Học tăng cường (Reinforcement Learning): Tìm hiểu chi tiết
1. Giới thiệu
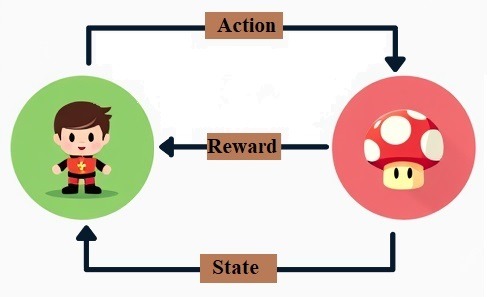
Học tăng cường (Reinforcement Learning – RL) là một nhánh quan trọng của học máy, được sử dụng để giải quyết các bài toán mà trong đó một tác nhân (agent) tương tác với môi trường để học cách đạt được mục tiêu thông qua phần thưởng (reward) và hình phạt (penalty).
Thay vì học từ một tập dữ liệu cố định như trong học có giám sát (supervised learning), tác nhân sẽ học thông qua quá trình thử và sai (trial and error). Mỗi hành động mà tác nhân thực hiện sẽ nhận về một phần thưởng hoặc hình phạt, và mục tiêu của tác nhân là học được cách tối đa hóa tổng phần thưởng nhận được trong dài hạn.
2. Các thành phần chính
Tác nhân (Agent)
Đây là thực thể đưa ra các hành động. Tác nhân có thể là một chương trình AI đang chơi một trò chơi, một robot đang thực hiện các bước di chuyển, hay thậm chí là một hệ thống tự động hóa trong nhà máy.
Môi trường (Environment)
Là tất cả những gì xung quanh tác nhân và có thể tương tác với nó. Môi trường phản hồi lại các hành động của tác nhân bằng cách cung cấp trạng thái mới và phần thưởng tương ứng. Môi trường có thể là vật lý (thế giới thực) hoặc ảo (mô phỏng trò chơi, mô phỏng nhà máy).
Trạng thái (State)
Trạng thái biểu diễn một mô tả ngắn gọn nhưng đầy đủ về tình huống hiện tại của môi trường mà tác nhân đang phải đối mặt. Tại mỗi thời điểm, tác nhân nhận một trạng thái từ môi trường và sử dụng trạng thái này để quyết định hành động tiếp theo.Ví dụ: Trong trò chơi cờ vua, trạng thái là vị trí của tất cả các quân cờ trên bàn cờ tại một thời điểm nhất định.
Hành động (Action)
Là một lựa chọn mà tác nhân có thể thực hiện tại một trạng thái cụ thể. Mỗi hành động có thể dẫn đến một trạng thái mới của môi trường. Mục tiêu của tác nhân là chọn hành động sao cho tối đa hóa phần thưởng nhận được.Ví dụ: Trong trò chơi cờ vua, một hành động có thể là di chuyển quân mã từ ô này sang ô khác.
Phần thưởng (Reward)
Là giá trị phản hồi mà môi trường trả lại sau khi tác nhân thực hiện một hành động. Phần thưởng có thể là dương (thưởng) nếu hành động của tác nhân là đúng, hoặc âm (phạt) nếu hành động là sai. Tác nhân sử dụng thông tin này để điều chỉnh hành động của mình trong tương lai.Ví dụ: Trong trò chơi cờ vua, phần thưởng có thể là giá trị +1 nếu tác nhân bắt được quân đối thủ hoặc giá trị -1 nếu bị mất quân.
Chính sách (Policy)
Chính sách là chiến lược mà tác nhân sử dụng để chọn hành động dựa trên trạng thái hiện tại. Chính sách có thể được biểu diễn dưới dạng một hàm toán học hoặc một bảng tra cứu.Ví dụ: Trong trò chơi cờ vua, chính sách có thể quyết định rằng khi một quân mã ở vị trí X, tác nhân nên di chuyển nó đến vị trí Y để tối đa hóa cơ hội thắng.
