Mô hình ResNet: Đột phá trong nhận diện hình ảnh
1. Giới thiệu
Trong lĩnh vực trí tuệ nhân tạo (AI) và học sâu (Deep Learning), việc phát triển các mô hình mạng nơ-ron với độ sâu lớn thường đối mặt với nhiều thách thức. Một trong những thách thức lớn nhất là degradation problem – vấn đề suy giảm hiệu suất khi mô hình trở nên quá sâu. Để giải quyết vấn đề này, mô hình ResNet (Residual Network) đã được giới thiệu và nhanh chóng trở thành một công cụ mạnh mẽ trong việc nhận diện hình ảnh và nhiều ứng dụng khác.
ResNet
Mô hình resnet được giới thiệu bởi Kaiming He và các cộng sự trong bài báo nổi tiếng “Deep Residual Learning for Image Recognition” vào năm 2015. Ý tưởng đột phá của ResNet là sử dụng skip connections hoặc residual connections giữa các lớp để giải quyết vấn đề suy giảm độ chính xác khi mô hình trở nên sâu hơn. Điều này cho phép thông tin được truyền qua các lớp của mạng mà không bị suy giảm, giúp mô hình có thể học được các đặc trưng (features) phức tạp từ dữ liệu.
2. Cấu trúc và hoạt động
2.1. Cấu trúc
Cấu trúc của ResNet được xây dựng dựa trên việc chia nhỏ mạng thành các khối residual (Residual Blocks), trong đó mỗi khối bao gồm một số lớp tích chập (convolutional layers) cùng với một kết nối tắt trực tiếp từ đầu vào đến đầu ra của khối. Ý tưởng chính là việc học một hàm residual \( F(x) \) thay vì học trực tiếp một hàm mục tiêu \( H(x) \). Điều này giúp duy trì tính ổn định và độ chính xác khi mạng có nhiều tầng.
Khối residual cơ bản
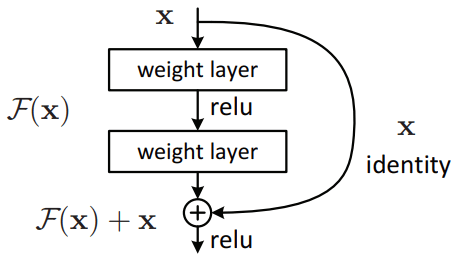
Một khối residual cơ bản trong ResNet có cấu trúc như sau:
\( y = F(x, \{W_i\}) + x \)
trong đó:
- \( x \) là đầu vào của khối.
- \( y \) là đầu ra của khối.
- \( F(x, \{W_i\}) \) là hàm residual, thường được biểu diễn bằng một chuỗi các lớp tích chập với trọng số \( W_i \).
2.2. Nguyên lý hoạt động
Nguyên lý hoạt động của ResNet dựa trên việc thay vì học trực tiếp hàm \( H(x) \), mô hình sẽ học một hàm residual \( F(x) = H(x) – x \). Sau đó, đầu ra của mô hình sẽ là:
\( H(x) = F(x) + x \)
Cách tiếp cận này dựa trên giả định rằng việc học một hàm sai khác \( F(x) \) sẽ dễ dàng hơn so với việc học trực tiếp hàm \( H(x) \). Khi mô hình học được \( F(x) \), nó thực chất đang học cách “điều chỉnh” đầu vào \( x \) để đạt được đầu ra mong muốn \( H(x) \). Nhờ vào các kết nối tắt (skip connections), các tín hiệu thông tin có thể dễ dàng được truyền qua mạng mà không bị suy giảm hoặc mất mát, đặc biệt khi mạng trở nên rất sâu.
Các kết nối tắt trong ResNet mang lại nhiều lợi ích, bao gồm:
Giảm thiểu vanishing gradient
Khi mạng trở nên rất sâu, các giá trị gradient có thể bị giảm mạnh (vanishing) hoặc tăng mạnh (exploding), gây khó khăn trong quá trình huấn luyện. Kết nối tắt giúp giữ lại các giá trị gradient, giảm thiểu hiện tượng này.
