Kỹ thuật huấn luyện dữ liệu tùy chọn với YOLOv5
1. Giới thiệu
Huấn luyện dữ liệu tùy chỉnh với YOLOv5 là một quá trình quan trọng giúp tối ưu hóa mô hình phát hiện đối tượng cho những nhu cầu cụ thể. Thay vì sử dụng các mô hình được huấn luyện sẵn với dữ liệu chung, việc tùy chỉnh YOLOv5 với dữ liệu riêng của bạn cho phép mô hình nhận diện chính xác hơn những đối tượng mà bạn quan tâm. Bài viết này sẽ hướng dẫn chi tiết từng bước từ chuẩn bị dữ liệu, cấu hình mô hình đến huấn luyện và đánh giá kết quả, giúp bạn nhanh chóng làm chủ kỹ thuật này và ứng dụng trong nhiều lĩnh vực khác nhau như giám sát an ninh, nông nghiệp, y tế và nhiều ngành công nghiệp khác.

2. Cài đặt môi trường
Cài đặt Python và các thư viện cần thiết
Để bắt đầu, bạn cần cài đặt Python và một số thư viện cần thiết, bao gồm PyTorch, OpenCV, và các thư viện khác mà YOLOv5 phụ thuộc vào. Dưới đây là các bước cài đặt cụ thể:
Clone YOLOv5 từ GitHub: Tải mã nguồn YOLOv5 từ GitHub bằng lệnh sau:
git clone https://github.com/ultralytics/yolov5.git
cd yolov5Sau khi thực hiện clone source code, cấu trúc thư mục như sau:
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh# git clone https://github.com/ultralytics/yolov5.git
Cloning into 'yolov5'...
remote: Enumerating objects: 16954, done.
remote: Counting objects: 100% (149/149), done.
remote: Compressing objects: 100% (104/104), done.
remote: Total 16954 (delta 76), reused 95 (delta 45), pack-reused 16805 (from 1)
Receiving objects: 100% (16954/16954), 15.71 MiB | 12.17 MiB/s, done.
Resolving deltas: 100% (11609/11609), done.
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh# ls
yolov5
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh# cd yolov5/
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5# ls
benchmarks.py data LICENSE README.zh-CN.md tutorial.ipynb
CITATION.cff detect.py models requirements.txt utils
classify export.py pyproject.toml segment val.py
CONTRIBUTING.md hubconf.py README.md train.py
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5#Cài đặt các phụ thuộc
Sử dụng lệnh pip để cài đặt các thư viện cần thiết từ tệp requirements.txt (Tệp requirements.txt bao gồm các thư viện như PyTorch, numpy, opencv-python, matplotlib, v.v.):
pip install -r requirements.txt3. Chuẩn bị dữ liệu tùy chỉnh
3.1. Thu thập dữ liệu hình ảnh
Để huấn luyện YOLOv5, bạn cần một tập hợp hình ảnh chứa các đối tượng cần phát hiện. Bạn có thể tự thu thập dữ liệu hoặc sử dụng tập dữ liệu công khai. Các hình ảnh có thể là định dạng .jpg hoặc .png, và bạn cần sắp xếp chúng thành các tập huấn luyện (training) và kiểm thử (validation).
Bài viết này tác giả sử dụng bộ dữ liệu aicandy_obj_aegduuyx gồm 6 đối tượng là xe tải quân sự, xe ô tô dân dụng, xe tăng quân sự, máy bay dân dụng, máy bay quân sự và trực thăng quân sự.
Bộ dữ liệu có thể download miễn phí tại Kho dữ liệu dành cho học máy
3.2. Gán nhãn cho hình ảnh
YOLOv5 yêu cầu mỗi hình ảnh phải có tệp nhãn đi kèm, và định dạng tệp nhãn phải theo chuẩn YOLO. Định dạng này sử dụng tọa độ trung tâm và kích thước của đối tượng trong ảnh.
Ví dụ: Giả sử bạn có một hình ảnh tên là image1.jpg, tệp nhãn tương ứng sẽ là image1.txt, và mỗi dòng trong tệp nhãn sẽ có dạng:
<class_id> <x_center> <y_center> <width> <height>
Trong đó:
- class_id: ID của lớp đối tượng (ví dụ: 0 cho người, 1 cho xe hơi).
- x_center, y_center: Tọa độ của tâm đối tượng (giá trị giữa 0 và 1, tính bằng tỉ lệ so với kích thước ảnh).
