Densely Connected Convolutional Networks (mạng DenseNet)
1. Giới thiệu
Trí tuệ nhân tạo (AI) và học sâu (Deep Learning) đã trở thành những công cụ đắc lực trong nhiều lĩnh vực như nhận dạng hình ảnh, xử lý ngôn ngữ tự nhiên, dự báo tài chính, y học, và nhiều ứng dụng khác.
Trong số các kiến trúc mạng nơ-ron nhân tạo, DenseNet (Dense Convolutional Network) nổi bật lên như một giải pháp tiên tiến và hiệu quả cho nhiều vấn đề phức tạp, đặc biệt là trong nhận dạng và phân loại hình ảnh.
Được giới thiệu vào năm 2017 bởi Gao Huang cùng các cộng sự trong bài báo “Densely Connected Convolutional Networks”, DenseNet đã mở ra một hướng đi mới trong việc thiết kế các mạng nơ-ron sâu với kết nối dày đặc.
2. Cấu trúc và nguyên lý hoạt động
Cấu trúc của DenseNet dựa trên một ý tưởng đơn giản nhưng mạnh mẽ: tăng cường kết nối giữa các lớp trong mạng nơ-ron. Trong các kiến trúc mạng nơ-ron truyền thống, mỗi lớp chỉ nhận đầu vào từ lớp liền trước và gửi đầu ra đến lớp liền sau. Tuy nhiên, trong DenseNet, mỗi lớp nhận đầu vào từ tất cả các lớp trước đó và gửi đầu ra đến tất cả các lớp tiếp theo. Điều này tạo ra một mạng lưới dày đặc, nơi mà các đặc trưng được chia sẻ và tái sử dụng liên tục giữa các lớp.
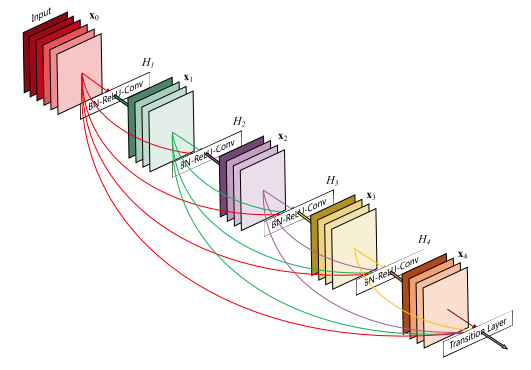
Mạng DenseNet được xây dựng từ các khối Dense (Dense Blocks) và các lớp chuyển tiếp (Transition Layers).

2.1. Dense Block
Mỗi Dense Block gồm nhiều lớp kết nối dày đặc với nhau. Đặc trưng của mỗi lớp trong một Dense Block là việc nhận đầu vào từ tất cả các lớp trước đó, sau đó xuất đầu ra để sử dụng cho các lớp sau. Mỗi lớp trong một Dense Block thường bao gồm một lớp chuẩn hóa theo batch (Batch Normalization), một lớp kích hoạt ReLU, và một lớp tích chập (Convolutional Layer).
Các Dense Block giúp giảm độ phức tạp của mô hình mà vẫn giữ được độ chính xác cao nhờ vào việc tái sử dụng các đặc trưng đã học.
2.2. Transition Layer
Giữa các Dense Block, có các lớp chuyển tiếp giúp giảm kích thước của bản đồ đặc trưng (feature map) bằng cách sử dụng các lớp tích chập 1×1 và phép gộp trung bình (Average Pooling). Transition Layer đóng vai trò quan trọng trong việc kiểm soát kích thước và độ phức tạp của mô hình, ngăn chặn sự phình to của số lượng đặc trưng khi mạng trở nên quá sâu.
3. Ưu điểm
DenseNet có nhiều ưu điểm nổi bật so với các kiến trúc mạng nơ-ron khác, chẳng hạn như ResNet, GoogleNet hay VGGNet:
3.1. Tái sử dụng đặc trưng
Trong các mạng thông thường, mỗi lớp học các đặc trưng mới dựa trên đầu ra của lớp trước đó. Trong DenseNet, các đặc trưng học được từ các lớp trước đó được tái sử dụng ở các lớp tiếp theo, giúp mô hình học tập hiệu quả hơn và giảm thiểu sự dư thừa không cần thiết. Điều này cũng giúp DenseNet đạt được hiệu suất cao với số lượng tham số ít hơn.
