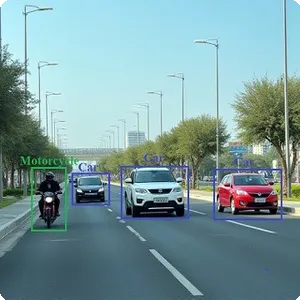
Kỹ thuật huấn luyện dữ liệu tùy chọn với YOLOv8
1. Giới thiệu
YOLO (You Only Look Once) là một trong những kiến trúc mạng nơ-ron nhân tạo hàng đầu trong bài toán phát hiện vật thể. Với sự ra đời của YOLOv8, việc huấn luyện mô hình trở nên dễ dàng hơn nhờ khả năng tối ưu hóa và cải tiến vượt trội. Bài viết này sẽ hướng dẫn chi tiết từng bước giúp bạn huấn luyện dữ liệu tùy chỉnh với YOLOv8, từ việc chuẩn bị môi trường, thu thập dữ liệu, cho đến quá trình huấn luyện và đánh giá mô hình.

2. Cài đặt môi trường
Trước khi bắt đầu, bạn cần cài đặt các công cụ và môi trường cần thiết để huấn luyện YOLOv8. Bạn có thể sử dụng Google Colab, Jupyter Notebook hoặc máy cục bộ có hỗ trợ GPU. Việc sử dụng GPU giúp tăng tốc quá trình huấn luyện đáng kể, đặc biệt với các tập dữ liệu lớn.
Cài đặt YOLOv8
YOLOv8 được phát triển bởi Ultralytics và cung cấp dưới dạng thư viện dễ sử dụng. Bạn có thể cài đặt YOLOv8 bằng cách chạy lệnh sau:
pip install ultralyticsKiểm tra cài đặt bằng Python:
import ultralytics
ultralytics.checks()Nếu cài đặt thành công, thông tin về phiên bản Ultralytics và thông số máy được hiển thị như phía dưới:
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# python
Python 3.8.10 (default, Jul 29 2024, 17:02:10)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import ultralytics
>>> ultralytics.checks()
Ultralytics YOLOv8.2.48  Python-3.8.10 torch-1.10.1+cu111 CUDA:0 (NVIDIA GeForce RTX 3080, 9913MiB)
Setup complete
Python-3.8.10 torch-1.10.1+cu111 CUDA:0 (NVIDIA GeForce RTX 3080, 9913MiB)
Setup complete  (10 CPUs, 19.5 GB RAM, 533.6/882.8 GB disk)
>>> quit()
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq#
(10 CPUs, 19.5 GB RAM, 533.6/882.8 GB disk)
>>> quit()
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# 3. Chuẩn bị dữ liệu tùy chỉnh
3.1. Thu thập dữ liệu hình ảnh
Để huấn luyện YOLOv8, bạn cần một tập hợp hình ảnh chứa các đối tượng cần phát hiện. Bạn có thể tự thu thập dữ liệu hoặc sử dụng tập dữ liệu công khai. Các hình ảnh có thể là định dạng .jpg hoặc .png, và bạn cần sắp xếp chúng thành các tập huấn luyện (training) và kiểm thử (validation).
Bài viết này tác giả sử dụng bộ dữ liệu aicandy_obj_aegduuyx gồm 6 đối tượng là xe tải quân sự, xe ô tô dân dụng, xe tăng quân sự, máy bay dân dụng, máy bay quân sự và trực thăng quân sự.
Bộ dữ liệu có thể download miễn phí tại Kho dữ liệu dành cho học máy
3.2. Gán nhãn cho hình ảnh
YOLOv8 yêu cầu mỗi hình ảnh phải có tệp nhãn đi kèm, và định dạng tệp nhãn phải theo chuẩn YOLO. Định dạng này sử dụng tọa độ trung tâm và kích thước của đối tượng trong ảnh.
Ví dụ: Giả sử bạn có một hình ảnh tên là image1.jpg, tệp nhãn tương ứng sẽ là image1.txt, và mỗi dòng trong tệp nhãn sẽ có dạng:
<class_id> <x_center> <y_center> <width> <height>
Trong đó:
- class_id: ID của lớp đối tượng (ví dụ: 0 cho người, 1 cho xe hơi).
