Recurrent Neural Network (RNN): Ứng dụng và cách hoạt động
1. Giới thiệu
Recurrent Neural Networks (RNN) là một loại mạng nơ-ron đặc biệt được thiết kế để xử lý dữ liệu tuần tự. Khác với các mạng nơ-ron thông thường, RNN có khả năng ghi nhớ thông tin từ các bước trước đó nhờ cơ chế phản hồi (recurrent), cho phép mô hình có thể tận dụng ngữ cảnh của dữ liệu trước để dự đoán hoặc suy luận dữ liệu hiện tại. Điều này làm cho RNN đặc biệt hiệu quả trong việc phân tích dữ liệu chuỗi thời gian, xử lý ngôn ngữ tự nhiên, dịch máy, và nhận diện giọng nói, nơi mà thông tin từ quá khứ là rất quan trọng để hiểu chính xác hiện tại.
2. Cách hoạt động của Recurrent Neural Network (RNN)
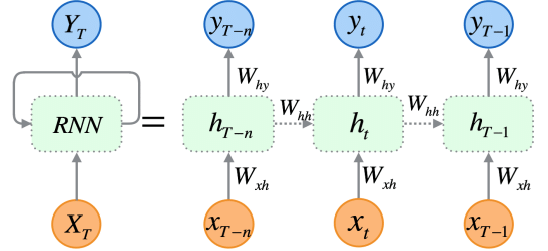
2.1. Hidden State
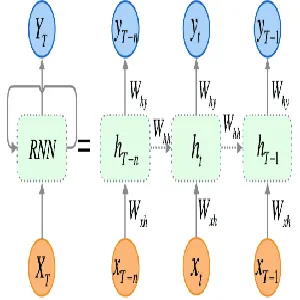
Điểm khác biệt lớn nhất của RNN so với các mạng nơ-ron truyền thống là khả năng lưu trữ và cập nhật thông tin qua các bước của chuỗi thời gian. Tại mỗi bước thời gian (timestep), RNN duy trì một biến gọi là trạng thái ẩn (\( h_t \)), biểu diễn bộ nhớ của mô hình về các thông tin đã nhận được từ những bước trước đó. Trạng thái ẩn này được cập nhật tại mỗi bước thời gian dựa trên đầu vào hiện tại và trạng thái ẩn từ bước trước đó.
Công thức tính toán trạng thái ẩn tại mỗi bước thời gian có thể được biểu diễn như sau:
\[h_t = f(W_{xh}x_t + W_{hh}h_{t-1} + b_h)\]
Trong đó:
- \( h_t \): Trạng thái ẩn tại thời điểm \( t \).
- \( x_t \): Đầu vào tại thời điểm \( t \).
- \( W_{xh} \): Ma trận trọng số kết nối đầu vào với trạng thái ẩn.
- \( W_{hh} \): Ma trận trọng số kết nối trạng thái ẩn trước đó với trạng thái ẩn hiện tại.
- \( b_h \): Tham số bias cho trạng thái ẩn.
- \( f \): Hàm kích hoạt (thường là hàm tanh hoặc ReLU).
2.2. Output
RNN có thể tạo ra đầu ra tại mỗi bước thời gian, thường được tính toán dựa trên trạng thái ẩn tại thời điểm đó. Đầu ra \( y_t \) tại thời điểm \( t \) được tính bằng công thức:
\[y_t = W_{hy}h_t + b_y\]
Trong đó:
- \( y_t \): Đầu ra tại thời điểm \( t \).
- \( W_{hy} \): Ma trận trọng số kết nối trạng thái ẩn với đầu ra.
- \( b_y \): Tham số bias cho đầu ra.
2.3. Backpropagation
Backpropagation là thuật toán lan truyền ngược trong các mạng nơ-ron thông thường. Ở mỗi lớp của mạng nơ-ron, giá trị đầu ra được tính toán dựa trên đầu vào và các trọng số tương ứng. Sau đó, để tối ưu hóa mô hình, ta cần tính toán gradient của hàm mất mát (\( \mathcal{L} \)) theo các trọng số này, giúp ta điều chỉnh các trọng số sao cho mô hình có thể đưa ra dự đoán chính xác hơn.
Công thức tổng quát của lan truyền ngược là:
\[\frac{\partial \mathcal{L}}{\partial W} = \frac{\partial \mathcal{L}}{\partial y} \cdot \frac{\partial y}{\partial W}\]
Trong đó:
- \( \frac{\partial \mathcal{L}}{\partial W} \) là gradient của hàm mất mát theo trọng số \( W \).
- \( \frac{\partial \mathcal{L}}{\partial y} \) là gradient của hàm mất mát theo đầu ra \( y \).