3.2. Tránh vấn đề Vanishing Gradient
Nhờ vào kết nối dày đặc, gradient trong quá trình huấn luyện được truyền thông qua toàn bộ mạng một cách dễ dàng hơn, giảm nguy cơ vanishing gradient thường gặp trong các mạng nơ-ron sâu. Điều này đặc biệt hữu ích khi mạng có rất nhiều lớp.
3.3. Hiệu quả sử dụng bộ nhớ
Một ưu điểm quan trọng khác của DenseNet là khả năng sử dụng bộ nhớ một cách hiệu quả hơn. Mặc dù DenseNet có nhiều kết nối hơn, nhưng số lượng tham số thực tế ít hơn so với các mô hình khác có cùng độ sâu. Điều này làm cho DenseNet trở thành một lựa chọn tốt trong các ứng dụng cần tối ưu hóa bộ nhớ, chẳng hạn như các hệ thống nhúng hoặc trên thiết bị di động.
3.4. Giảm thiểu Overfitting
Việc tái sử dụng đặc trưng và cấu trúc kết nối đặc biệt của DenseNet giúp giảm nguy cơ overfitting, ngay cả khi dữ liệu huấn luyện bị giới hạn. Đây là một lợi thế lớn khi làm việc với các tập dữ liệu nhỏ hoặc trong các môi trường học tập có tài nguyên hạn chế.
4. So sánh DenseNet với các kiến trúc khác
DenseNet đã chứng minh được hiệu quả vượt trội của mình qua nhiều bài toán thực nghiệm, đặc biệt là trong các cuộc thi như ImageNet và CIFAR-10. Khi so sánh với các kiến trúc khác:
4.1. So với ResNet
ResNet sử dụng các kết nối tắt (shortcut connections) để truyền tải đầu ra của các lớp trước đến các lớp sau, nhưng chỉ theo cách nối tiếp. DenseNet lại mở rộng ý tưởng này bằng cách kết nối tất cả các lớp với nhau. Điều này giúp DenseNet có khả năng học các đặc trưng phức tạp hơn mà không gặp vấn đề gradient giảm dần.
4.2. So với VGGNet
VGGNet là một trong những mạng nơ-ron đầu tiên sử dụng các lớp tích chập nhỏ 3×3 sâu. Tuy nhiên, DenseNet với các Dense Block có khả năng học tập hiệu quả hơn và sử dụng ít tham số hơn VGGNet, giúp giảm thiểu sự phình to của mô hình.
4.3. So với Inception và GoogleNet
GoogleNet và các biến thể của nó như InceptionV3 sử dụng các khối Inception để nắm bắt các đặc trưng ở nhiều kích thước khác nhau. Mặc dù hiệu quả, nhưng các mô hình này phức tạp hơn nhiều so với DenseNet. DenseNet đạt được kết quả tương đương hoặc tốt hơn với kiến trúc đơn giản hơn, nhờ vào kết nối dày đặc và khả năng tái sử dụng đặc trưng.
5. Các biến thể
Kể từ khi được giới thiệu, DenseNet đã được phát triển và mở rộng với nhiều biến thể khác nhau, nhằm mục đích tối ưu hóa hiệu suất và thích nghi với các bài toán khác nhau trong học sâu. Dưới đây là một số biến thể đáng chú ý của DenseNet:
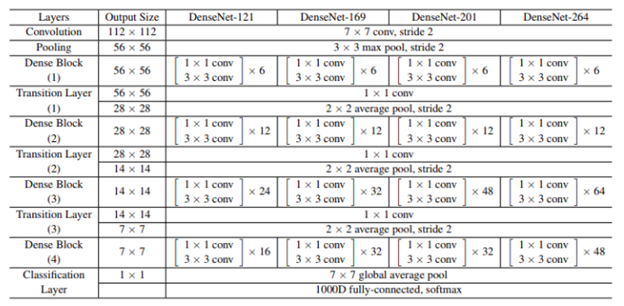
5.1. DenseNet-121, DenseNet-169, DenseNet-201, DenseNet-264
- Những biến thể này được định danh dựa trên số lượng lớp trong mạng, tương ứng với 121, 169, 201, và 264 lớp. Các mạng này khác nhau chủ yếu ở số lượng Dense Block và số lớp trong mỗi block.
