPNet (Cross Stage Partial Network), một phương pháp tối ưu hoá việc trích xuất đặc trưng với hiệu suất cao. CSPNet chia mạng nơ-ron thành hai phần chính, một phần giữ nguyên dòng thông tin, và một phần thực hiện các phép biến đổi sâu hơn để giảm thiểu độ trùng lặp thông tin. Điều này giúp giảm thiểu lượng tính toán, đồng thời duy trì độ chính xác cao.
Kiến trúc của CSPNet có thể được biểu diễn như sau:
\[F_{\text{out}} = \text{CSP}(F_{\text{in}}) = F_{\text{in}}^{1} + G(F_{\text{in}}^{2})\]
Trong đó:
- \(F_{\text{in}}\) là đầu vào của một khối CSPNet.
- \(F_{\text{in}}^{1}\) là dòng thông tin không thay đổi.
- \(G(F_{\text{in}}^{2})\) là phần áp dụng các phép biến đổi (như convolution) lên dòng thông tin thứ hai.
- \(F_{\text{out}}\) là đầu ra sau khi kết hợp hai dòng.
Nhờ việc giảm thiểu độ phức tạp trong tính toán, CSPNet giúp YOLO v8 xử lý nhanh hơn nhưng vẫn giữ được hiệu suất cao.
2.2. Neck: PANet và FPN
Trong YOLO v8, Neck là thành phần kết hợp các đặc trưng từ các mức phân giải khác nhau để tối ưu việc phát hiện vật thể ở các kích thước khác nhau. YOLO v8 sử dụng hai công nghệ chính trong Neck:
FPN (Feature Pyramid Network)
FPN giúp tổng hợp thông tin từ các tầng có độ phân giải khác nhau trong backbone, giúp mô hình có thể nhận diện các vật thể lớn nhỏ đa dạng.
PANet (Path Aggregation Network)
PANet tối ưu hoá việc tổng hợp đặc trưng từ nhiều tầng khác nhau, tăng cường khả năng phát hiện vật thể nhỏ và mờ nhạt trong ảnh.
FPN và PANet giúp YOLO v8 xử lý được nhiều kích thước và kiểu vật thể khác nhau, từ đó nâng cao độ chính xác trong các bài toán nhận diện phức tạp.
2.3. Head: Anchor-free Prediction
Khác với các phiên bản trước đây, YOLO v8 áp dụng cơ chế Anchor-free để dự đoán bounding box. Điều này có nghĩa là thay vì cần xác định các anchors trước (các khung tham chiếu), YOLO v8 trực tiếp dự đoán vị trí và kích thước của các bounding box dựa trên các đặc trưng từ Neck.
Cơ chế anchor-free giúp giảm bớt độ phức tạp, giảm lượng tính toán và cải thiện tính chính xác trong việc phát hiện vật thể, đặc biệt là với các vật thể có hình dạng không đồng nhất hoặc ở các vị trí bất thường.
3. Hoạt động
3.1. Bounding box
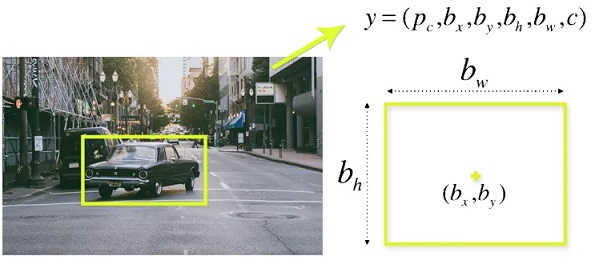
YOLO v8 sử dụng một hàm hồi quy để dự đoán các bounding box từ các đặc trưng đã tổng hợp. Giả sử \(x_c, y_c\) là toạ độ trung tâm của bounding box, và \(w, h\) là chiều rộng và chiều cao, ta có:
\[\begin{aligned}x_c &= \sigma(t_x) + c_x \\y_c &= \sigma(t_y) + c_y \\w &= p_w e^{t_w} \\h &= p_h e^{t_h}\end{aligned}\]
Trong đó:
- \(\sigma\) là hàm sigmoid để đảm bảo giá trị trong khoảng [0, 1].
- \(t_x, t_y, t_w, t_h\) là các giá trị mà mạng dự đoán.
- \(c_x, c_y\) là các toạ độ của ô lưới hiện tại.
- \(p_w, p_h\) là các giá trị tham chiếu về kích thước.