Dễ dàng học các đặc trưng
Việc học một hàm residual \( F(x) \) thường đơn giản hơn so với việc học một hàm ánh xạ hoàn toàn mới \( H(x) \), do đó mô hình có thể nhanh chóng đạt được độ chính xác cao hơn.
Tăng độ sâu mà không giảm hiệu suất
Với các kết nối tắt, ResNet có thể được mở rộng đến hàng trăm hoặc hàng ngàn tầng mà không gặp phải vấn đề suy giảm hiệu suất.
3. Các phiên bản của ResNet
ResNet có nhiều phiên bản khác nhau, như ResNet-18, ResNet-34, ResNet-50, ResNet-101, và ResNet-152, với các con số đại diện cho số lượng tầng (layers) trong mô hình.
3.1. ResNet-18
ResNet-18 là một trong những phiên bản nhỏ gọn nhất của ResNet, với tổng cộng 18 tầng. Đây là cấu trúc phù hợp cho những bài toán không yêu cầu mô hình quá phức tạp nhưng vẫn muốn tận dụng lợi ích của kiến trúc residual. Các lớp trong ResNet-18 bao gồm:
- Conv1: Tầng tích chập đầu tiên với kernel size 7×7, stride 2, và 64 filters, theo sau là Batch Normalization và ReLU activation.
- MaxPool: Lớp MaxPooling với kernel size 3×3 và stride 2.
- Conv2_x: Gồm 2 khối residual, mỗi khối có 2 tầng tích chập với 64 filters, stride 1.
- Conv3_x: Gồm 2 khối residual, mỗi khối có 2 tầng tích chập với 128 filters, stride 2.
- Conv4_x: Gồm 2 khối residual, mỗi khối có 2 tầng tích chập với 256 filters, stride 2.
- Conv5_x: Gồm 2 khối residual, mỗi khối có 2 tầng tích chập với 512 filters, stride 2.
- Average Pooling: Lớp pooling trung bình, giảm chiều dữ liệu xuống 1×1.
- Fully Connected Layer: Lớp kết nối đầy đủ với số lượng neurons bằng số lớp đầu ra (output classes).
ResNet-18 là một mô hình dễ triển khai và huấn luyện, với hiệu suất tốt trong các bài toán nhận diện hình ảnh cơ bản.
3.2. ResNet-34
ResNet-34 là phiên bản mở rộng của ResNet-18, với 34 tầng. Cấu trúc này cung cấp nhiều khả năng biểu diễn hơn so với ResNet-18 nhưng vẫn duy trì độ phức tạp tính toán ở mức hợp lý. Các lớp trong ResNet-34 bao gồm:
- Conv1: Tầng tích chập đầu tiên với kernel size 7×7, stride 2, và 64 filters, theo sau là Batch Normalization và ReLU activation.
- MaxPool: Lớp MaxPooling với kernel size 3×3 và stride 2.
- Conv2_x: Gồm 3 khối residual, mỗi khối có 2 tầng tích chập với 64 filters, stride 1.
- Conv3_x: Gồm 4 khối residual, mỗi khối có 2 tầng tích chập với 128 filters, stride 2.
- Conv4_x: Gồm 6 khối residual, mỗi khối có 2 tầng tích chập với 256 filters, stride 2.
- Conv5_x: Gồm 3 khối residual, mỗi khối có 2 tầng tích chập với 512 filters, stride 2.
- Average Pooling: Lớp pooling trung bình, giảm chiều dữ liệu xuống 1×1.
- Fully Connected Layer: Lớp kết nối đầy đủ với số lượng neurons bằng số lớp đầu ra (output classes).
ResNet-34 là một lựa chọn phổ biến cho các bài toán yêu cầu khả năng phân loại tốt hơn so với ResNet-18 mà vẫn giữ được thời gian huấn luyện ở mức chấp nhận được.
3.3. ResNet-50
ResNet-50 bao gồm 50 tầng, với cấu trúc cụ thể như sau:
- Conv1: Tầng tích chập đầu tiên với kernel size 7×7, stride 2, và 64 filters.
- MaxPool: Lớp MaxPooling với kernel size 3×3 và stride 2.
- Conv2_x: Gồm 3 khối residual với 64 filters mỗi khối.
- Conv3_x: Gồm 4 khối residual với 128 filters mỗi khối.