- \( \frac{\partial y}{\partial W} \) là gradient của đầu ra theo trọng số \( W \).
Quá trình này được áp dụng cho tất cả các trọng số trong mạng và được thực hiện từ đầu ra ngược trở lại đầu vào, từng lớp một. Khi đã tính được gradient, các trọng số sẽ được cập nhật bằng cách sử dụng một phương pháp tối ưu hóa như gradient descent.
2.4. Backpropagation Through Time (BPTT)
Trong các mạng RNN, dữ liệu được xử lý tuần tự qua nhiều bước thời gian. Điều này có nghĩa là trạng thái ẩn tại thời điểm \( t \) phụ thuộc vào cả đầu vào tại thời điểm đó và trạng thái ẩn từ bước trước đó. Do đó, khi tính toán gradient, ta không chỉ lan truyền ngược qua các lớp như trong mạng nơ-ron truyền thống mà còn phải lan truyền qua các bước thời gian trước đó. Đây là lý do thuật toán BPTT được ra đời.
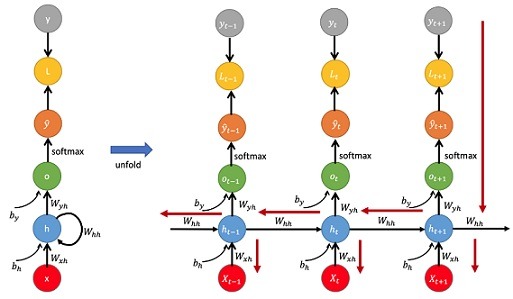
Trong BPTT, mạng RNN được “mở rộng” qua thời gian, mỗi bước thời gian của RNN được coi như một lớp riêng biệt. Khi lan truyền ngược, gradient không chỉ được lan truyền qua các trọng số của các lớp trong mạng, mà còn phải lan truyền ngược qua các bước thời gian để tính toán ảnh hưởng của các trạng thái ẩn trước đó đến lỗi hiện tại.
Công thức tổng quát của BPTT là:
\[\frac{\partial \mathcal{L}}{\partial W} = \sum_{t=1}^{T} \frac{\partial \mathcal{L}_t}{\partial y_t} \cdot \frac{\partial y_t}{\partial h_t} \cdot \frac{\partial h_t}{\partial h_{t-1}} \cdot \frac{\partial h_{t-1}}{\partial W}\]
Trong đó:
- \( \frac{\partial \mathcal{L}_t}{\partial y_t} \) là gradient của hàm mất mát tại bước thời gian \( t \) theo đầu ra \( y_t \).
- \( \frac{\partial y_t}{\partial h_t} \) là gradient của đầu ra tại thời điểm \( t \) theo trạng thái ẩn \( h_t \).
- \( \frac{\partial h_t}{\partial h_{t-1}} \) là gradient của trạng thái ẩn hiện tại theo trạng thái ẩn trước đó.
- \( \frac{\partial h_{t-1}}{\partial W} \) là gradient của trạng thái ẩn trước theo trọng số \( W \).
2.5 Triển khai RNN bằng PyTorch
Dưới đây là cách triển khai một mạng RNN đơn giản bằng PyTorch. Mạng sẽ dự đoán số tiếp theo của chuỗi [1, 2, 3, 4].
import torch
import torch.nn as nn
import numpy as np
# Thiết lập một RNN cơ bản
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden):
out, hidden = self.rnn(x, hidden)
out = self.fc(out[:, -1, :]) # Chỉ lấy output cuối cùng
return out, hidden
def init_hidden(self, batch_size):
# Khởi tạo hidden state với tất cả các giá trị 0
return torch.zeros(1, batch_size, self.hidden_size)
# Dữ liệu mẫu: Chuỗi số lượng
def create_data(sequence_length, num_samples):
data = []
for _ in range(num_samples):
start = np.random.randint(0, 3)
seq = np.array([i for i in range(start, start + sequence_length)])
data.append(seq)
return np.array(data)
# Chuẩn bị dữ liệu
sequence_length = 5
num_samples = 1000
data = create_data(sequence_length, num_samples)
# Chuyển đổi dữ liệu thành tensor
input_data = torch.tensor(data[:, :-1], dtype=torch.float32).unsqueeze(-1)
target_data = torch.tensor(data[:, -1], dtype=torch.float32)
# Siêu tham số
input_size = 1
hidden_size = 10
output_size = 1
learning_rate = 0.01
num_epochs = 500
# Khởi tạo mạng RNN
model = SimpleRNN(input_size, hidden_size, output_size)
# Tối ưu hóa và hàm mất mát
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Huấn luyện mạng
for epoch in range(num_epochs):
# Khởi tạo hidden state
hidden = model.init_hidden(input_data.size(0))
# Forward pass
outputs, hidden = model(input_data, hidden)
loss = criterion(outputs.squeeze(), target_data)
# Backward pass và tối ưu hóa
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 50 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# Dự đoán một chuỗi mới
test_seq = torch.tensor([[1, 2, 3, 4]], dtype=torch.float32).unsqueeze(-1)
hidden = model.init_hidden(test_seq.size(0))
predicted, hidden = model(test_seq, hidden)
print(f'Predicted next number: {predicted.item():.4f}')
Giải thích:
Mạng có 3 thành phần chính: RNN, Linear (fully connected layer), và phương thức forward. Hàm init_hidden dùng để khởi tạo hidden state với tất cả các giá trị là 0. Hàm create_data để tạo ra một chuỗi số lượng đơn giản để sử dụng cho việc huấn luyện. Quá trình huấn luyện mô hình bằng cách tối ưu hóa thông qua Adam và hàm mất mát là MSELoss (mean squared error loss). Sau khi huấn luyện, mô hình có thể dự đoán số tiếp của chuỗi [1, 2, 3, 4].