Hàm giá trị (Value function)
Hàm giá trị là một hàm dự đoán giá trị tương lai mà tác nhân có thể nhận được từ một trạng thái nhất định. Hàm này giúp tác nhân đánh giá lợi ích của một trạng thái để chọn hành động tốt nhất.Ví dụ: Trong một trò chơi, trạng thái A có giá trị 5, trạng thái B có giá trị 10. Điều này có nghĩa là trạng thái B có thể mang lại phần thưởng cao hơn trong dài hạn, và tác nhân nên cố gắng chuyển đến trạng thái B.
Hàm Q (Q-function)
Hàm Q đánh giá giá trị của việc thực hiện một hành động cụ thể tại một trạng thái cụ thể. Hàm này giúp tác nhân chọn hành động tối ưu bằng cách so sánh giá trị của các hành động khả thi.
Công thức cơ bản cho hàm Q trong bài toán học tăng cường là:
\[Q(s, a) = R(s, a) + \gamma \sum_{s’} P(s’|s, a) \max_{a’} Q(s’, a’) \]
Trong đó:
- \( Q(s, a) \) là giá trị Q của hành động \( a \) tại trạng thái \( s \).
- \( R(s, a) \) là phần thưởng nhận được sau khi thực hiện hành động \( a \) tại trạng thái \( s \).
- \( \gamma \) là hệ số giảm giá (discount factor), mô tả mức độ mà tác nhân đánh giá phần thưởng trong tương lai.
- \( P(s’|s, a) \) là xác suất chuyển trạng thái từ \( s \) sang \( s’ \) sau khi thực hiện hành động \( a \).
Công thức tổng phần thưởng tích lũy:
Phần thưởng mà tác nhân nhận được không chỉ quan tâm đến phần thưởng tức thời mà còn bao gồm tổng phần thưởng trong tương lai. Tổng phần thưởng tích lũy tại thời điểm tt có thể được tính như sau:
Công thức tổng phần thưởng tích lũy:
\[G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1}\]
Trong đó:
- \( G_t \) là tổng phần thưởng tích lũy bắt đầu từ thời điểm \( t \).
- \( \gamma \) là hệ số giảm giá (discount factor), điều chỉnh tầm quan trọng của phần thưởng trong tương lai.
- \( R_t \) là phần thưởng nhận được tại thời điểm \( t \).
3. Các phương pháp học tăng cường
Học tăng cường (Reinforcement Learning) có nhiều phương pháp khác nhau, tùy thuộc vào cách tác nhân học và tối ưu hóa chính sách để nhận được phần thưởng cao nhất. Dưới đây là các phương pháp phổ biến trong học tăng cường:
3.1. Phương pháp học dựa trên giá trị (Value-based Methods)
Phương pháp này tập trung vào việc ước tính giá trị của các trạng thái hoặc các hành động tại các trạng thái, sau đó chọn hành động dựa trên các giá trị này. Tác nhân sẽ học một hàm giá trị để đánh giá mức độ tốt xấu của một trạng thái hoặc hành động.
Q-learning
Đây là thuật toán nổi tiếng nhất trong nhóm học dựa trên giá trị. Q-learning sử dụng hàm giá trị \( Q(s, a) \) để ước tính giá trị của một hành động \( a \) tại trạng thái \( s \).Công thức cập nhật Q-learning:\[Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t+1} + \gamma \max_a Q(s_{t+1}, a) – Q(s_t, a_t) \right]\]
Trong đó:
- \( \alpha \) là tốc độ học.
- \( \gamma \) là hệ số giảm giá.
- \( r_{t+1} \) là phần thưởng sau khi thực hiện hành động \( a_t \).
SARSA (State-Action-Reward-State-Action)
SARSA là một phương pháp tương tự như Q-learning, nhưng thay vì tối ưu hóa theo hành động tốt nhất tiếp theo, nó sử dụng hành động mà tác nhân thực sự thực hiện để cập nhật giá trị \( Q \).