- x_center, y_center: Tọa độ của tâm đối tượng (giá trị giữa 0 và 1, tính bằng tỉ lệ so với kích thước ảnh).
- width, height: Chiều rộng và chiều cao của đối tượng (giá trị giữa 0 và 1).
Ví dụ về nội dung tệp nhãn cho một hình ảnh chứa hai đối tượng:
0 0.482 0.612 0.178 0.280
1 0.215 0.725 0.230 0.145Trong ví dụ này:
Đối tượng đầu tiên là lớp 0 (có thể là người), với tâm ở tọa độ (0.482, 0.612) và kích thước 17.8% chiều rộng, 28% chiều cao.
Đối tượng thứ hai là lớp 1 (có thể là xe hơi), với tâm ở tọa độ (0.215, 0.725).
3.3. Cấu trúc thư mục dữ liệu
Thư mục chứa dữ liệu cần được tổ chức theo cấu trúc chuẩn để YOLOv8 có thể dễ dàng tìm thấy hình ảnh và nhãn tương ứng:
/datasets
/images
/train # Hình ảnh dùng cho huấn luyện
/val # Hình ảnh dùng cho kiểm thử
/labels
/train # Nhãn cho hình ảnh huấn luyện
/val # Nhãn cho hình ảnh kiểm thử
Ví dụ:
Tất cả các hình ảnh huấn luyện sẽ nằm trong thư mục dataset/images/train.
Nhãn tương ứng với các hình ảnh huấn luyện sẽ nằm trong dataset/labels/train.
Bạn có thể sử dụng công cụ LabelImg hoặc Roboflow để gán nhãn cho dữ liệu một cách trực quan.
3.4. Tạo tệp cấu hình dữ liệu
YOLOv8 sử dụng một tệp YAML để định nghĩa cấu hình tập dữ liệu. Tệp này sẽ chứa đường dẫn đến tập huấn luyện, tập kiểm thử, số lượng lớp và tên các lớp.
Dưới đây là tệp cấu hình data.yaml được sử dụng với bộ dữ liệu aicandy_obj_aegduuyx:
train: /aicandy/datasets/aicandy_obj_aegduuyx/images/train
val: /aicandy/datasets/aicandy_obj_aegduuyx/images/val
names:
0: military truck - xe tải quân sự
1: civilian car - xe ô tô dân dụng
2: military tank - xe tăng quân sự
3: civilian aircraft - máy bay dân dụng
4: military aircraft - máy bay quân sự
5: military helicopter - trực thăng quân sựTrong đó:
train: Đường dẫn đến thư mục chứa hình ảnh huấn luyện.
val: Đường dẫn đến thư mục chứa hình ảnh kiểm thử.
names: Danh sách tên của các lớp, được sắp xếp theo thứ tự tương ứng với class_id trong các tệp nhãn.
4. Huấn luyện mô hình
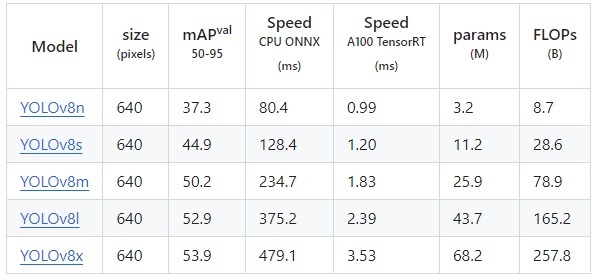
4.1. Chọn mô hình YOLOv8 pre-trained
YOLOv8 cung cấp nhiều phiên bản mô hình đã được huấn luyện sẵn (pre-trained) trên tập dữ liệu COCO. Các phiên bản có số params khác nhau, thời gian và độ chính xác khác nhau. Xem ảnh dưới để hiểu rõ sự khác nhau giữa các phiên bản này:
4.2. Tùy chỉnh các siêu tham số
Trong YOLO8, các siêu tham số đã được lựa chọn phù hợp với dữ liệu lớn nhưng có thể chưa phù hợp với đặc thù dữ liệu của bạn, vì thế chúng ta có thể điều chỉnh một số siêu tham số và training lại để so sánh và lựa chọn bộ siêu tham số phù hợp hơn.