- Conv4_x: Gồm 6 khối residual với 256 filters mỗi khối.
- Conv5_x: Gồm 3 khối residual với 512 filters mỗi khối.
- Average Pooling: Lớp pooling trung bình.
- Fully Connected Layer: Lớp kết nối đầy đủ với số lượng neurons bằng số lớp đầu ra (output classes).
Mỗi khối residual trong các tầng này có cấu trúc tương tự nhau, với một kết nối tắt từ đầu vào đến đầu ra của khối.
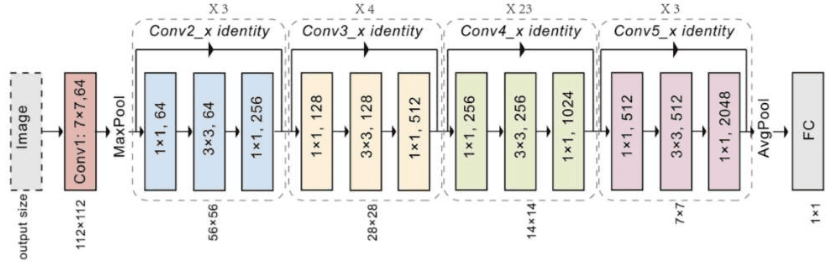
3.4. ResNet-101
ResNet-101 là một phiên bản sâu hơn rất nhiều so với ResNet-18 và ResNet-34, với tổng cộng 101 tầng. Điều này cho phép mô hình học được các đặc trưng phức tạp hơn, phù hợp với những bài toán nhận diện hình ảnh yêu cầu độ chính xác cao. Cấu trúc của ResNet-101 bao gồm:
- Conv1: Tầng tích chập đầu tiên với kernel size 7×7, stride 2, và 64 filters, theo sau là Batch Normalization và ReLU activation.
- MaxPool: Lớp MaxPooling với kernel size 3×3 và stride 2.
- Conv2_x: Gồm 3 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 64 filters, stride 1.
- Conv3_x: Gồm 4 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 128 filters, stride 2.
- Conv4_x: Gồm 23 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 256 filters, stride 2.
- Conv5_x: Gồm 3 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 512 filters, stride 2.
- Average Pooling: Lớp pooling trung bình, giảm chiều dữ liệu xuống 1×1.
- Fully Connected Layer: Lớp kết nối đầy đủ với số lượng neurons bằng số lớp đầu ra (output classes).
Cấu trúc bottleneck của ResNet-101 bao gồm 3 lớp tích chập trong mỗi khối residual, với việc giảm chiều dữ liệu tạm thời trước khi tăng trở lại. Điều này giúp mô hình có thể xử lý một lượng lớn dữ liệu mà vẫn duy trì được hiệu suất tính toán.
3.5. ResNet-152
ResNet-152 là một phiên bản sâu hơn nhiều so với ResNet-18 và ResNet-34, với tổng cộng 152 tầng. Kiến trúc này cho phép mô hình học được các đặc trưng rất phức tạp, phù hợp với các bài toán nhận diện hình ảnh yêu cầu độ chính xác cao và chi tiết.
Cấu trúc của ResNet-152 bao gồm:
- Conv1: Tầng tích chập đầu tiên với kernel size 7×7, stride 2, và 64 filters, theo sau là Batch Normalization và ReLU activation.
- MaxPool: Lớp MaxPooling với kernel size 3×3 và stride 2, giúp giảm kích thước không gian của dữ liệu đầu vào.
- Conv2_x: Gồm 3 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 64 filters. Stride 1 được sử dụng trong tất cả các khối để giữ kích thước không gian của đầu vào không thay đổi.
- Conv3_x: Gồm 8 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 128 filters. Stride 2 được sử dụng ở khối đầu tiên của Conv3_x để giảm kích thước không gian của dữ liệu đầu vào.
- Conv4_x: Gồm 36 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 256 filters. Stride 2 được sử dụng ở khối đầu tiên của Conv4_x để giảm kích thước không gian của dữ liệu đầu vào.
- Conv5_x: Gồm 3 khối bottleneck residual, mỗi khối có 3 tầng tích chập với 512 filters. Stride 2 được sử dụng ở khối đầu tiên của Conv5_x để giảm kích thước không gian của dữ liệu đầu vào.
