Cách dự đoán giá cổ phiếu hiệu quả bằng mô hình LSTM
1. Bài toán
Dự đoán giá cổ phiếu sử dụng dữ liệu lịch sử giá, nhằm ước tính giá cổ phiếu của ngày tiếp theo. Mục tiêu là phát triển mô hình học máy hiệu quả, dựa trên chuỗi thời gian về lịch sử giao dịch, để cung cấp dự đoán chính xác, hỗ trợ quyết định đầu tư.
2. Chuẩn bị môi trường và dữ liệu
2.1. Cấu trúc chương trình
Cấu trúc chương trình trong bài:
root@aicandy:/aicandy/projects/AIcandy_LSTM_Stock_iiyiedys# tree
.
├── AIcandy_LSTM_model_hdbhkibl.py
├── AIcandy_LSTM_train_emabpupv.py
├── history_price.csv
└── requirements.txt
0 directories, 4 files
root@aicandy:/aicandy/projects/AIcandy_LSTM_Stock_iiyiedys#2.2. Cài đặt môi trường
Sử dụng pip để cài đặt các thư viện cần thiết
pip install -r requirements.txt2.3. Dữ liệu
Dữ liệu sử dụng trong bài viết này là lịch sử giá cổ phiếu của ngân hàng ACB, được lưu trong file CSV với các cột thông tin: Ticker (mã cổ phiếu), DTYYYYMMDD (ngày giao dịch), OpenFixed (giá mở cửa), HighFixed (giá cao nhất), LowFixed (giá thấp nhất), CloseFixed (giá đóng cửa), Volume.
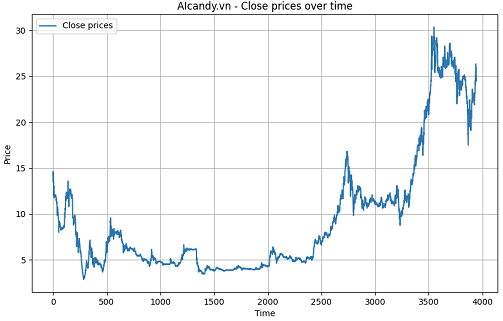
Trong bài, chúng ta sẽ tập trung sử dụng giá đóng cửa (CloseFixed ) làm đặc trưng để dự đoán giá đóng cửa của ngày tiếp theo. Biểu đồ giá theo thời gian như ảnh dưới:
Dưới đây là thông tin của 10 phiên giao dịch đầu tiên trong lịch sử giá:
Ticker DTYYYYMMDD OpenFixed HighFixed LowFixed CloseFixed Volume
0 ACB 20070412 15.3731 15.3731 14.1906 14.2511 57200
1 ACB 20070413 15.3456 15.3456 13.7505 14.6306 134400
2 ACB 20070416 14.8231 15.4006 13.5855 13.5855 74700
3 ACB 20070417 13.7505 13.7505 13.2115 13.4040 85100
4 ACB 20070418 14.0256 14.3006 13.4755 14.2951 117200
5 ACB 20070419 14.5756 14.5756 13.5690 13.6955 118400
6 ACB 20070420 14.2456 14.2456 13.2005 13.3105 135000
7 ACB 20070423 12.4272 12.4558 12.0267 12.0839 40300
8 ACB 20070424 12.1554 12.1697 11.4404 11.9481 136100
9 ACB 20070425 12.1554 13.0278 11.7979 13.0278 1652003. Xây dựng model
Sử dụng mô hình LSTM kết hợp với một hàm để tạo ra chuỗi dữ liệu đầu vào từ dữ liệu gốc cho mô hình dự đoán theo chuỗi thời gian.
Xây dựng lớp PricePredictionModel kế thừa từ nn.Module của PyTorch, đại diện cho mô hình dự đoán giá dựa trên LSTM.
class PricePredictionModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, dropout_rate=0.2):
super(PricePredictionModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout_rate)
self.dropout = nn.Dropout(dropout_rate)
self.fc = nn.Linear(hidden_size, output_size)Trong đó:
- __init__(): Đây là hàm khởi tạo để định nghĩa các thành phần của mô hình.
- input_size: Kích thước đầu vào (số đặc trưng của dữ liệu, ví dụ: giá mở cửa, đóng cửa…).