Tạo file hyp.custome.yaml chứa các siêu tham số và giá trị của chúng như sau:
# Learning Rate
lr0: 0.01 # learning rate initial
lrf: 0.01 # final learning rate (lr0 * lrf)
# Optimizer
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay
optimizer: 'SGD' # 'SGD' or 'Adam'
# Other parameters
warmup_epochs: 3.0 # warmup epochs
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.2 # IoU training threshold
Giải thích các siêu tham số:
lr0: 0.01
Đây là learning rate ban đầu, một trong những tham số quan trọng nhất khi huấn luyện mạng nơ-ron. Nó quyết định mức độ thay đổi của các trọng số mô hình sau mỗi bước học. Learning rate quá lớn có thể khiến mô hình không hội tụ (diverge), trong khi learning rate quá nhỏ có thể làm cho mô hình hội tụ chậm. Giá trị mặc định là 0.01 thường được sử dụng, nhưng có thể cần điều chỉnh dựa trên bài toán và dữ liệu cụ thể.
lrf: 0.01
Đây là learning rate cuối cùng (final learning rate). Trong quá trình huấn luyện, learning rate thường được giảm dần theo từng epoch. Giá trị này biểu diễn tỷ lệ giữa learning rate cuối cùng và learning rate ban đầu (lr0 * lrf). Ví dụ, với lr0=0.01 và lrf=0.01, learning rate cuối cùng sẽ là 0.01 * 0.01 = 0.0001.
momentum: 0.937
Tham số momentum là một kỹ thuật thường được sử dụng trong phương pháp tối ưu hóa Stochastic Gradient Descent (SGD). Momentum giúp mô hình tránh việc dao động quá nhiều trong quá trình học, đặc biệt khi gradient thay đổi liên tục theo từng batch dữ liệu. Giá trị mặc định là 0.937, giúp mô hình tiến đến các giá trị trọng số tốt hơn bằng cách “tích lũy” gradient trước đó.
weight_decay: 0.0005
Weight decay là một kỹ thuật điều chuẩn (regularization) được sử dụng để tránh overfitting. Nó hoạt động bằng cách thêm một thành phần phạt (penalty) cho các trọng số lớn trong quá trình tối ưu. Giá trị 0.0005 sẽ làm suy giảm (decay) các trọng số theo thời gian, giúp mô hình trở nên ổn định hơn và tránh fitting quá mức vào tập huấn luyện.
optimizer: ‘SGD’
Đây là loại optimizer sử dụng để cập nhật các trọng số trong mô hình. Có thể chọn ‘SGD’ (Stochastic Gradient Descent) hoặc ‘Adam’, cả hai đều là các phương pháp phổ biến nhưng có cách tính toán gradient khác nhau. ‘SGD’ thường yêu cầu tuning kỹ các tham số như learning rate và momentum, trong khi ‘Adam’ có khả năng tự động điều chỉnh learning rate cho từng trọng số, làm cho nó dễ sử dụng hơn trong nhiều trường hợp.
warmup_epochs: 3.0
Warmup epochs là số lượng epochs ban đầu mà trong đó learning rate sẽ tăng dần từ một giá trị nhỏ lên tới lr0. Việc này giúp tránh các bước nhảy quá lớn trong giai đoạn đầu của quá trình huấn luyện, khi mà các trọng số mô hình vẫn chưa được tối ưu hóa tốt. Giá trị mặc định là 3 epochs.
warmup_momentum: 0.8
Warmup momentum là giá trị momentum khởi tạo trong giai đoạn warmup. Nó giúp tránh việc mô hình dao động mạnh trong giai đoạn đầu của quá trình huấn luyện, tương tự như cách warmup cho learning rate. Giá trị này sau warmup sẽ tăng dần lên tới giá trị momentum chính (0.937).
warmup_bias_lr: 0.1
Warmup bias learning rate là learning rate dành riêng cho các bias trong mô hình trong giai đoạn warmup. Bias là các giá trị cố định trong mỗi nơ-ron giúp cải thiện tính linh hoạt của mô hình. Việc có một warmup learning rate riêng cho bias giúp việc huấn luyện ổn định hơn.