- Average Pooling: Lớp pooling trung bình với kích thước 1×1, giúp giảm chiều dữ liệu xuống 1×1.
- Fully Connected Layer: Lớp kết nối đầy đủ với số lượng neurons bằng số lớp đầu ra (output classes), thực hiện phân loại dựa trên các đặc trưng đã được trích xuất bởi các tầng trước đó.
ResNet-152 là một mô hình mạnh mẽ với khả năng học các đặc trưng phức tạp từ dữ liệu hình ảnh, nhờ vào số lượng tầng rất sâu và các khối residual giúp duy trì hiệu suất học tốt ngay cả khi mô hình trở nên rất sâu.
4. Độ chính xác
Mô hình ResNet đã đạt được những thành tựu đáng kể trong các cuộc thi nhận diện hình ảnh cũng như trên nhiều thư viện dữ liệu.
4.1. Cuộc thi ImageNet
Cuộc thi ImageNet Large Scale Visual Recognition Challenge (ILSVRC) là một trong những cuộc thi nhận diện hình ảnh nổi tiếng nhất. ResNet đã đạt được những kết quả xuất sắc tại cuộc thi này:
ResNet-50
Đạt được độ chính xác (Top-1 error rate) khoảng 24.7% trên tập kiểm tra ImageNet, với độ chính xác (Top-5 error rate) khoảng 7.0%.
ResNet-101
Đạt được độ chính xác (Top-1 error rate) khoảng 22.0%, với độ chính xác (Top-5 error rate) khoảng 5.7%.
ResNet-152
Đạt được độ chính xác (Top-1 error rate) khoảng 21.2%, với độ chính xác (Top-5 error rate) khoảng 5.4%.
Những kết quả này cho thấy ResNet đã đạt được hiệu suất rất cao trong việc nhận diện hình ảnh, nhờ vào khả năng học các đặc trưng sâu và việc sử dụng các khối residual.
4.2. Các bộ dữ liệu khác
Bên cạnh ImageNet, ResNet cũng đã được kiểm tra và đạt kết quả ấn tượng trên nhiều thư viện dữ liệu khác:
CIFAR-10 và CIFAR-100
ResNet đã cho thấy hiệu suất vượt trội trên tập dữ liệu CIFAR-10 và CIFAR-100. Ví dụ, ResNet-110 đạt được độ chính xác khoảng 93.5% trên CIFAR-10 và 71.0% trên CIFAR-100.
COCO (Common Objects in Context)
Trên tập dữ liệu COCO, ResNet đã được sử dụng như một phần của các mô hình phát hiện đối tượng và đạt được những kết quả xuất sắc. Mô hình sử dụng ResNet-101 đã đạt được độ chính xác cao trong các bài toán phát hiện đối tượng.
Pascal VOC
Trên tập dữ liệu Pascal VOC, ResNet đã đạt được độ chính xác cao trong các bài toán phân loại và phát hiện đối tượng. Ví dụ, ResNet-50 đã đạt được độ chính xác khoảng 80% trên Pascal VOC 2012.
4.3. Các mô hình khác
So với các mô hình học sâu khác như VGG hoặc Inception, ResNet cho thấy sự cải thiện đáng kể về hiệu suất:
VGG-16 và VGG-19
ResNet thường đạt được độ chính xác cao hơn so với VGG-16 và VGG-19 trên các tập dữ liệu lớn, nhờ vào khả năng học sâu hơn và các khối residual giúp giảm thiểu vấn đề vanishing gradient.
Inception-v3
Trong nhiều bài toán nhận diện hình ảnh, ResNet đã cho thấy hiệu suất vượt trội hơn so với Inception-v3, đặc biệt là khi làm việc với các tập dữ liệu lớn và phức tạp.
5. Ứng dụng thực tế
Mô hình ResNet, đặc biệt là các phiên bản sâu như ResNet-50, ResNet-101, và ResNet-152, đã chứng minh được hiệu quả vượt trội trong nhiều lĩnh vực ứng dụng thực tế.