3.2. Loss Function
Loss function của YOLO v8 được tối ưu để cân bằng giữa ba thành phần: localization loss, Objectness loss và classification loss. Công thức tổng quát có dạng:
\[\mathcal{L} = \lambda_{box} \cdot \mathcal{L}_{box} + \lambda_{obj} \cdot \mathcal{L}_{obj} + \lambda_{cls} \cdot \mathcal{L}_{cls}\]
Trong đó:
- \( \mathcal{L}_{box} \): Box Loss – đo độ chính xác của vị trí và kích thước bounding box. Sử dụng CIoU Loss hoặc GIoU Loss để đánh giá độ chính xác của vị trí và kích thước hộp bao quanh đối tượng. Những loss này giúp mô hình học cách khớp chính xác bounding box với đối tượng cần phát hiện.
- \( \mathcal{L}_{obj} \): Objectness Loss – để đánh giá xác suất có đối tượng trong mỗi ô lưới. Thành phần này được thiết kế để phân biệt giữa các ô lưới chứa đối tượng và các ô không chứa đối tượng, giúp mô hình dự đoán tốt hơn các đối tượng trong ảnh.
- \( \mathcal{L}_{cls} \): Classification Loss – đo độ chính xác của việc phân loại đối tượng. Thường sử dụng Binary Cross-Entropy (BCE) Loss hoặc các hàm mất mát khác như Focal Loss để đánh giá khả năng mô hình phân loại đúng các đối tượng trong ảnh.
- \( \lambda_{box}, \lambda_{obj}, \lambda_{cls} \): Các hệ số điều chỉnh trọng số cho từng thành phần loss.
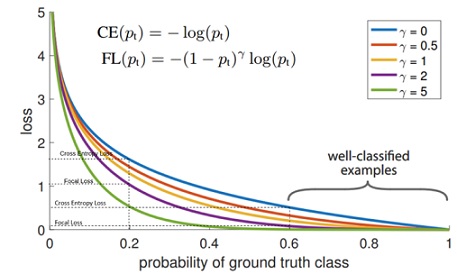
Focal Loss
Focal Loss là một biến thể của hàm mất mát Cross-Entropy được áp dụng để giải quyết vấn đề mất cân bằng dữ liệu. Trong các bài toán nhận diện vật thể, có rất nhiều ô lưới không chứa vật thể (background). Focal Loss giảm thiểu ảnh hưởng của các ô lưới này, cho phép mô hình tập trung nhiều hơn vào các ô chứa vật thể.
Công thức của Focal Loss là:
\[FL(p_t) = -\alpha_t (1 – p_t)^\gamma \log(p_t)\]
Trong đó:
- \(p_t\) là xác suất dự đoán đúng của mô hình cho một lớp nhất định (lớp đối tượng hoặc lớp nền).
- \(\alpha_t\) là hệ số cân bằng giữa các lớp. Nó giúp giảm tác động của các lớp phổ biến hơn (như nền) so với các lớp ít xuất hiện.
- 𝛾 là tham số điều chỉnh, được gọi là focusing parameter, điều chỉnh mức độ tập trung của Focal Loss. Nếu \( \gamma = 0 \), Focal Loss trở thành BCE Loss. Khi \( \gamma \) tăng, Focal Loss sẽ giảm trọng số của các mẫu dễ (với giá trị \( p_t \) lớn) và tăng trọng số của các mẫu khó (với \( p_t \) nhỏ).
3.3. Anchor-free Detection
YOLOv8 chuyển sang cách tiếp cận Anchor-Free, trong đó thay vì dựa vào các hộp anchor với kích thước cố định, mô hình sẽ trực tiếp dự đoán tọa độ của các đối tượng dựa trên đặc trưng không gian trong ảnh. Điều này giúp cải thiện khả năng dự đoán đối với các đối tượng có hình dạng và kích thước đa dạng mà không cần thiết lập anchor trước.
Các bước chính trong cách tiếp cận anchor-free gồm:
- Direct Localization: Mô hình trực tiếp dự đoán tọa độ của các điểm trung tâm của đối tượng trong ảnh. Thay vì dự đoán offset (độ lệch) dựa trên anchor boxes, mô hình sẽ dự đoán khoảng cách từ các điểm đặc trưng đến các cạnh của bounding box (l/r/t/b: left, right, top, bottom).
- Feature Points: YOLOv8 xác định các điểm đặc trưng quan trọng trong ảnh (keypoints) mà tại đó nó dự đoán được sự hiện diện của các đối tượng. Những điểm đặc trưng này cho phép mạng tập trung vào các vùng quan trọng hơn trong ảnh để dự đoán chính xác vị trí đối tượng mà không cần phải chia ảnh thành lưới cứng nhắc như trước đây.
