AlexNet: Bước đột phá trong trí tuệ nhân tạo
1. Giới Thiệu
Trong thập kỷ vừa qua, trí tuệ nhân tạo (AI) và học sâu (deep learning) đã trải qua những tiến bộ đáng kể, phần lớn nhờ vào những đột phá trong việc xử lý dữ liệu và huấn luyện mô hình. Một trong những bước ngoặt quan trọng nhất trong lịch sử phát triển của học sâu chính là sự ra đời của AlexNet, một mạng nơ-ron tích chập (Convolutional Neural Network – CNN) đã giành chiến thắng trong cuộc thi ImageNet Large Scale Visual Recognition Challenge (ILSVRC) vào năm 2012.

AlexNet không chỉ làm thay đổi cách nhìn nhận của cộng đồng khoa học về khả năng của mạng nơ-ron mà còn tạo ra một làn sóng mới trong nghiên cứu và ứng dụng AI trên toàn thế giới.
Trước khi AlexNet xuất hiện, lĩnh vực nhận dạng hình ảnh đã có một lịch sử lâu đời, với nhiều phương pháp khác nhau được đề xuất nhằm cải thiện độ chính xác trong các bài toán nhận dạng. Tuy nhiên, những phương pháp này thường không thể đạt được hiệu quả cao trên các tập dữ liệu lớn và phức tạp như ImageNet, một cơ sở dữ liệu gồm hơn 15 triệu hình ảnh thuộc 22.000 danh mục khác nhau.
Các phương pháp truyền thống thường dựa vào việc trích xuất đặc trưng thủ công (hand-crafted features) như SIFT (Scale-Invariant Feature Transform) hay HOG (Histogram of Oriented Gradients), kết hợp với các bộ phân loại như SVM (Support Vector Machine). Mặc dù có những thành công nhất định, các phương pháp này vẫn gặp nhiều hạn chế về khả năng tổng quát hóa và độ chính xác khi áp dụng trên các bộ dữ liệu lớn.

Cuộc cách mạng huấn luyện với GPU
Một yếu tố quan trọng khác góp phần vào sự thành công của AlexNet là việc sử dụng GPU trong quá trình huấn luyện. Trước AlexNet, các mô hình AI thường được huấn luyện trên CPU, nhưng CPU không đủ mạnh để xử lý khối lượng tính toán khổng lồ của các mạng nơ-ron sâu. AlexNet là một trong những mạng đầu tiên được huấn luyện trên GPU, cụ thể là NVIDIA GTX 580, giúp tăng tốc độ huấn luyện lên rất nhiều lần.
GPU có khả năng xử lý song song hàng ngàn tác vụ, điều này rất phù hợp với các phép tính ma trận và phép nhân-tenor, vốn là cốt lõi của các phép tính trong mạng nơ-ron. Việc sử dụng GPU không chỉ giảm thời gian huấn luyện từ nhiều tuần xuống còn vài ngày mà còn mở ra khả năng áp dụng các mạng nơ-ron sâu trong thực tế, giúp tăng tốc độ phát triển của các ứng dụng AI.
2. Cấu trúc

AlexNet bao gồm 8 lớp nơ-ron chính, trong đó có 5 lớp tích chập (convolutional layers) và 3 lớp kết nối đầy đủ (fully connected layers). Ngoài ra, nó còn sử dụng một số kỹ thuật tiên tiến để cải thiện hiệu suất và độ chính xác, như ReLU, Local Response Normalization, Max-Pooling, và Dropout.
2.1. Lớp tích chập 1
- Đầu vào: Hình ảnh RGB kích thước 224x224x3.
- Bộ lọc: 96 bộ lọc với kích thước 11×11 và stride là 4.
- Đặc điểm nổi bật: Lớp tích chập đầu tiên này đóng vai trò rất quan trọng trong việc phát hiện các đặc trưng cơ bản như cạnh, góc và các mẫu đơn giản từ hình ảnh đầu vào.
- Max-Pooling: Sau lớp tích chập này, một bước Max-Pooling với kích thước 3×3 và stride 2 được áp dụng để giảm kích thước không gian và tăng độ bất biến của mô hình đối với các biến đổi nhỏ trong hình ảnh.
2.2. Lớp tích chập 2
- Bộ lọc: 256 bộ lọc với kích thước 5×5.
