K-Means Clustering: Ưu nhược điểm và hướng áp dụng
1. Giới thiệu
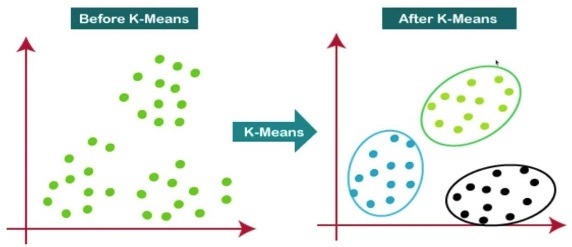
K-Means Clustering là một thuật toán phân cụm phổ biến, thường được sử dụng trong các ứng dụng học máy (Machine Learning) và khai phá dữ liệu (Data Mining). Mục tiêu chính của K-Means là chia một tập hợp các điểm dữ liệu thành k cụm (clusters) sao cho các điểm trong cùng một cụm có sự tương đồng cao nhất với nhau và khác biệt tối đa với các cụm khác.
Trong thuật toán K-Means, mỗi cụm được đại diện bởi một centroid, là giá trị trung bình của các điểm dữ liệu trong cụm đó. Thuật toán sẽ liên tục điều chỉnh các centroid và tái phân cụm các điểm dữ liệu cho đến khi đạt được sự hội tụ (convergence).
2. Cách hoạt động
K-Means Clustering là một thuật toán phân cụm không giám sát phổ biến, dùng để nhóm các điểm dữ liệu thành K cụm dựa trên các đặc tính tương tự. Thuật toán này hoạt động dựa trên ý tưởng là giảm thiểu tổng khoảng cách bình phương giữa các điểm dữ liệu và trung tâm của cụm chúng thuộc về.
K-Means Clustering là một thuật toán phân cụm không giám sát phổ biến, dùng để nhóm các điểm dữ liệu thành K cụm dựa trên các đặc tính tương tự. Thuật toán này hoạt động dựa trên ý tưởng là giảm thiểu tổng khoảng cách bình phương giữa các điểm dữ liệu và trung tâm của cụm chúng thuộc về.
2.1. Khởi tạo các trung tâm cụm (Centroids)
Bước đầu tiên của K-Means là xác định số lượng cụm K mà bạn muốn tìm. Sau đó, chọn ngẫu nhiên K điểm từ tập dữ liệu làm các trung tâm cụm ban đầu, được gọi là các centroid.
2.2. Gán mỗi điểm dữ liệu vào cụm gần nhất
Mỗi điểm dữ liệu được gán vào cụm có centroid gần nhất, được tính bằng khoảng cách Euclidean. Khoảng cách giữa một điểm dữ liệu xi và một centroid cj được tính bằng công thức:
\[d(x_i, c_j) = \sqrt{\sum_{k=1}^{n}(x_{ik} – c_{jk})^2}\]
Trong đó:
- xi là điểm dữ liệu thứ i.
- cj là centroid của cụm thứ j.
- n là số chiều của dữ liệu.
Ví dụ: Giả sử bạn có một tập dữ liệu gồm ba điểm trong không gian hai chiều: (1, 2), (2, 3), và (3, 4), và bạn khởi tạo hai centroid c1 = (1, 1) và c2 = (4, 4). Khoảng cách Euclidean giữa mỗi điểm và centroid được tính như sau:
\[d((1, 2), c_1) = \sqrt{(1-1)^2 + (2-1)^2} = 1\]
\[d((1, 2), c_2) = \sqrt{(1-4)^2 + (2-4)^2} = \sqrt{13}\]
Vì khoảng cách từ điểm (1, 2) đến centroid c1 nhỏ hơn, nên điểm này sẽ được gán vào cụm với centroid c1.
2.3. Cập nhật các trung tâm cụm
Sau khi tất cả các điểm dữ liệu đã được gán vào một cụm, các centroid được tính lại bằng cách lấy trung bình cộng các điểm dữ liệu trong mỗi cụm:
\[c_j = \frac{1}{|C_j|} \sum_{x_i \in C_j} x_i\]
Trong đó:
- Cj là tập hợp các điểm dữ liệu trong cụm j.
- |Cj|</i
- |Cj| là số lượng điểm dữ liệu trong cụm j.
Ví dụ tiếp theo: Giả sử sau khi gán các điểm dữ liệu, cụm C1 bao gồm các điểm (1, 2) và (2, 3), thì centroid mới c1 sẽ được tính như sau:
\[c_1 = \frac{1}{2} \left( (1, 2) + (2, 3) \right) = (1.5, 2.5)\]
2.4. Lặp lại quá trình
Các bước gán cụm và cập nhật centroid được lặp lại cho đến khi các centroid không còn thay đổi đáng kể hoặc đạt đến số lần lặp tối đa. Thuật toán hội tụ khi không có sự thay đổi trong gán cụm của các điểm dữ liệu hoặc sự thay đổi rất nhỏ.