3.4. Non-Maximum Suppression (NMS)
Non-Maximum Suppression (NMS) là một thuật toán quan trọng được sử dụng trong YOLOv8 (và nhiều mô hình phát hiện đối tượng khác) để xử lý các dự đoán và loại bỏ các bounding box trùng lặp nhằm giữ lại kết quả chính xác nhất.
4. Các phiên bản của YOLOv8
YOLOv8 đã kế thừa những cải tiến từ các phiên bản trước đồng thời tích hợp thêm các tính năng mới để tối ưu hóa cả độ chính xác và tốc độ. YOLOv8 bao gồm 5 phiên bản là: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x.
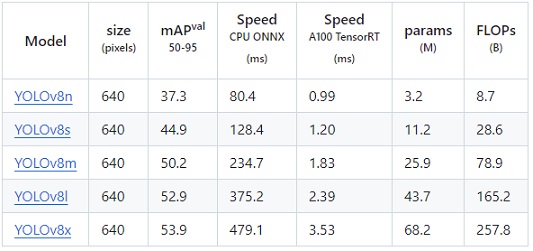
YOLOv8n (nano)
- Kích thước: Nhỏ nhất trong các phiên bản YOLOv8.
- Tốc độ: Cực kỳ nhanh, phù hợp cho các ứng dụng trên thiết bị di động và nhúng có tài nguyên hạn chế.
- Độ chính xác: Có độ chính xác thấp hơn so với các phiên bản lớn hơn, nhưng vẫn đủ cho các tác vụ yêu cầu xử lý nhanh.
YOLOv8s (small)
- Kích thước: Lớn hơn YOLOv8n nhưng vẫn nhỏ gọn.
- Tốc độ: Nhanh hơn so với các phiên bản lớn hơn nhưng chậm hơn YOLOv8n.
- Độ chính xác: Cân bằng tốt giữa tốc độ và độ chính xác, phù hợp cho các bài toán phát hiện đối tượng ở mức độ trung bình.
YOLOv8m (medium)
- Kích thước: Tăng dần về mặt số lượng tham số so với YOLOv8s.
- Tốc độ: Chậm hơn YOLOv8n và YOLOv8s, nhưng vẫn nhanh so với các mô hình phát hiện đối tượng khác.
- Độ chính xác: Độ chính xác cao hơn các phiên bản nhỏ hơn, đặc biệt trong các bài toán phức tạp và dữ liệu lớn.
YOLOv8l (large)
- Kích thước: Lớn hơn YOLOv8m, với nhiều tham số hơn.
- Tốc độ: Chậm hơn so với YOLOv8m, nhưng vẫn có thể sử dụng cho các hệ thống phát hiện đối tượng gần thời gian thực.
- Độ chính xác: Độ chính xác cao, phù hợp cho các bài toán phát hiện đối tượng phức tạp và đòi hỏi độ chính xác cao.
YOLOv8x (extra large)
- Kích thước: Phiên bản lớn nhất của YOLOv8, với số lượng tham số và layers nhiều nhất.
- Tốc độ: Chậm nhất trong các phiên bản YOLOv8, nhưng vẫn tương đối nhanh khi so sánh với các mô hình lớn khác.
- Độ chính xác: Cao nhất trong các phiên bản YOLOv8, phù hợp cho các bài toán phát hiện đối tượng phức tạp với độ chính xác cao.
5. Ứng dụng thực tế
Nhờ sử tối ưu hóa về tốc độ và độ chính xác, YOLOv8 được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau.
5.1. Giám sát an ninh và phát hiện bất thường
YOLOv8 được sử dụng trong các hệ thống giám sát video và an ninh để phát hiện và theo dõi đối tượng như con người, phương tiện, hoặc các hành vi bất thường. Các hệ thống giám sát hiện đại có thể sử dụng YOLOv8 để:
- Nhận diện người xâm nhập: Hệ thống phát hiện và cảnh báo khi có người đi vào khu vực bị giới hạn hoặc cấm.
- Phát hiện bạo lực hoặc hành vi nguy hiểm: Nhờ tốc độ phát hiện nhanh và độ chính xác cao, YOLOv8 có thể phân tích hành vi trong video để phát hiện các hoạt động bất thường như đánh nhau, chạy trốn, hoặc hành vi phá hoại.