- hidden_size: Kích thước của tầng ẩn LSTM (số lượng đơn vị ẩn).
- num_layers: Số lớp LSTM xếp chồng lên nhau.
- output_size: Kích thước đầu ra (ví dụ: dự đoán giá đóng cửa tiếp theo).
- dropout_rate: Tỷ lệ dropout để giảm overfitting.
- self.lstm: Định nghĩa một mạng LSTM với số tầng, kích thước ẩn và kích thước đầu vào đã cung cấp. batch_first=True nghĩa là đầu vào có dạng (batch_size, sequence_length, input_size).
- self.dropout: Thêm một tầng dropout để ngăn chặn overfitting.
- self.fc: Một tầng fully connected (tầng kết nối đầy đủ) để chuyển đổi đầu ra của LSTM thành dự đoán cuối cùng.
Tiếp theo, tạo hàm forward để định nghĩa cách dữ liệu đi qua mô hình
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device).to(x.dtype)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device).to(x.dtype)
out, _ = self.lstm(x, (h0, c0))
out = self.dropout(out[:, -1, :])
out = self.fc(out)
return outTrong đó:
- h0, c0: Các trạng thái ẩn (hidden states) ban đầu của LSTM. Đây là các ma trận zero với kích thước phù hợp dựa trên num_layers và hidden_size.
- out, _ = self.lstm(x, (h0, c0)): Đưa dữ liệu đầu vào qua LSTM. out chứa các đầu ra của LSTM tại mỗi thời điểm của chuỗi.
- out = self.dropout(out[:, -1, :]): Sử dụng giá trị của chuỗi tại thời điểm cuối cùng (out[:, -1, :]) và áp dụng dropout.
- out = self.fc(out): Đưa giá trị này qua tầng fully connected để nhận kết quả dự đoán cuối cùng.
Bước tiếp theo là tạo hàm xử lý dữ liệu đầu vào để tạo các chuỗi có độ dài cố định từ dữ liệu đầu vào:
def create_sequences(data, seq_length):
sequences = []
targets = []
for i in range(len(data) - seq_length):
seq = data[i:i+seq_length]
target = data[i+seq_length]
sequences.append(seq)
targets.append(target)
return np.array(sequences), np.array(targets)Trong đó
- data: Dữ liệu gốc, ví dụ là một chuỗi giá cổ phiếu.
- seq_length: Độ dài của mỗi chuỗi đầu vào mà mô hình sẽ sử dụng.
- Hàm duyệt qua dữ liệu, lấy các đoạn liên tiếp có độ dài seq_length làm chuỗi đầu vào (seq), và giá trị tiếp theo ngay sau đó làm nhãn (target). Sau đó lưu các chuỗi và nhãn vào sequences và targets, cuối cùng chuyển chúng thành mảng NumPy và trả về.
4. Chương trình huấn luyện
Bước 1: Load dữ liệu từ file
df = pd.read_csv(data_file)
prices = df['CloseFixed'].values.reshape(-1, 1)
scaler = StandardScaler()
prices_scaled = scaler.fit_transform(prices).flatten()Trong đó:
- prices = df[‘CloseFixed’].values.reshape(-1, 1): Trích xuất cột ‘CloseFixed’ (cột giá đóng cửa đã được điều chỉnh) từ DataFrame và chuyển đổi nó thành mảng NumPy.
- scaler = StandardScaler(): Dùng để khởi tạo bộ chuẩn hóa dữ liệu StandardScaler. Nó chuẩn hóa dữ liệu sao cho dữ liệu có giá trị trung bình là 0 và độ lệch chuẩn là 1.
- prices_scaled = scaler.fit_transform(prices).flatten(): Chuẩn hóa dữ liệu giá đóng cửa và chuyển nó thành mảng 1 chiều.
Sau khi chuẩn hóa và đưa về mảng 1 chiều, 10 giá trị của CloseFixed như sau:
[0.71767401 0.77455819 0.61790561 0.59070014 0.72426928 0.63439378
0.5766852 0.39282714 0.37247175 0.53431061]Bước 2: Tạo mỗi chuỗi dữ liệu với kích thước là 20 giá trị lịch sử và chia dữ liệu thành bộ train và test để đánh giá
sequences, targets = create_sequences(prices_scaled, SEQUENCE_LENGTH)
X_train, X_test, y_train, y_test = train_test_split(sequences, targets, test_size=0.2, random_state=42)Tiếp theo là chuyển các chuỗi dữ liệu sang tensor để phù hợp với pytorch.