- Local Response Normalization (LRN): Kỹ thuật này giúp tăng độ ổn định của việc học bằng cách chuẩn hóa các giá trị đầu ra của lớp tích chập theo không gian cục bộ, giảm sự khác biệt giữa các giá trị kích hoạt lớn và nhỏ.
- Max-Pooling: Một bước Max-Pooling nữa được áp dụng sau lớp tích chập này để tiếp tục giảm kích thước không gian.
2.3. Lớp tích chập 3
- Bộ lọc: 384 bộ lọc với kích thước 3×3.
- Vai trò: Lớp này giúp trích xuất các đặc trưng phức tạp hơn từ hình ảnh, xây dựng trên các đặc trưng cơ bản được phát hiện từ các lớp trước đó.
2.4. Lớp tích chập 4 và 5
- Bộ lọc: Lớp 4 có 384 bộ lọc và lớp 5 có 256 bộ lọc, đều có kích thước 3×3.
- Kết hợp các đặc trưng: Hai lớp này tiếp tục xây dựng các đặc trưng ngày càng phức tạp hơn, chuẩn bị cho việc phân loại ở các lớp fully connected tiếp theo.
- Lớp kết nối đầy đủ 1 và 2:
- Số nơ-ron: Mỗi lớp có 4096 nơ-ron.
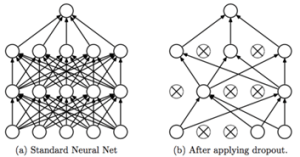
- Dropout: Để ngăn chặn overfitting, AlexNet sử dụng kỹ thuật Dropout với tỷ lệ 50% tại các lớp fully connected. Điều này có nghĩa là trong quá trình huấn luyện, mỗi nơ-ron có 50% khả năng bị “tắt” (không kích hoạt) ngẫu nhiên, giúp mô hình trở nên ít phụ thuộc vào các đặc trưng cụ thể và tăng khả năng tổng quát hóa.
- Lớp kết nối đầy đủ 3 (lớp đầu ra):
- Số nơ-ron: 1000 nơ-ron tương ứng với 1000 lớp của ILSVRC.
- Softmax: Lớp này sử dụng hàm Softmax để tính toán xác suất của mỗi lớp, giúp xác định hình ảnh thuộc về lớp nào với độ tin cậy cao nhất.
2.5. Kỹ thuật tối ưu hóa
AlexNet không chỉ nổi bật bởi cấu trúc mạng mà còn bởi các kỹ thuật tối ưu hóa được sử dụng trong quá trình huấn luyện:
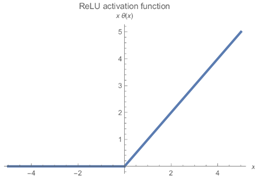
- Hàm kích hoạt ReLU (Rectified Linear Unit): Đây là một trong những yếu tố quan trọng giúp AlexNet thành công. ReLU có đặc điểm là tuyến tính ở phần dương và bằng 0 ở phần âm, giúp mạng học nhanh hơn rất nhiều so với các hàm kích hoạt truyền thống như sigmoid hay tanh. Điều này là do ReLU không bị vấn đề gradient biến mất (vanishing gradient), một vấn đề thường gặp khi huấn luyện các mạng sâu.
- Local Response Normalization (LRN): Kỹ thuật này giúp tăng cường sự cạnh tranh giữa các nơ-ron hoạt động mạnh, làm nổi bật các nơ-ron có phản ứng mạnh mẽ hơn so với các nơ-ron lân cận. Điều này giúp mô hình học được các đặc trưng nổi bật và đáng chú ý hơn từ hình ảnh.
- Dropout: Như đã đề cập, Dropout là một kỹ thuật ngăn chặn overfitting bằng cách “tắt” ngẫu nhiên các nơ-ron trong quá trình huấn luyện. Đây là một kỹ thuật rất hiệu quả và đã được áp dụng rộng rãi trong nhiều mô hình học sâu sau này.
3. Ứng dụng thực tế
AlexNet, một trong những mạng nơ-ron đầu tiên đạt được thành công lớn trong lĩnh vực trí tuệ nhân tạo, đã tạo ra bước đột phá trong việc nhận diện hình ảnh và xử lý dữ liệu.