- width, height: Chiều rộng và chiều cao của đối tượng (giá trị giữa 0 và 1).
Ví dụ về nội dung tệp nhãn cho một hình ảnh chứa hai đối tượng:
0 0.482 0.612 0.178 0.280
1 0.215 0.725 0.230 0.145Trong ví dụ này:
Đối tượng đầu tiên là lớp 0 (có thể là người), với tâm ở tọa độ (0.482, 0.612) và kích thước 17.8% chiều rộng, 28% chiều cao.
Đối tượng thứ hai là lớp 1 (có thể là xe hơi), với tâm ở tọa độ (0.215, 0.725).
3.3. Cấu trúc thư mục dữ liệu
Thư mục chứa dữ liệu cần được tổ chức theo cấu trúc chuẩn để YOLOv5 có thể dễ dàng tìm thấy hình ảnh và nhãn tương ứng:
/datasets
/images
/train # Hình ảnh dùng cho huấn luyện
/val # Hình ảnh dùng cho kiểm thử
/labels
/train # Nhãn cho hình ảnh huấn luyện
/val # Nhãn cho hình ảnh kiểm thử
Ví dụ:
Tất cả các hình ảnh huấn luyện sẽ nằm trong thư mục dataset/images/train.
Nhãn tương ứng với các hình ảnh huấn luyện sẽ nằm trong dataset/labels/train.
Bạn có thể sử dụng công cụ LabelImg hoặc Roboflow để gán nhãn cho dữ liệu một cách trực quan.
3.4. Tạo tệp cấu hình dữ liệu
YOLOv5 sử dụng một tệp YAML để định nghĩa cấu hình tập dữ liệu. Tệp này sẽ chứa đường dẫn đến tập huấn luyện, tập kiểm thử, số lượng lớp và tên các lớp.
Dưới đây là tệp cấu hình data.yaml được sử dụng với bộ dữ liệu aicandy_obj_aegduuyx:
train: /aicandy/datasets/aicandy_obj_aegduuyx/images/train
val: /aicandy/datasets/aicandy_obj_aegduuyx/images/val
names:
0: military truck - xe tải quân sự
1: civilian car - xe ô tô dân dụng
2: military tank - xe tăng quân sự
3: civilian aircraft - máy bay dân dụng
4: military aircraft - máy bay quân sự
5: military helicopter - trực thăng quân sựTrong đó:
train: Đường dẫn đến thư mục chứa hình ảnh huấn luyện.
val: Đường dẫn đến thư mục chứa hình ảnh kiểm thử.
names: Danh sách tên của các lớp, được sắp xếp theo thứ tự tương ứng với class_id trong các tệp nhãn.
4. Huấn luyện mô hình
4.1. Chọn mô hình YOLOv5 pre-trained
YOLOv5 cung cấp nhiều phiên bản mô hình đã được huấn luyện sẵn (pre-trained) trên tập dữ liệu COCO. Các phiên bản có số params khác nhau, thời gian và độ chính xác khác nhau. Xem ảnh dưới để hiểu rõ sự khác nhau giữa các phiên bản này:
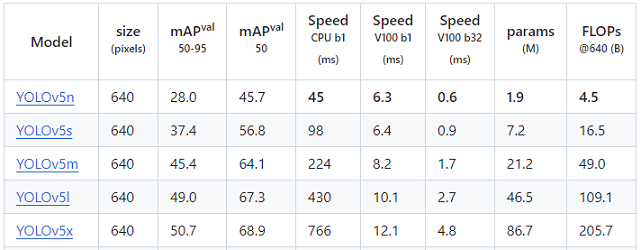
Bạn có thể sử dụng một trong các phiên bản này để bắt đầu.
4.2. Tùy chỉnh các siêu tham số
Trong YOLO5, các siêu tham số đã được lựa chọn phù hợp với dữ liệu lớn nhưng có thể chưa phù hợp với đặc thù dữ liệu của bạn, vì thế chúng ta có thể điều chỉnh một số siêu tham số và training lại để so sánh và lựa chọn bộ siêu tham số phù hợp hơn.
Tạo file hyp.custome.yaml chứa các siêu tham số và giá trị của chúng như sau:
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.3 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 0.7 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.9 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.1 # image mixup (probability)Giải thích các siêu tham số:
- lr0: 0.01 – Tốc độ học ban đầu (learning rate). Đây là giá trị mà mô hình sẽ sử dụng để điều chỉnh các trọng số. Với thuật toán SGD thì giá trị mặc định là 1E-2, còn với Adam là 1E-3.