- Theo dõi phương tiện giao thông: Các hệ thống giám sát giao thông sử dụng YOLOv8 để phát hiện và theo dõi các phương tiện vi phạm, từ đó hỗ trợ kiểm soát giao thông và thực thi luật lệ.
5.2. Xe tự hành và robot
YOLOv8 đóng vai trò quan trọng trong việc phát hiện và tránh các vật thể trên đường đi của các phương tiện tự lái và robot. Các ứng dụng chính bao gồm:
- Nhận diện và tránh va chạm: Xe tự hành sử dụng YOLOv8 để phát hiện các chướng ngại vật như xe khác, người đi bộ, và vật cản trên đường, từ đó điều chỉnh đường đi để tránh va chạm.
- Tìm kiếm và cứu nạn: Robot có thể được trang bị YOLOv8 để phát hiện người bị nạn trong các khu vực nguy hiểm, chẳng hạn như sau thảm họa tự nhiên hoặc tai nạn công nghiệp.
5.3. Phân tích y tế
Trong lĩnh vực y tế, YOLOv8 được sử dụng trong việc phân tích hình ảnh và phát hiện các dấu hiệu bất thường, từ đó hỗ trợ bác sĩ trong việc chẩn đoán bệnh. Các ứng dụng tiêu biểu bao gồm:
- Phân tích hình ảnh y khoa: YOLOv8 có thể giúp phát hiện khối u, polyp, hoặc các dấu hiệu bệnh lý khác trên ảnh chụp X-quang, CT hoặc MRI.
- Theo dõi tình trạng bệnh nhân: Mô hình có thể giúp theo dõi tình trạng sức khỏe của bệnh nhân qua hình ảnh video, đặc biệt trong các trường hợp cần giám sát liên tục.
5.4. Thương mại điện tử và bán lẻ
Trong các hệ thống bán lẻ, YOLOv8 được sử dụng để cải thiện trải nghiệm mua sắm và tối ưu hóa quy trình bán hàng:
- Phân tích hành vi người mua: Hệ thống camera sử dụng YOLOv8 để theo dõi hành vi người mua trong cửa hàng, từ đó đưa ra các gợi ý cá nhân hóa hoặc tối ưu hóa vị trí trưng bày sản phẩm.
- Kiểm tra hàng hóa tự động: YOLOv8 có thể tự động phát hiện và kiểm tra hàng hóa trong kho hoặc trên kệ hàng, hỗ trợ quản lý tồn kho hiệu quả hơn.
5.5. Nông nghiệp thông minh
Trong lĩnh vực nông nghiệp, YOLOv8 được sử dụng trong các hệ thống giám sát cây trồng và vật nuôi:
- Phát hiện sâu bệnh và cây trồng hư hại: Drone hoặc robot sử dụng YOLOv8 để phát hiện các dấu hiệu sâu bệnh, cây trồng bị hư hại, từ đó giúp nông dân quản lý và chăm sóc mùa màng tốt hơn.
- Theo dõi vật nuôi: Hệ thống sử dụng YOLOv8 để theo dõi trạng thái của vật nuôi trong nông trại, phát hiện sớm các dấu hiệu bệnh hoặc tình trạng bất thường.
5.6. Phân tích video thể thao
YOLOv8 được ứng dụng trong các hệ thống phân tích video thể thao để:
- Theo dõi cầu thủ và bóng: Hệ thống phát hiện và theo dõi chuyển động của cầu thủ và bóng trên sân, từ đó cung cấp dữ liệu phân tích cho các huấn luyện viên và người hâm mộ.
- Phát hiện các tình huống quan trọng: Mô hình có thể phát hiện các tình huống ghi bàn, phạm lỗi, hoặc các tình huống nổi bật khác trong trận đấu.
6. Kết luận
Với khả năng phát hiện đối tượng nhanh chóng và chính xác, YOLOv8 là lựa chọn hàng đầu cho các bài toán phát hiện đối tượng trong thời gian thực. Những cải tiến như kiến trúc anchor-free, sử dụng Focal Loss, và tối ưu hóa NMS giúp nâng cao cả độ chính xác lẫn hiệu suất, làm cho YOLOv8 phù hợp với nhiều ứng dụng thực tế trong các lĩnh vực như giám sát an ninh, xe tự hành, y tế, và nông nghiệp thông minh. Với sự linh hoạt và khả năng tùy chỉnh, YOLOv8 không chỉ cải thiện hiệu suất phát hiện mà còn giúp giảm chi phí tính toán, mở rộng phạm vi ứng dụng cho các hệ thống AI tiên tiến..