box: 0.05
Đây là hệ số của box loss, tức là hệ số phạt liên quan đến độ chính xác của việc dự đoán vị trí của các hộp giới hạn (bounding box). Giá trị này điều chỉnh mức độ ảnh hưởng của lỗi trong dự đoán vị trí hộp. Giá trị 0.05 làm cho các lỗi về hộp có trọng số nhỏ hơn trong tổng loss.
cls: 0.5
Đây là hệ số của classification loss (mất mát phân loại). Nó điều chỉnh mức độ quan trọng của việc phân loại đúng lớp đối tượng trong quá trình huấn luyện. Giá trị 0.5 có nghĩa là lỗi phân loại có trọng số tương đối lớn trong tổng loss.
cls_pw: 1.0
Classification positive weight (trọng số tích cực của phân loại) là hệ số để tăng trọng số của các dự đoán đúng trong bài toán phân loại. Điều này giúp mô hình chú ý hơn đến các lớp ít xuất hiện trong dữ liệu huấn luyện.
obj: 1.0
Đây là hệ số của objectness loss, tức là lỗi liên quan đến việc mô hình dự đoán liệu có đối tượng nào trong vùng của ảnh hay không. Nó giúp mô hình học cách xác định sự hiện diện của đối tượng trong một vùng ảnh cụ thể.
obj_pw: 1.0
Objectness positive weight là trọng số tích cực của lỗi objectness. Điều này giúp điều chỉnh tầm quan trọng của việc dự đoán đúng sự hiện diện của đối tượng.
iou_t: 0.2
IoU training threshold là ngưỡng Intersection over Union (IoU) dùng để quyết định một dự đoán có được xem là “đúng” hay không. IoU đo lường sự trùng khớp giữa hộp dự đoán và hộp thực tế, với giá trị từ 0 đến 1. Nếu IoU lớn hơn 0.2, dự đoán được xem là tốt. Ngưỡng này thấp, cho phép nhiều dự đoán được chấp nhận, nhưng bạn có thể điều chỉnh tùy theo nhu cầu.
4.3. Huấn luyện mô hình
Huấn luyện thông qua CLI (Command-Line Interface)
Sử dụng lệnh sau để bắt đầu huấn luyện (không custome lại các siêu tham số):
yolo train data=data/yaml_aicandy_obj_aegduuyx.yaml model=pretrain/yolov8m.pt epochs=100 name=aicandy_yolo_icqvtehxSử dụng lệnh sau để bắt đầu huấn luyện nếu muốn custome lại các siêu tham số:
yolo train data=data/yaml_aicandy_obj_aegduuyx.yaml model=pretrain/yolov8m.pt epochs=100 hyp=data/hyp.custome.yaml name=aicandy_yolo_icqvtehxTrong đó:
- model=yolov8m.pt: Sử dụng mô hình YOLOv8 nhỏ.
- data=data/yaml_aicandy_obj_aegduuyx.yaml: Đường dẫn đến file cấu hình YAML.
- epochs=100: Số vòng huấn luyện (epoch).
- imgsz=640: Kích thước ảnh huấn luyện.
- name=aicandy_yolo_icqvtehx: Tên của thư mục chứa kết quả train
Huấn luyện thông qua python:
Tạo file train.py với nội dung như sau:
from ultralytics import YOLO
# Tải mô hình YOLOv8
model = YOLO('yolov8m.pt')
# Huấn luyện mô hình với tập dữ liệu
model.train(data='data/yaml_aicandy_obj_aegduuyx.yaml', epochs=100, imgsz=640)Khi bắt đầu chương trình sẽ in thông tin cấu hình và các thông số của model yolo8 như phía dưới:
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# yolo train data=data/yaml_aicandy_obj_aegduuyx.yaml model=pretrain/yolov8m.pt epochs=100 name=aicandy_yolo_icqvtehx
New https://pypi.org/project/ultralytics/8.2.94 available  Update with 'pip install -U ultralytics'
Ultralytics YOLOv8.2.48 Python-3.8.10 torch-1.10.1+cu111 CUDA:0 (NVIDIA GeForce RTX 3080, 9913MiB)
WARNING
Update with 'pip install -U ultralytics'
Ultralytics YOLOv8.2.48 Python-3.8.10 torch-1.10.1+cu111 CUDA:0 (NVIDIA GeForce RTX 3080, 9913MiB)
WARNING  Upgrade to torch>=2.0.0 for deterministic training.