- lrf: 0.1 – Tốc độ học cuối cùng trong lịch OneCycleLR. Sau khi quá trình huấn luyện gần hoàn tất, tốc độ học sẽ giảm dần về giá trị lr0 * lrf.
- momentum: 0.937 – Động lượng của thuật toán SGD hoặc Adam beta1. Động lượng giúp mô hình điều chỉnh hướng đi trong không gian tham số để tránh dao động lớn và hội tụ nhanh hơn.
- weight_decay: 0.0005 – Hệ số giảm trọng số (weight decay) giúp ngăn ngừa việc mô hình quá khớp (overfitting) bằng cách điều chỉnh trọng số để tránh giá trị quá cao.
- warmup_epochs: 3.0 – Số lượng epochs để huấn luyện khởi động ban đầu (warmup), giúp mô hình từ từ tăng tốc độ học nhằm tránh việc thay đổi quá nhanh các trọng số trong giai đoạn đầu.
- warmup_momentum: 0.8 – Động lượng ban đầu trong giai đoạn warmup. Giá trị này nhỏ hơn so với động lượng chính để tránh thay đổi nhanh chóng trong quá trình khởi động.
- warmup_bias_lr: 0.1 – Tốc độ học dành riêng cho tham số bias trong giai đoạn warmup. Điều này giúp điều chỉnh bias theo cách từ từ trong những bước đầu tiên của quá trình học.
- box: 0.05 – Hệ số trọng số của mất mát hộp (box loss). Điều này kiểm soát mức độ ảnh hưởng của lỗi trong việc phát hiện khung bao đối tượng.
- cls: 0.3 – Hệ số trọng số của mất mát lớp (classification loss). Điều này điều chỉnh mức độ ưu tiên của việc dự đoán chính xác lớp của đối tượng.
- cls_pw: 1.0 – Trọng số dương của mất mát BCELoss (Binary Cross Entropy Loss) cho việc phân loại các lớp đối tượng. Giá trị này điều chỉnh tầm quan trọng của các lớp dương trong quá trình huấn luyện.
- obj: 0.7 – Hệ số trọng số của mất mát đối tượng (object loss). Điều này điều chỉnh độ ưu tiên của việc phát hiện có đối tượng trong khung nhìn.
- obj_pw: 1.0 – Trọng số dương của mất mát BCELoss cho đối tượng. Tương tự như cls_pw, giá trị này điều chỉnh trọng số của các đối tượng trong quá trình học.
- iou_t: 0.20 – Ngưỡng IoU (Intersection over Union) cho quá trình huấn luyện. Nếu IoU giữa khung bao dự đoán và thực tế lớn hơn ngưỡng này, dự đoán được xem là chính xác.
- anchor_t: 4.0 – Ngưỡng tỉ lệ nhiều mỏ neo (anchor-multiple threshold). Điều này quyết định mức độ phù hợp giữa các anchor và đối tượng thực tế.
- fl_gamma: 0.0 – Tham số gamma cho mất mát Focal Loss. Khi sử dụng Focal Loss, giá trị này điều chỉnh mức độ tập trung vào các mẫu khó phát hiện.
- hsv_h: 0.015 – Tăng cường sắc độ (Hue) của hình ảnh trong không gian màu HSV. Đây là tỷ lệ thay đổi sắc độ trong quá trình tăng cường dữ liệu.
- hsv_s: 0.7 – Tăng cường độ bão hòa (Saturation) của hình ảnh. Tỷ lệ này cho biết mức độ biến đổi của độ bão hòa trong quá trình huấn luyện.
- hsv_v: 0.4 – Tăng cường độ sáng (Value) của hình ảnh. Tỷ lệ này quy định mức độ thay đổi của độ sáng trong không gian màu HSV.
- degrees: 0.0 – Góc xoay của hình ảnh trong quá trình tăng cường dữ liệu. Mặc định là không xoay.
- translate: 0.1 – Tỷ lệ tịnh tiến của hình ảnh (dịch chuyển hình ảnh theo các hướng x, y). Điều này giúp tạo thêm dữ liệu bằng cách dịch chuyển đối tượng trong ảnh.
- scale: 0.9 – Tỷ lệ thay đổi kích thước hình ảnh trong quá trình tăng cường dữ liệu.