2.5. Đánh giá chất lượng phân cụm
Chất lượng của việc phân cụm có thể được đánh giá bằng tổng bình phương sai số trong cụm (Within-Cluster Sum of Squares – WCSS), được tính bằng công thức:
\[WCSS = \sum_{j=1}^{K} \sum_{x_i \in C_j} d(x_i, c_j)^2\]
Thuật toán cố gắng giảm thiểu giá trị WCSS để đạt được sự phân cụm tốt nhất.
Ví dụ minh họa
Giả sử bạn có dữ liệu sau đây:
- Điểm dữ liệu: (1, 1), (2, 1), (4, 3), (5, 4)
- Khởi tạo K = 2 với các centroid ban đầu c1 = (1, 1) và c2 = (5, 4).
Bước 1: Gán các điểm dữ liệu vào các cụm:
- Điểm (1, 1) và (2, 1) gần centroid c1 hơn, nên thuộc cụm 1.
- Điểm (4, 3) và (5, 4) gần centroid c2 hơn, nên thuộc cụm 2.
Bước 2: Cập nhật các centroid:
- Centroid mới của cụm 1 là c1 = (1.5, 1).
- Centroid mới của cụm 2 là c2 = (4.5, 3.5).
Bước 3: Lặp lại bước 1 và bước 2 cho đến khi các centroid không thay đổi.
3. Ứng dụng
K-Means Clustering được sử dụng rộng rãi trong nhiều lĩnh vực khác nhau, bao gồm:
Phân tích khách hàng
K-Means có thể được sử dụng để phân nhóm khách hàng dựa trên các hành vi mua sắm, từ đó giúp doanh nghiệp hiểu rõ hơn về các phân khúc khách hàng khác nhau.
Phân tích hình ảnh
Trong xử lý hình ảnh, K-Means có thể được sử dụng để phân cụm các điểm ảnh có màu sắc tương đồng, giúp trong việc nén ảnh hoặc phân đoạn ảnh.
Phân tích văn bản
K-Means có thể phân nhóm các tài liệu hoặc từ ngữ dựa trên các đặc trưng chung, giúp tổ chức dữ liệu văn bản hoặc tìm kiếm thông tin.
4. Ưu điểm, nhược điểm của K-Means Clustering
4.1. Ưu điểm của K-Means Clustering
Đơn giản và dễ hiểu
K-Means là một trong những thuật toán phân cụm dễ hiểu nhất, với quy trình hoạt động rõ ràng và dễ triển khai.
Hiệu quả
Thuật toán này có thể xử lý một lượng lớn dữ liệu với chi phí tính toán thấp, đặc biệt là khi số lượng cụm k nhỏ.
Khả năng mở rộng
K-Means có thể mở rộng tốt với dữ liệu lớn, nhờ vào tính chất tuyến tính của nó. Nó có thể được áp dụng trên các tập dữ liệu lớn với hàng triệu điểm dữ liệu.
Linh hoạt
Có thể áp dụng K-Means cho nhiều loại dữ liệu khác nhau, bao gồm cả dữ liệu số và dữ liệu danh mục (categorical).
4.2. Nhược điểm của K-Means Clustering
Số cụm phải được xác định trước
Một trong những hạn chế lớn nhất của K-Means là yêu cầu người dùng phải xác định số lượng cụm k trước khi chạy thuật toán. Điều này có thể khó khăn khi không biết trước số cụm tối ưu.
Nhạy cảm với vị trí khởi tạo centroid
Kết quả của K-Means phụ thuộc rất nhiều vào việc khởi tạo centroid ban đầu. Khởi tạo kém có thể dẫn đến hội tụ tại một cực trị cục bộ không tối ưu.
Chỉ nhận diện các cụm hình cầu
K-Means hoạt động tốt với các cụm có hình dạng gần như cầu và kích thước tương đồng. Nó không thể xử lý tốt các cụm có hình dạng phi tuyến hoặc không đồng đều.
Nhạy cảm với nhiễu
K-Means rất nhạy cảm với các điểm dữ liệu ngoại lai (outliers), vì các outliers có thể kéo centroid ra khỏi vị trí trung tâm của cụm thực sự.
4.3. Khi nào nên sử dụng K-Means Clustering?
K-Means Clustering là một lựa chọn tốt trong các trường hợp sau:
Dữ liệu có cấu trúc đơn giản
Khi dữ liệu có cấu trúc phân cụm đơn giản với các cụm hình cầu hoặc gần hình cầu, K-Means là một công cụ mạnh mẽ.
Số lượng cụm được biết trước
Khi bạn đã biết hoặc có thể ước lượng chính xác số cụm k, K-Means có thể nhanh chóng phân nhóm dữ liệu.