Dưới đây là những ứng dụng thực tế nổi bật của AlexNet:
3.1. Nhận diện hình ảnh và phân loại ảnh
- AlexNet được sử dụng để phân loại các loại hình ảnh trong cơ sở dữ liệu lớn, chẳng hạn như phân biệt chó, mèo, hoặc các loại hoa khác nhau.
Ví dụ: Trong lĩnh vực thương mại điện tử, AlexNet giúp phân loại và gợi ý các sản phẩm dựa trên hình ảnh, nâng cao trải nghiệm mua sắm.
3.2. Phát hiện đối tượng (Object Detection):
- Mặc dù AlexNet chủ yếu được thiết kế cho phân loại hình ảnh, nhưng nó cũng được dùng làm nền tảng cho các thuật toán phát hiện đối tượng.
- Ví dụ: AlexNet hỗ trợ phân tích hình ảnh trong camera giám sát để phát hiện người hoặc phương tiện trong thời gian thực.
3.3. Ứng dụng trong y tế
- AlexNet được sử dụng để phân tích hình ảnh y khoa, chẳng hạn như ảnh X-quang hoặc MRI, để phát hiện các bất thường như khối u hoặc tổn thương.
- Ví dụ: Hỗ trợ bác sĩ chẩn đoán ung thư vú qua hình ảnh quét mô tuyến vú.
3.3. Công nghiệp xe tự hành
- AlexNet hỗ trợ các hệ thống nhận diện biển báo giao thông, phân tích hình ảnh từ camera trên xe để đưa ra các quyết định như dừng, rẽ hoặc giảm tốc độ.
3.4. Sáng tạo nghệ thuật
- AlexNet góp phần vào các ứng dụng sáng tạo, chẳng hạn như phân tích và mô phỏng phong cách hội họa từ các bức tranh nổi tiếng để tạo ra hình ảnh mới.
4. Ảnh hưởng của AlexNet đến lĩnh vực trí tuệ nhân tạo
Thành công của AlexNet trong cuộc thi ILSVRC 2012 không chỉ là một chiến thắng đơn thuần mà còn có ý nghĩa sâu xa đối với lĩnh vực trí tuệ nhân tạo:
4.1. Sự bùng nổ của học sâu
Sau khi AlexNet chiến thắng ILSVRC 2012, học sâu đã trở thành một trong những lĩnh vực nghiên cứu chính trong AI. Các nhà nghiên cứu bắt đầu tập trung vào việc phát triển các mạng CNN sâu hơn, hiệu quả hơn, dẫn đến sự ra đời của nhiều mô hình nổi tiếng như VGGNet, GoogleNet, ResNet và nhiều mô hình khác.
4.2. Ứng dụng rộng rãi trong công nghiệp
Sau AlexNet, các mạng CNN đã được áp dụng rộng rãi trong nhiều lĩnh vực công nghiệp, từ nhận dạng hình ảnh, nhận diện khuôn mặt, lái xe tự động, đến chẩn đoán y khoa. Khả năng tự động học các đặc trưng từ dữ liệu đã mở ra những ứng dụng mới và cải thiện hiệu suất trong các hệ thống AI thực tế.
4.3. Động lực phát triển phần cứng
Sự thành công của AlexNet đã thúc đẩy sự phát triển của các công nghệ phần cứng, đặc biệt là GPU và các bộ xử lý tensor chuyên dụng như Tensor Processing Unit (TPU) của Google. Những tiến bộ trong phần cứng đã giúp đẩy nhanh tốc độ huấn luyện và triển khai các mô hình AI, làm cho chúng trở nên khả thi và hiệu quả hơn.
5. Kết luận
AlexNet không chỉ là một cột mốc quan trọng trong sự phát triển của học sâu mà còn là minh chứng rõ ràng về tiềm năng của mạng nơ-ron tích chập trong việc giải quyết các bài toán phức tạp.
Thành công của AlexNet đã mở ra một kỷ nguyên mới cho trí tuệ nhân tạo, dẫn đến sự ra đời của nhiều mô hình và công nghệ tiên tiến. Hơn một thập kỷ sau ngày ra mắt, những nguyên lý và kỹ thuật được giới thiệu bởi AlexNet vẫn tiếp tục ảnh hưởng sâu rộng đến các nghiên cứu và ứng dụng trong lĩnh vực AI, chứng minh giá trị và tầm nhìn của các nhà khoa học đã phát triển nó.