Công thức cập nhật SARSA:
\[Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_{t+1} + \gamma Q(s_{t+1}, a_{t+1}) – Q(s_t, a_t) \right]\]
3.2. Phương pháp học chính sách (Policy-based Methods)
Thay vì học hàm giá trị, phương pháp học chính sách trực tiếp học một chiến lược hoặc chính sách \( \pi(a|s) \), giúp tác nhân chọn hành động dựa trên trạng thái hiện tại.
Policy Gradient
Đây là một phương pháp sử dụng độ dốc (gradient) để điều chỉnh chính sách sao cho tăng cường khả năng của tác nhân trong việc đạt phần thưởng cao. Tác nhân học trực tiếp chiến lược chọn hành động tối ưu thông qua việc tối ưu hóa hàm mục tiêu.
Hàm mất mát của policy gradient thường là:
\[\ \nabla J(\theta) = \mathbb{E}_{\pi_\theta} \left[ \nabla_\theta \log \pi_\theta (a|s) G_t \right] \]Trong đó:
- \( J(\theta) \) là hàm mục tiêu, \(\theta\) là các tham số của chính sách.
- \( \pi_\theta(a|s) \) là xác suất chọn hành động \(a\) tại trạng thái \(s\) dưới chính sách hiện tại.
- \( G_t \) là tổng phần thưởng tích lũy từ thời điểm \( t \).
REINFORCE
REINFORCE là một thuật toán cụ thể trong policy gradient. Nó sử dụng gradient descent để tối ưu hóa chính sách \( \pi_\theta \).
Chính sách được cập nhật dựa trên tổng phần thưởng nhận được từ mỗi tập thử (episode).
3.3. Phương pháp học lai (Actor-Critic Methods)
Phương pháp này kết hợp cả học chính sách và học giá trị. Actor-Critic sử dụng hai thành phần chính:
- Actor: Chịu trách nhiệm học chính sách \( \pi(a|s) \), từ đó chọn hành động.
- Critic: Chịu trách nhiệm học hàm giá trị \( V(s) \), từ đó đánh giá hành động mà Actor đã chọn.
Critic đánh giá hành động của Actor dựa trên sự chênh lệch giữa phần thưởng thực tế và giá trị dự đoán. Sau đó, Actor điều chỉnh chính sách của mình để cải thiện quyết định hành động.
Advantage Actor-Critic (A2C/A3C)
Đây là một thuật toán trong phương pháp Actor-Critic. A2C là phiên bản đơn luồng, trong khi A3C (Asynchronous Advantage Actor-Critic) là phiên bản bất đồng bộ, nơi nhiều tác nhân có thể học song song để cải thiện hiệu suất.
Hàm mất mát của A2C thường là:
\[\ \nabla J(\theta) = \mathbb{E}_{\pi_\theta} \left[ \nabla_\theta \log \pi_\theta (a|s) A(s, a) \right] \]Trong đó:
- \( A(s, a) = Q(s, a) – V(s) \) là giá trị Advantage (lợi thế) của hành động so với các hành động khác tại trạng thái \(s\).
3.4. Phương pháp học sâu tăng cường (Deep Reinforcement Learning)
Khi môi trường có kích thước không gian trạng thái lớn hoặc phức tạp, các phương pháp truyền thống có thể không hoạt động tốt. Phương pháp học sâu tăng cường kết hợp mạng nơ-ron sâu (deep neural networks) để xấp xỉ hàm giá trị và chính sách.
Deep Q-Network (DQN)
Đây là một phiên bản của Q-learning nhưng sử dụng mạng nơ-ron sâu để xấp xỉ hàm giá trị \( Q(s, a) \). Mạng nơ-ron này giúp tác nhân xử lý được các môi trường phức tạp với không gian trạng thái liên tục hoặc quá lớn để có thể biểu diễn bằng bảng giá trị Q.$$ Q(s, a; \theta) \approx \max_a Q(s, a) $$Trong đó, \( \theta \) là tham số của mạng nơ-ron.