- shear: 0.0 – Góc cắt hình ảnh. Cắt (shear) là một kỹ thuật biến đổi hình học trong đó các điểm trên hình ảnh di chuyển theo một hướng trong khi giữ nguyên chiều cao hoặc chiều rộng.
- perspective: 0.0 – Tỷ lệ thay đổi phối cảnh của hình ảnh. Điều này điều chỉnh hình dạng và góc nhìn của đối tượng trong ảnh.
- flipud: 0.0 – Xác suất lật hình ảnh theo chiều dọc.
- fliplr: 0.5 – Xác suất lật hình ảnh theo chiều ngang. Mặc định là 50%.
- mosaic: 1.0 – Xác suất sử dụng kỹ thuật tăng cường dữ liệu mosaic, trong đó các hình ảnh được kết hợp với nhau để tạo ra ảnh ghép, giúp mô hình học tốt hơn với các biến thể khác nhau của dữ liệu.
- mixup: 0.1 – Xác suất sử dụng kỹ thuật mixup, trong đó hai hình ảnh và nhãn của chúng được kết hợp với nhau nhằm cải thiện khả năng khái quát hóa của mô hình.
4.3. Huấn luyện mô hình
Dưới đây là lệnh để bắt đầu huấn luyện YOLOv5 với dữ liệu tùy chỉnh của bạn:
python train.py --data data/yaml_aicandy_obj_aegduuyx.yaml --weights yolov5s.pt --img 640 --epochs 100 --name aicandy_yolo_tchdpxdb
Giải thích các tham số:
–img 640: Kích thước ảnh đầu vào (640×640 pixel).
–batch 16: Kích thước batch, tùy thuộc vào dung lượng bộ nhớ GPU.
–epochs 100: Số lượng epochs bạn muốn huấn luyện (100 epochs trong ví dụ này).
–data data/yaml_aicandy_obj_aegduuyx.yaml: Đường dẫn đến tệp cấu hình dữ liệu.
–weights yolov5s.pt: Mô hình YOLOv5 pre-trained mà bạn sẽ fine-tune trên tập dữ liệu mới.
–name aicandy_yolo_tchdpxdb: Tên của folder chứa log train
Trong quá trình huấn luyện, bạn sẽ thấy các thông tin chi tiết như tổn thất (loss), độ chính xác mAP (mean Average Precision), và thời gian mỗi epoch.
Cấu trúc model được hiển thị chi tiết khi bắt đầu train như phía dưới:
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5# python train.py --img 640 --batch 16 --epochs 1 --data data/yaml_aicandy_obj_aegduuyx.yaml --weights yolov5s.pt --name aicandy_yolo_tchdpxdbtrain: weights=yolov5s.pt, cfg=, data=data/yaml_aicandy_obj_aegduuyx.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=1, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, evolve_population=data/hyps, resume_evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=aicandy_yolo_tchdpxdb, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest, ndjson_console=False, ndjson_file=False
github: up to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v7.0-366-gf7322921 Python-3.8.10 torch-1.10.1+cu111 CUDA:0 (NVIDIA GeForce RTX 3080, 9913MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=6
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 29667 models.yolo.Detect [6, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model summary: 214 layers, 7035811 parameters, 7035811 gradients, 16.0 GFLOPsSau khi train hoàn thành, kết quả train được lưu tại: “runs/train/aicandy_yolo_tchdpxdb”
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5#
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5# ls runs/
train
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5# ls runs/train/
aicandy_yolo_tchdpxdb
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5# ls runs/train/aicandy_yolo_tchdpxdb/
confusion_matrix.png labels.jpg results.csv val_batch0_labels.jpg val_batch2_pred.jpg
events.out.tfevents.1726396805.aicandy.3467821.0 opt.yaml results.png val_batch0_pred.jpg weights
F1_curve.png P_curve.png train_batch0.jpg val_batch1_labels.jpg
hyp.yaml PR_curve.png train_batch1.jpg val_batch1_pred.jpg
labels_correlogram.jpg R_curve.png train_batch2.jpg val_batch2_labels.jpg
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5#File model gồm best.pt và last.pt được lưu tại:
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5# ls runs/train/aicandy_yolo_tchdpxdb/weights/
best.pt last.pt
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5#5. Đánh giá và kiểm tra mô hình
5.1. Đánh giá mô hình
Sau khi training xong, các kết quả đánh giá được lưu tại “run/train”
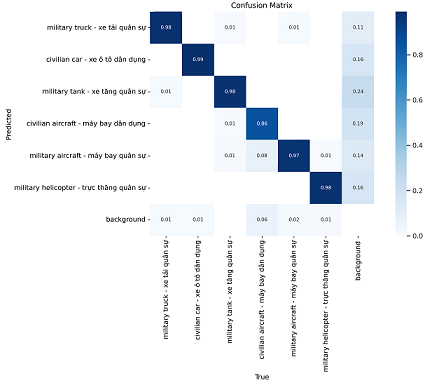
Kết quả confusion_matrix với bộ aicandy_obj_aegduuyx có độ chính xác cao. Cao nhất đạt 99% là nhận dạng đúng “xe ô tô dân dụng”, thấp nhất đạt 86% nhận dạng đúng “máy bay dân dụng”.