engine/trainer: task=detect, mode=train, model=pretrain/yolov8m.pt, data=data/yaml_aicandy_obj_aegduuyx.yaml, epochs=100, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=aicandy_yolo_icqvtehx3, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs/detect/aicandy_yolo_icqvtehx3
Overriding model.yaml nc=80 with nc=6
from n params module arguments
0 -1 1 1392 ultralytics.nn.modules.conv.Conv [3, 48, 3, 2]
1 -1 1 41664 ultralytics.nn.modules.conv.Conv [48, 96, 3, 2]
2 -1 2 111360 ultralytics.nn.modules.block.C2f [96, 96, 2, True]
3 -1 1 166272 ultralytics.nn.modules.conv.Conv [96, 192, 3, 2]
4 -1 4 813312 ultralytics.nn.modules.block.C2f [192, 192, 4, True]
5 -1 1 664320 ultralytics.nn.modules.conv.Conv [192, 384, 3, 2]
6 -1 4 3248640 ultralytics.nn.modules.block.C2f [384, 384, 4, True]
7 -1 1 1991808 ultralytics.nn.modules.conv.Conv [384, 576, 3, 2]
8 -1 2 3985920 ultralytics.nn.modules.block.C2f [576, 576, 2, True]
9 -1 1 831168 ultralytics.nn.modules.block.SPPF [576, 576, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 2 1993728 ultralytics.nn.modules.block.C2f [960, 384, 2]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 2 517632 ultralytics.nn.modules.block.C2f [576, 192, 2]
16 -1 1 332160 ultralytics.nn.modules.conv.Conv [192, 192, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 2 1846272 ultralytics.nn.modules.block.C2f [576, 384, 2]
19 -1 1 1327872 ultralytics.nn.modules.conv.Conv [384, 384, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 2 4207104 ultralytics.nn.modules.block.C2f [960, 576, 2]
22 [15, 18, 21] 1 3779170 ultralytics.nn.modules.head.Detect [6, [192, 384, 576]]
Model summary: 295 layers, 25859794 parameters, 25859778 gradients, 79.1 GFLOPs
Upgrade to torch>=2.0.0 for deterministic training.
engine/trainer: task=detect, mode=train, model=pretrain/yolov8m.pt, data=data/yaml_aicandy_obj_aegduuyx.yaml, epochs=100, time=None, patience=100, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=aicandy_yolo_icqvtehx3, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs/detect/aicandy_yolo_icqvtehx3
Overriding model.yaml nc=80 with nc=6
from n params module arguments
0 -1 1 1392 ultralytics.nn.modules.conv.Conv [3, 48, 3, 2]
1 -1 1 41664 ultralytics.nn.modules.conv.Conv [48, 96, 3, 2]
2 -1 2 111360 ultralytics.nn.modules.block.C2f [96, 96, 2, True]
3 -1 1 166272 ultralytics.nn.modules.conv.Conv [96, 192, 3, 2]
4 -1 4 813312 ultralytics.nn.modules.block.C2f [192, 192, 4, True]
5 -1 1 664320 ultralytics.nn.modules.conv.Conv [192, 384, 3, 2]
6 -1 4 3248640 ultralytics.nn.modules.block.C2f [384, 384, 4, True]
7 -1 1 1991808 ultralytics.nn.modules.conv.Conv [384, 576, 3, 2]
8 -1 2 3985920 ultralytics.nn.modules.block.C2f [576, 576, 2, True]
9 -1 1 831168 ultralytics.nn.modules.block.SPPF [576, 576, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 2 1993728 ultralytics.nn.modules.block.C2f [960, 384, 2]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 2 517632 ultralytics.nn.modules.block.C2f [576, 192, 2]
16 -1 1 332160 ultralytics.nn.modules.conv.Conv [192, 192, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 2 1846272 ultralytics.nn.modules.block.C2f [576, 384, 2]