Deep Deterministic Policy Gradient (DDPG)
Đây là một thuật toán học chính sách kết hợp với học sâu, hoạt động tốt trong không gian hành động liên tục. DDPG là một sự kết hợp của phương pháp Actor-Critic với mạng nơ-ron sâu.
3.5. Phương pháp Multi-agent Reinforcement Learning (MARL)
Trong nhiều ứng dụng, có nhiều tác nhân (agent) hoạt động trong cùng một môi trường. Phương pháp học tăng cường đa tác nhân (Multi-agent Reinforcement Learning – MARL) nghiên cứu cách nhiều tác nhân học cách hợp tác hoặc cạnh tranh để tối ưu hóa mục tiêu của từng tác nhân.
Cooperative MARL
Các tác nhân học cách hợp tác để đạt được mục tiêu chung.
Competitive MARL
Các tác nhân học cách cạnh tranh và tối ưu hóa mục tiêu riêng biệt.
Những phương pháp này đã và đang được áp dụng rộng rãi trong các lĩnh vực khác nhau như chơi game, robot tự hành, tối ưu hóa hệ thống, và hệ thống đề xuất, đem lại hiệu quả cao trong các bài toán học phức tạp.
4. Ứng dụng của học tăng cường
4.1. Trí tuệ nhân tạo trong trò chơi (AI Gaming)
RL đã được sử dụng rộng rãi trong việc phát triển các AI có khả năng chơi các trò chơi phức tạp. Một ví dụ nổi tiếng là AlphaGo của DeepMind, đã đánh bại nhà vô địch cờ vây thế giới vào năm 2016. Hệ thống này sử dụng học tăng cường kết hợp với mạng nơ-ron để phân tích hàng triệu thế cờ và đưa ra chiến lược tối ưu.
4.2. Điều khiển Robot (Robotics Control)
Trong lĩnh vực robot, RL giúp robot học cách thực hiện các nhiệm vụ phức tạp như điều hướng, gắp đồ vật, và tự động hóa sản xuất. Các thuật toán học tăng cường cho phép robot học cách tối ưu hóa hành động của mình mà không cần can thiệp từ con người, ví dụ như Boston Dynamics sử dụng RL để điều khiển chuyển động linh hoạt của robot bốn chân.
4.3. Xe tự hành (Autonomous Vehicles)
Xe tự hành là một trong những ứng dụng nổi bật của RL, nơi các thuật toán được sử dụng để học cách lái xe trong các môi trường phức tạp. Các hệ thống tự hành như của Tesla hay Waymo sử dụng RL để cải thiện khả năng phát hiện chướng ngại vật, ra quyết định và điều khiển xe một cách an toàn, thậm chí trong những tình huống không lường trước.
4.4. Quản lý tài chính và giao dịch tự động (Financial Trading)
RL đang được áp dụng trong thị trường tài chính để phát triển các hệ thống giao dịch tự động. Các thuật toán có thể học cách dự đoán biến động giá cả và đưa ra các quyết định mua bán sao cho tối đa hóa lợi nhuận dựa trên dữ liệu thị trường. Một ví dụ là việc sử dụng RL trong hedge funds để tối ưu hóa chiến lược đầu tư.
4.5. Tối ưu hóa mạng lưới và tài nguyên (Network Optimization)
Trong các hệ thống viễn thông và quản lý hạ tầng mạng, RL giúp tối ưu hóa việc phân bổ tài nguyên, giảm thiểu độ trễ và nâng cao hiệu quả truyền tải. Điều này rất quan trọng trong các hệ thống như 5G hoặc quản lý băng thông internet, nơi mà hệ thống cần phản ứng nhanh chóng và hiệu quả với sự thay đổi trong yêu cầu của người dùng.