- DenseNet-121 là phiên bản cơ bản nhất và thường được sử dụng trong nhiều thử nghiệm nhờ kích thước nhỏ gọn nhưng vẫn đảm bảo hiệu suất cao.
- DenseNet-169 và DenseNet-201 tăng thêm số lượng lớp, làm cho mạng trở nên sâu hơn và có khả năng học các đặc trưng phức tạp hơn, phù hợp cho các bài toán đòi hỏi độ chính xác cao hơn.
- DenseNet-264 là phiên bản sâu nhất trong các biến thể này, với khả năng xử lý các tập dữ liệu lớn và phức tạp, nhưng cũng đòi hỏi tài nguyên tính toán lớn hơn.
5.2. DenseNet-BC
- Biến thể này kết hợp giữa DenseNet và Bottleneck layers (lớp cổ chai) cùng với Compression (nén) để giảm thiểu số lượng tham số và kích thước của mô hình mà không làm giảm hiệu suất.
- Bottleneck layers sử dụng các lớp tích chập 1×1 để giảm số lượng kênh trước khi áp dụng các lớp tích chập 3×3, giảm độ phức tạp tính toán.
- Compression giảm kích thước của bản đồ đặc trưng tại các Transition Layers bằng cách giảm số lượng kênh đầu ra, thường sử dụng một yếu tố nén θ\theta (thường là 0.5).
- DenseNet-BC thường có tên gọi như DenseNet-121-BC, DenseNet-169-BC, v.v., phản ánh việc sử dụng các kỹ thuật Bottleneck và Compression trong mô hình.
5.3. CondenseNet
- Là một biến thể được thiết kế để giảm thiểu số lượng tham số và lượng tính toán, CondenseNet sử dụng kỹ thuật pruning (cắt tỉa) kênh và trọng số không cần thiết trong quá trình huấn luyện, giúp mô hình trở nên nhẹ nhàng và nhanh hơn mà vẫn giữ được độ chính xác cao.
- CondenseNet phù hợp cho các ứng dụng cần tốc độ xử lý nhanh như nhận dạng thời gian thực trên thiết bị di động.
5.4. SparseNet
- SparseNet tiếp tục mở rộng ý tưởng của DenseNet bằng cách áp dụng các kết nối chọn lọc (sparse connections) giữa các lớp, thay vì kết nối dày đặc giữa tất cả các lớp.
- Mặc dù số lượng kết nối ít hơn, SparseNet vẫn duy trì được hiệu suất cao trong khi giảm thiểu độ phức tạp tính toán.
6. Hiệu suất
ImageNet là một trong những tập dữ liệu lớn nhất và thách thức nhất trong lĩnh vực thị giác máy tính, với hơn 1.2 triệu hình ảnh thuộc 1,000 lớp khác nhau. Đây là tiêu chuẩn vàng để đánh giá hiệu suất của các mô hình học sâu trong nhận dạng hình ảnh.
DenseNet đã được thử nghiệm rộng rãi trên tập ImageNet và cho thấy những kết quả ấn tượng:
6.1. DenseNet-121
- Với chỉ 8 triệu tham số, DenseNet-121 đạt được độ chính xác top-1 là 74.91% và độ chính xác top-5 là 92.19% trên ImageNet. Đây là một kết quả xuất sắc so với các mô hình khác có kích thước tương đương.
- Mặc dù có ít tham số hơn ResNet-50, DenseNet-121 vẫn đạt được hiệu suất tương tự, cho thấy hiệu quả vượt trội của kiến trúc DenseNet trong việc tái sử dụng đặc trưng.
6.2. DenseNet-169
DenseNet-169, với khoảng 14.2 triệu tham số, cải thiện độ chính xác top-1 lên 76.2% và top-5 lên 93.2%. Phiên bản này thường được sử dụng cho các bài toán yêu cầu độ chính xác cao hơn DenseNet-121 nhưng vẫn giữ được kích thước mô hình hợp lý.