19 -1 1 1327872 ultralytics.nn.modules.conv.Conv [384, 384, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 2 4207104 ultralytics.nn.modules.block.C2f [960, 576, 2]
22 [15, 18, 21] 1 3779170 ultralytics.nn.modules.head.Detect [6, [192, 384, 576]]
Model summary: 295 layers, 25859794 parameters, 25859778 gradients, 79.1 GFLOPsSau khi train hoàn thành, kết quả train được lưu tại: “runs/detect/aicandy_yolo_icqvtehx”
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# ls runs/
detect
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# ls runs/detect/
aicandy_yolo_icqvtehx
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# ls runs/detect/aicandy_yolo_icqvtehx/
args.yaml labels_correlogram.jpg results.csv train_batch37710.jpg val_batch1_labels.jpg
confusion_matrix_normalized.png labels.jpg results.png train_batch37711.jpg val_batch1_pred.jpg
confusion_matrix.png P_curve.png train_batch0.jpg train_batch37712.jpg val_batch2_labels.jpg
events.out.tfevents.1718761486.aicandy.983220.0 PR_curve.png train_batch1.jpg val_batch0_labels.jpg val_batch2_pred.jpg
F1_curve.png R_curve.png train_batch2.jpg val_batch0_pred.jpg weights
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq#File model gồm best.pt và last.pt được lưu tại:
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# ls runs/detect/aicandy_yolo_icqvtehx/weights/
best.pt last.pt
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq#5. Đánh giá và kiểm tra mô hình
5.1. Đánh giá mô hình
Sau khi training xong, các kết quả đánh giá được lưu tại “run/detect/aicandy_obj_aegduuyx“
Kết quả confusion_matrix với bộ aicandy_obj_aegduuyx có độ chính xác cao. Cao nhất đạt sấp xỉ 100% là nhận dạng đúng “xe ô tô dân dụng”, thấp nhất đạt 96% nhận dạng đúng “máy bay dân dụng”.
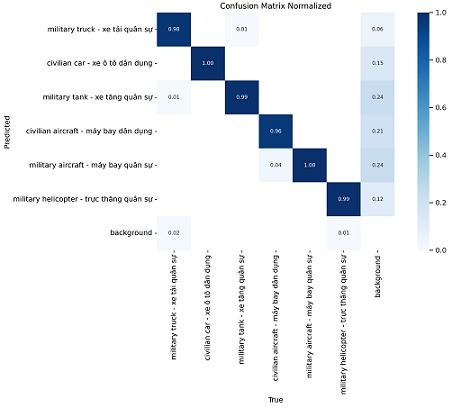
Các chỉ số đánh giá chất lượng mô hình cao (xem chi tiết như ảnh dưới):

5.2. Thử nghiệm mô hình
Sau khi huấn luyện xong, bạn có thể thử nghiệm nhận dạng ảnh như sau:
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq# yolo task=detect mode=predict model=runs/detect/aicandy_yolo_icqvtehx/weights/best.pt source=car.png
Ultralytics YOLOv8.2.48 🚀 Python-3.8.10 torch-1.10.1+cu111 CUDA:0 (NVIDIA GeForce RTX 3080, 9913MiB)
Model summary (fused): 218 layers, 25843234 parameters, 0 gradients, 78.7 GFLOPs
image 1/1 /aicandy/projects/AIcandy_YOLO8_pecdlttq/car.png: 352x640 1 civilian car - xe ô tô dân dụng, 20.7ms
Speed: 3.0ms preprocess, 20.7ms inference, 1.4ms postprocess per image at shape (1, 3, 352, 640)
Results saved to runs/detect/predict
💡 Learn more at https://docs.ultralytics.com/modes/predict
root@aicandy:/aicandy/projects/AIcandy_YOLO8_pecdlttq#
6. Kết luận
Với khả năng linh hoạt và hiệu suất cao, YOLO8 đã chứng tỏ là một công cụ mạnh mẽ cho các dự án nhận diện và phân loại hình ảnh. Việc huấn luyện dữ liệu tùy chỉnh với YOLO8 không chỉ giúp bạn nâng cao độ chính xác của mô hình mà còn tối ưu hóa khả năng nhận dạng các đối tượng trong những kịch bản đặc thù. Qua bài viết này, hy vọng bạn đã nắm vững quy trình từ chuẩn bị dữ liệu, cấu hình mô hình, đến việc huấn luyện và đánh giá kết quả. Để đạt hiệu quả cao nhất, hãy thường xuyên điều chỉnh và thử nghiệm các tham số phù hợp với dự án của bạn. Chúc bạn thành công với những ứng dụng thực tế của YOLO8.