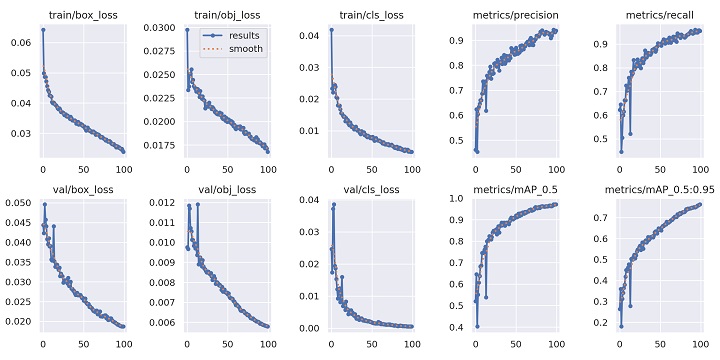
Các chỉ số đánh giá chất lượng mô hình tương đối cao (xem chi tiết như ảnh dưới):
5.2. Thử nghiệm mô hình
Sau khi huấn luyện xong, bạn có thể thử nghiệm mô hình bằng cách sử dụng lệnh detect.py:
python detect.py --weights runs/train/aicandy_yolo_tchdpxdb/weights/best.pt --img 640 --source vinfast_car.jpg—weights: Đường dẫn đến tệp trọng số của mô hình đã huấn luyện.
—img 640: Kích thước ảnh đầu vào.
—source: Đường dẫn đến ảnh, video, hoặc thư mục chứa hình ảnh để kiểm tra mô hình.
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5# python detect.py --weights runs/train/aicandy_yolo_tchdpxdb/weights/best.pt --img 640 --source vinfast_car.jpg
detect: weights=['runs/train/aicandy_yolo_tchdpxdb/weights/best.pt'], source=vinfast_car.jpg, data=data/coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_format=0, save_csv=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 🚀 v7.0-366-gf7322921 Python-3.8.10 torch-1.10.1+cu111 CUDA:0 (NVIDIA GeForce RTX 3080, 9913MiB)
Fusing layers...
Model summary: 212 layers, 20873139 parameters, 0 gradients, 47.9 GFLOPs
image 1/1 /aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5/vinfast_car.jpg: 480x640 1 civilian car - xe ô tô dân dụng, 15.2ms
Speed: 0.4ms pre-process, 15.2ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs/detect/exp
root@aicandy:/aicandy/projects/AIcandy_YOLO5_qvlcalbh/yolov5#Model nhận diện chính xác đối tượng xe (ảnh mẫu không nằm trong tập dữ liệu train/val).

6. Kết luận
Việc huấn luyện dữ liệu tùy chỉnh với YOLOv5 đòi hỏi sự chuẩn bị kỹ lưỡng từ khâu tổ chức dữ liệu, cài đặt môi trường cho đến tinh chỉnh các tham số huấn luyện. Bắt đầu với việc sắp xếp hình ảnh và nhãn theo cấu trúc phù hợp, sau đó sử dụng công cụ tích hợp sẵn của YOLOv5 để tùy chỉnh các tham số như kích thước hình ảnh, batch size và siêu tham số khác. Cuối cùng, quá trình tinh chỉnh (fine-tuning) từ các mô hình pre-trained giúp giảm thời gian huấn luyện mà vẫn đạt được độ chính xác cao. Với sự linh hoạt và hiệu quả của YOLOv5, bạn có thể nhanh chóng triển khai và tối ưu mô hình cho các bài toán phát hiện đối tượng trong các ứng dụng thực tiễn của mình.