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.FloatTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.FloatTensor(y_test).to(device)Bước 3: Khởi tạo mô hình và khởi tạo hàm loss và optimizer
model = PricePredictionModel(input_size=1, hidden_size=HIDDEN_SIZE, num_layers=NUM_LAYERS, output_size=1).to(device)
print(model)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE, weight_decay=1e-5)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=10, factor=0.5)Khi đó, thông tin model sẽ như sau:
PricePredictionModel(
(lstm): LSTM(1, 64, num_layers=2, batch_first=True, dropout=0.2)
(dropout): Dropout(p=0.2, inplace=False)
(fc): Linear(in_features=64, out_features=1, bias=True)
)Bước 4: Kiểm tra checkpoint, nếu đã có checkpoint thì sẽ tiếp tục train từ checkpoint này để tăng hiệu suất và tiết kiệm thời gian train.
if os.path.exists(checkpoint_path):
checkpoint = torch.load(checkpoint_path, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch'] + 1
best_val_loss = checkpoint['best_val_loss']
print(f"Resuming training from epoch {start_epoch}")
else:
best_val_loss = float('inf')Bước 5: Trong mỗi epoch, sẽ đưa dữ liệu vào huấn luyện và tính toán sai số của dữ liệu train và dữ liệu val
for batch_x, batch_y in train_loader:
optimizer.zero_grad()
outputs = model(batch_x.unsqueeze(-1))
loss = criterion(outputs, batch_y.unsqueeze(-1))
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_loader)
train_losses.append(train_loss)Bước 6: Một kỹ thuật hay là lưu lại model khi có sai số val_loss được cải thiện, và kỹ thuật dừng khi sau nhiều epoch mà chất lượng mô hình không được cải thiện (earlystop).
if val_loss < best_val_loss:
best_val_loss = val_loss
patience_counter = 0
torch.save({ 'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'best_val_loss': best_val_loss, 'train_loss': train_loss, 'val_loss': val_loss, }, checkpoint_path)
print("Checkpoint saved.")
else: patience_counter += 1
if patience_counter >= PATIENCE:
print(f'Early stopping triggered after {epoch+1} epochs')
breakKết quả train
Huấn luyện chương trình từ đầu:
root@aicandy:/aicandy/projects/AIcandy_LSTM_Stock_iiyiedys# python AIcandy_LSTM_train_emabpupv.py --data_file history_price.csv --num_epochs 10 --batch_size 32 --checkpoint_path aicandy_lstm_checkpoint_xpisdedn.pth
Using device: cuda
Epoch [1/10], Train Loss: 0.2023, Val Loss: 0.0090
Checkpoint saved.
Epoch [2/10], Train Loss: 0.0155, Val Loss: 0.0059
Checkpoint saved.
Epoch [3/10], Train Loss: 0.0147, Val Loss: 0.0079
Epoch [4/10], Train Loss: 0.0118, Val Loss: 0.0083
Epoch [5/10], Train Loss: 0.0134, Val Loss: 0.0063
Epoch [6/10], Train Loss: 0.0116, Val Loss: 0.0068
Epoch [7/10], Train Loss: 0.0113, Val Loss: 0.0049
Checkpoint saved.
Epoch [8/10], Train Loss: 0.0101, Val Loss: 0.0047
Checkpoint saved.
Epoch [9/10], Train Loss: 0.0116, Val Loss: 0.0045
Checkpoint saved.
Epoch [10/10], Train Loss: 0.0102, Val Loss: 0.0036
Checkpoint saved.
Predicted price for the next day: 25.63
root@aicandy:/aicandy/projects/AIcandy_LSTM_Stock_iiyiedys#Trường hợp huấn luyện từ checkpoint đã có:
root@aicandy:/aicandy/projects/AIcandy_LSTM_Stock_iiyiedys# python AIcandy_LSTM_train_emabpupv.py --data_file history_price.csv --num_epochs 20 --batch_size 32 --checkpoint_path aicandy_lstm_checkpoint_xpisdedn.pth
Using device: cuda
Resuming training from epoch 10
Epoch [11/20], Train Loss: 0.0110, Val Loss: 0.0035
Checkpoint saved.