6.3. DenseNet-201
DenseNet-201 có khoảng 20 triệu tham số, đạt được độ chính xác top-1 là 77.42% và top-5 là 93.66%. Mặc dù có kích thước lớn hơn, DenseNet-201 vẫn giữ được sự cân bằng giữa độ chính xác và hiệu quả tính toán.
6.4. DenseNet-264
DenseNet-264 là phiên bản sâu nhất trong các biến thể gốc, với khoảng 33 triệu tham số. Nó đạt được độ chính xác top-1 là 77.9% và top-5 là 93.86%. Mặc dù có độ chính xác cao, mô hình này đòi hỏi nhiều tài nguyên tính toán và bộ nhớ hơn, làm cho nó ít phổ biến hơn trong các ứng dụng thực tế so với các phiên bản nhỏ hơn như DenseNet-121 và DenseNet-169.
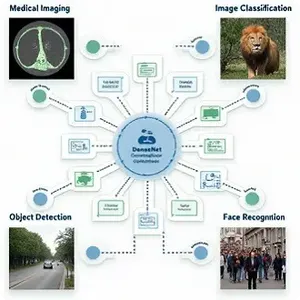
7. Ứng dụng
DenseNet đã được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau, đặc biệt là trong nhận dạng hình ảnh và phân loại hình ảnh.
Một số ứng dụng cụ thể của DenseNet bao gồm:
7.1. Y Tế
Trong y học, DenseNet đã được sử dụng để phân tích hình ảnh y tế như X-quang, MRI, và CT. DenseNet giúp phát hiện sớm các bệnh lý nhờ khả năng nhận dạng các đặc trưng tinh tế trong hình ảnh mà các mô hình khác có thể bỏ qua. Chẳng hạn, trong việc phát hiện ung thư qua hình ảnh X-quang vú, DenseNet đã chứng minh khả năng chẩn đoán với độ chính xác cao.
7.2. Ôtô tự lái
Trong lĩnh vực ô tô tự lái, DenseNet được sử dụng để nhận dạng các đối tượng trên đường như xe cộ, người đi bộ, biển báo giao thông. Khả năng nhận dạng chính xác và nhanh chóng của DenseNet là yếu tố quan trọng để đảm bảo an toàn cho các hệ thống lái xe tự động.
7.3. Giám sát an ninh
DenseNet cũng được áp dụng trong các hệ thống giám sát an ninh, nơi việc phát hiện đối tượng, nhận dạng khuôn mặt, và phân loại hoạt động là những nhiệm vụ quan trọng. DenseNet giúp cải thiện hiệu suất của các hệ thống này, đặc biệt trong việc phát hiện các đối tượng nhỏ hoặc trong điều kiện ánh sáng kém.
7.4. Thương mại điện tử
Trong thương mại điện tử, DenseNet được sử dụng để phân loại và tìm kiếm hình ảnh sản phẩm. Khả năng phân loại chính xác các loại sản phẩm giúp cải thiện trải nghiệm người dùng và tăng hiệu quả tìm kiếm.
8. Kết luận
DenseNet không chỉ nổi bật về hiệu suất trên các tập dữ liệu thách thức như ImageNet, mà còn cho thấy khả năng mở rộng và thích ứng với nhiều bài toán và ứng dụng khác nhau trong học sâu. Các biến thể của DenseNet, từ DenseNet-121 cho đến DenseNet-264, cung cấp nhiều lựa chọn phù hợp với nhu cầu khác nhau về độ chính xác và tài nguyên tính toán. Với các kỹ thuật như Bottleneck, Compression, và pruning, DenseNet đã mở rộng khả năng của mình trong các ứng dụng thực tế, từ y tế, ô tô tự lái, đến giám sát an ninh và thương mại điện tử.
DenseNet và các biến thể của nó chắc chắn sẽ tiếp tục là một công cụ mạnh mẽ trong trí tuệ nhân tạo, giúp giải quyết các vấn đề phức tạp và đẩy nhanh tiến độ phát triển trong lĩnh vực này.