4.6. Hệ thống đề xuất (Recommendation Systems)
Trong các nền tảng như Netflix, Amazon, và YouTube, RL được sử dụng để tối ưu hóa hệ thống đề xuất dựa trên phản hồi của người dùng. Thay vì dựa hoàn toàn vào các phương pháp truyền thống, hệ thống RL học cách đề xuất nội dung hoặc sản phẩm một cách cá nhân hóa dựa trên hành vi và sở thích của người dùng.
5. Ví dụ mã nguồn sử dụng PyTorch
Dưới đây là ví dụ về việc xây dựng mô hình Q-learning đơn giản bằng PyTorch.
Phần đầu tiên là tạo môi trường với 4 trạng thái và có 2 hành động của Agent:
# Môi trường đơn giản
class SimpleEnv:
def __init__(self):
self.state_space = 4 # 4 trạng thái
self.action_space = 2 # 2 hành động
self.state = 0 # Trạng thái hiện tại
def reset(self):
self.state = 0 # Khởi tạo trạng thái
return self.state
def step(self, action):
# Chuyển đổi hành động thành phần thưởng và trạng thái tiếp theo
if self.state == 3:
return self.state, 0, True # Trạng thái cuối cùng, không có phần thưởng
reward = 1 if action == 1 else -1
next_state = (self.state + 1) % self.state_space
done = next_state == 0
self.state = next_state
return next_state, reward, done
Phần thứ 2 là tạo xây dựng mạng noron Q-learning:
# Mô hình mạng nơ-ron cho Q-learning
class QNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 24)
self.fc2 = nn.Linear(24, 24)
self.fc3 = nn.Linear(24, action_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
Phần thứ 3 là chương trình tương tác giữa Agent và môi trường:
# Khởi tạo môi trường, mạng và bộ nhớ
env = SimpleEnv()
q_network = QNetwork(state_size, action_size)
optimizer = optim.Adam(q_network.parameters(), lr=alpha)
criterion = nn.MSELoss()
memory = deque(maxlen=10000)
def select_action(state):
if random.random() < epsilon:
return random.choice([0, 1]) # Chọn hành động ngẫu nhiên
with torch.no_grad():
state_tensor = torch.FloatTensor(state).unsqueeze(0)
q_values = q_network(state_tensor)
return torch.argmax(q_values).item() # Chọn hành động có giá trị Q cao nhất
def replay():
if len(memory) < batch_size:
return
batch = random.sample(memory, batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
dones = torch.FloatTensor(dones)
q_values = q_network(states).gather(1, actions.unsqueeze(1)).squeeze(1)
next_q_values = q_network(next_states).max(1)[0]
target_q_values = rewards + (gamma * next_q_values * (1 - dones))
loss = criterion(q_values, target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Huấn luyện mô hình
for episode in range(episodes):
state = env.reset()
state = np.array([state], dtype=np.float32) # Chuyển đổi trạng thái thành mảng numpy
done = False
while not done:
action = select_action(state)
next_state, reward, done = env.step(action)
next_state = np.array([next_state], dtype=np.float32) # Chuyển đổi trạng thái tiếp theo thành mảng numpy
memory.append((state, action, reward, next_state, done))
state = next_state
replay()
if episode % 100 == 0:
print(f'Episode {episode} completed')
6. Kết luận
Học tăng cường (Reinforcement Learning) là một trong những lĩnh vực đột phá của học máy, mang lại nhiều ứng dụng thực tiễn trong đa dạng ngành công nghiệp, từ trí tuệ nhân tạo trong trò chơi, điều khiển robot, đến xe tự hành và y tế. Với khả năng học hỏi từ môi trường thông qua quá trình thử và sai, các thuật toán RL không chỉ giúp máy móc tự động hóa và tối ưu hóa quy trình, mà còn mở ra tiềm năng phát triển những hệ thống thông minh hơn, có thể ra quyết định tốt hơn trong các tình huống phức tạp. Tương lai của học tăng cường hứa hẹn tiếp tục đóng góp quan trọng vào sự phát triển của trí tuệ nhân tạo và công nghệ hiện đại.