Phân tích dữ liệu sơ bộ
Khi cần phân tích dữ liệu sơ bộ để khám phá các mẫu ẩn, K-Means có thể cung cấp cái nhìn nhanh chóng và rõ ràng về cấu trúc của dữ liệu.
Yêu cầu thời gian tính toán thấp
Khi thời gian và tài nguyên tính toán hạn chế, K-Means cung cấp giải pháp nhanh chóng với hiệu suất tính toán cao.
5. Ví dụ K-Means Clustering trên Python
5.1. K-Means Clustering với scikit-learn
Dưới đây là ví dụ về cách cài đặt K-Means Clustering bằng Python sử dụng thư viện scikit-learn.
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Tạo dữ liệu mẫu
np.random.seed(0)
X = np.random.randn(300, 2)
# Sử dụng thuật toán K-Means với k = 3
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
# Lấy các centroid và gán nhãn cho các điểm dữ liệu
centroids = kmeans.cluster_centers_
labels = kmeans.labels_
# Vẽ biểu đồ các cụm
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], s=300, c='red')
plt.show()
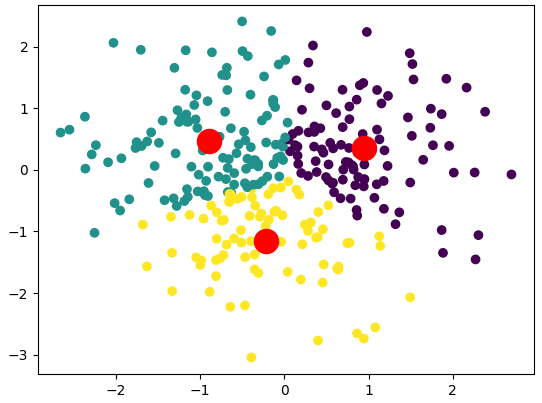
Trong ví dụ này, chúng ta tạo một tập dữ liệu ngẫu nhiên và sử dụng thuật toán K-Means để phân cụm dữ liệu thành 3 cụm. Kết quả được trực quan hóa bằng biểu đồ với các centroid của mỗi cụm được hiển thị dưới dạng các điểm màu đỏ.
5.2. K-Means Clustering với scikit-learn PyTorch
Dưới đây là ví dụ về cách cài đặt K-Means Clustering bằng PyTorch.
import torch
def kmeans(X, k, num_iters=100):
# Randomly initialize centroids
centroids = X[torch.randint(0, X.shape[0], (k,))]
for _ in range(num_iters):
# Compute distances and assign clusters
distances = torch.cdist(X, centroids)
labels = torch.argmin(distances, dim=1)
# Update centroids
new_centroids = torch.stack([X[labels == i].mean(0) for i in range(k)])
# Check for convergence
if torch.all(centroids == new_centroids):
break
centroids = new_centroids
return centroids, labels
# Tạo dữ liệu mẫu
X = torch.randn(300, 2)
# Áp dụng K-Means với k = 3
centroids, labels = kmeans(X, 3)
# Vẽ biểu đồ các cụm
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], s=300, c='red')
plt.show()
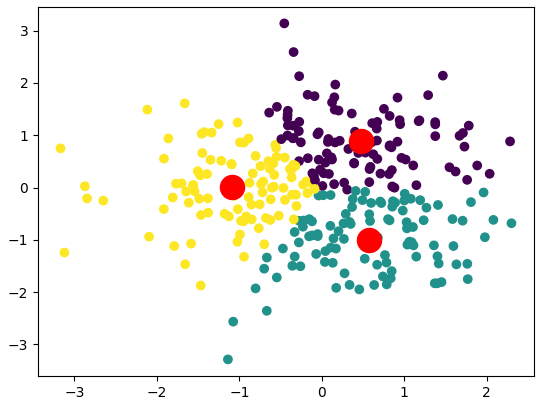
Trong ví dụ này, chúng ta triển khai thuật toán K-Means từ đầu bằng PyTorch. Chúng ta thực hiện việc khởi tạo centroid ngẫu nhiên, tính toán khoảng cách, gán nhãn cho các điểm dữ liệu và cập nhật các centroid theo phương pháp lặp.
6. Kết luận
K-Means Clustering là một thuật toán mạnh mẽ và linh hoạt trong phân cụm dữ liệu, đặc biệt là trong các trường hợp dữ liệu có cấu trúc đơn giản. Tuy nhiên, người dùng cần lưu ý các nhược điểm của thuật toán, như sự nhạy cảm với việc khởi tạo centroid và khả năng hoạt động kém với các cụm phức tạp. Việc hiểu rõ khi nào nên sử dụng K-Means và cách cài đặt nó bằng Python hoặc PyTorch sẽ giúp bạn áp dụng thuật toán này một cách hiệu quả trong các bài toán học máy của mình.