Epoch [12/20], Train Loss: 0.0098, Val Loss: 0.0043
Epoch [13/20], Train Loss: 0.0089, Val Loss: 0.0036
Epoch [14/20], Train Loss: 0.0101, Val Loss: 0.0037
Epoch [15/20], Train Loss: 0.0095, Val Loss: 0.0032
Checkpoint saved.
Epoch [16/20], Train Loss: 0.0103, Val Loss: 0.0036
Epoch [17/20], Train Loss: 0.0098, Val Loss: 0.0034
Epoch [18/20], Train Loss: 0.0091, Val Loss: 0.0044
Epoch [19/20], Train Loss: 0.0091, Val Loss: 0.0029
Checkpoint saved.
Epoch [20/20], Train Loss: 0.0091, Val Loss: 0.0034
Predicted price for the next day: 25.76
root@aicandy:/aicandy/projects/AIcandy_LSTM_Stock_iiyiedys#Kết quả:
Chương trình dự đoán kết quả ngày tiếp theo là 25.76.
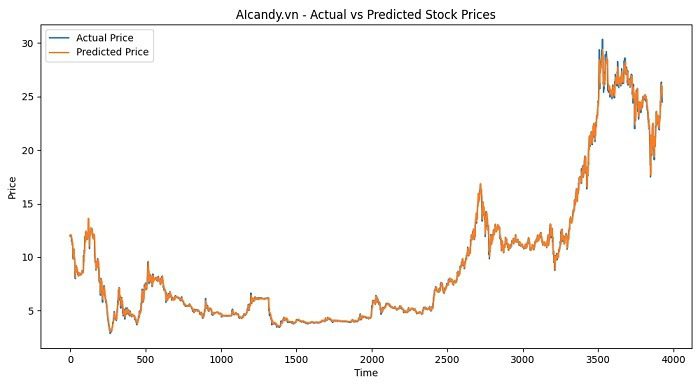
5. Kết luận
Với sự phát triển của các mô hình học sâu như LSTM (Long Short-Term Memory), việc phân tích dữ liệu chuỗi thời gian đã trở nên khả thi và hiệu quả hơn. Mô hình LSTM, với khả năng ghi nhớ các mối liên hệ dài hạn trong chuỗi dữ liệu, giúp cải thiện đáng kể độ chính xác trong việc dự đoán xu hướng giá cổ phiếu.
Tuy nhiên cũng đối diện với nhiều thách thức và nguy cơ do đặc thù của dữ liệu giá cổ phiếu như:
Tính biến động cao của thị trường
Thị trường chứng khoán là một môi trường phức tạp và biến động mạnh mẽ. Giá cổ phiếu có thể thay đổi đột ngột do các yếu tố không thể lường trước như chính trị, khủng hoảng kinh tế, các sự kiện bất ngờ hoặc thay đổi chính sách. Mô hình học máy, dù mạnh mẽ, vẫn gặp khó khăn trong việc phản ứng kịp thời với những sự kiện bất khả kháng này.
Dữ liệu quá khứ không phản ánh hoàn toàn tương lai
Hầu hết các mô hình dự đoán, bao gồm LSTM, dựa trên dữ liệu lịch sử để dự đoán xu hướng tương lai. Tuy nhiên, sự biến đổi của thị trường tài chính có thể phụ thuộc vào nhiều yếu tố khác mà dữ liệu quá khứ không thể hiện rõ ràng, làm giảm độ chính xác của dự đoán.
Sự phức tạp của các yếu tố tác động
Giá cổ phiếu không chỉ phụ thuộc vào dữ liệu tài chính mà còn ảnh hưởng bởi nhiều yếu tố khác như tâm lý nhà đầu tư, tình hình chính trị, khủng hoảng kinh tế, và các tin tức xã hội. Mặc dù các mô hình học máy như LSTM có thể nắm bắt mối quan hệ giữa các yếu tố thời gian, nhưng việc tích hợp toàn diện các yếu tố phi tài chính là rất khó khăn.
Do đó, để đạt được hiệu quả cao, người sử dụng cần thận trọng trong việc đánh giá mô hình, kết hợp với các chiến lược quản lý rủi ro và không phụ thuộc hoàn toàn vào các dự đoán tự động.
6. Source code
Toàn bộ source code được public miễn phí tại đây