5.1. Nhận diện hình ảnh
Một trong những ứng dụng nổi bật nhất của ResNet là nhận diện hình ảnh. Với khả năng học các đặc trưng rất phức tạp và sâu, ResNet đã được áp dụng rộng rãi trong các bài toán nhận diện hình ảnh, bao gồm:
Nhận diện đối tượng
ResNet có thể phân loại và nhận diện các đối tượng trong hình ảnh, giúp các ứng dụng như nhận diện khuôn mặt, nhận diện đối tượng trong video giám sát, và phân loại ảnh y tế.
Nhận diện cảnh vật
ResNet được sử dụng để phân tích và phân loại các loại cảnh vật trong ảnh, từ đó giúp cải thiện các hệ thống tự động lái xe và phân tích ảnh địa lý.
Phát hiện lỗi trong sản xuất
ResNet có thể phân tích hình ảnh của các sản phẩm trong dây chuyền sản xuất để phát hiện lỗi hoặc khuyết tật.
Phát hiện bệnh lý trong ảnh y tế
ResNet được sử dụng để phân tích ảnh chụp X-quang và MRI, giúp phát hiện các dấu hiệu của bệnh lý như ung thư.
5.2. Ứng dụng đồ họa
ResNet cũng được áp dụng trong các ứng dụng đồ họa để cải thiện trải nghiệm người dùng:
Nhận diện và phân loại đối tượng trong game
Các trò chơi điện tử sử dụng ResNet để phân tích và nhận diện các đối tượng trong cảnh vật 3D, giúp tạo ra các trò chơi có khả năng phản hồi thông minh hơn.
Chuyển đổi phong cách
ResNet được sử dụng trong các hệ thống chuyển đổi phong cách hình ảnh, chẳng hạn như chuyển một bức tranh thành một tác phẩm nghệ thuật theo phong cách của họa sĩ nổi tiếng.
5.3. Hệ thống tự động lái xe
Trong ngành công nghiệp ô tô, ResNet đóng vai trò quan trọng trong hệ thống tự động lái xe:
Nhận diện và phân loại biển báo giao thông
ResNet giúp các hệ thống tự động lái xe nhận diện các biển báo giao thông và đưa ra quyết định dựa trên thông tin này.
Nhận diện và phân loại các phương tiện giao thông
ResNet được sử dụng để nhận diện các loại phương tiện khác nhau trên đường, từ đó hỗ trợ hệ thống lái xe tự động trong việc điều chỉnh tốc độ và hướng đi.
5.4. Ứng dụng trong ngành tài chính
ResNet còn có ứng dụng trong ngành tài chính:
Phân tích hình ảnh tài liệu
ResNet giúp phân tích và nhận diện các đặc trưng trong hình ảnh tài liệu tài chính, chẳng hạn như hóa đơn, chứng từ, và báo cáo tài chính.
Phát hiện gian lận
ResNet có thể được áp dụng để phát hiện các mẫu bất thường trong dữ liệu hình ảnh liên quan đến gian lận tài chính.
6. Triển khai ResNet bằng PyTorch
Dưới đây là ví dụ về cách triển khai một mô hình ResNet-18 đơn giản bằng thư viện PyTorch:
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def ResNet18(num_classes=1000):
return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)
# Tạo mô hình ResNet-18
model = ResNet18()
# In thông tin của mô hình ra màn hình
print(model)
7. Kết luận
Mô hình ResNet đã thay đổi hoàn toàn cách tiếp cận trong việc xây dựng các mạng nơ-ron sâu bằng cách giải quyết hiệu quả vấn đề suy giảm độ chính xác khi tăng độ sâu. Với các kết nối tắt thông minh, ResNet cho phép xây dựng các mô hình với hàng trăm tầng mà không làm mất đi hiệu quả học tập. Nhờ đó, ResNet đã và đang là nền tảng cho nhiều ứng dụng trong nhận diện hình ảnh, phát hiện đối tượng, và nhiều lĩnh vực khác.
Hiểu rõ cấu trúc, nguyên lý hoạt động và cách triển khai ResNet là một bước quan trọng đối với bất kỳ ai đang làm việc trong lĩnh vực trí tuệ nhân tạo và học sâu. Hy vọng rằng bài viết này đã cung cấp cho bạn một cái nhìn toàn diện về mô hình ResNet và cách áp dụng nó vào các bài toán thực tế.