Kết quả:
Epoch [50/500], Loss: 0.8040
Epoch [100/500], Loss: 0.6532
Epoch [150/500], Loss: 0.6498
Epoch [200/500], Loss: 0.6388
Epoch [250/500], Loss: 0.5536
Epoch [300/500], Loss: 0.1038
Epoch [350/500], Loss: 0.0001
Epoch [400/500], Loss: 0.0000
Epoch [450/500], Loss: 0.0000
Epoch [500/500], Loss: 0.0000
Predicted next number: 5.00003. Các loại RNN phổ biến
Mạng RNN được thiết kế để xử lý các chuỗi dữ liệu, như văn bản, âm thanh, hoặc chuỗi thời gian. Các loại RNN phổ biến bao gồm RNN truyền thống, LSTM và GRU.
3.1. RNN truyền thống
RNN truyền thống là loại đơn giản nhất của mạng hồi quy. Ở đây, mỗi nơ-ron không chỉ nhận dữ liệu đầu vào mà còn nhận trạng thái ẩn từ bước trước đó, tạo thành một chuỗi hồi quy qua thời gian.
Công thức cập nhật trạng thái ẩn của RNN truyền thống là:
$$ h_t = \tanh(W_h h_{t-1} + W_x x_t + b_h) $$
Trong đó:
- h_t: trạng thái ẩn tại thời điểm t
- x_t: đầu vào tại thời điểm t
- W_h, W_x: ma trận trọng số
- b_h: vector bias
- tanh: hàm kích hoạt tanh
Tuy nhiên, RNN truyền thống gặp phải vấn đề “biến mất hoặc bùng nổ gradient” khi xử lý các chuỗi dài.
Ví dụ code PyTorch cho mạng RNN truyền thống
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h_0 = torch.zeros(1, x.size(0), hidden_size)
out, _ = self.rnn(x, h_0)
out = self.fc(out[:, -1, :])
return out
input_size = 10
hidden_size = 20
output_size = 1
model = SimpleRNN(input_size, hidden_size, output_size)3.2. LSTM (Long Short-Term Memory)
LSTM là một biến thể của RNN được thiết kế để khắc phục vấn đề biến mất gradient. Nó sử dụng các cổng để kiểm soát luồng thông tin, bao gồm cổng quên, cổng đầu vào và cổng đầu ra, cho phép nó lưu giữ hoặc quên thông tin tùy thuộc vào tầm quan trọng của chúng.
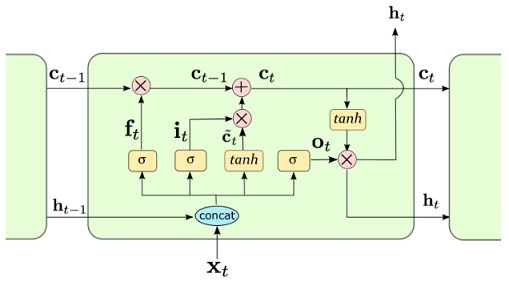
Công thức cập nhật của LSTM:
$$ f_t = \sigma(W_f x_t + U_f h_{t-1} + b_f) $$
$$ i_t = \sigma(W_i x_t + U_i h_{t-1} + b_i) $$
$$ \tilde{c}_t = \tanh(W_c x_t + U_c h_{t-1} + b_c) $$
$$ c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t $$
$$ o_t = \sigma(W_o x_t + U_o h_{t-1} + b_o) $$
$$ h_t = o_t \odot \tanh(c_t) $$
Trong đó:
- f_t: cổng quên
- i_t: cổng đầu vào
- o_t: cổng đầu ra
- c_t: trạng thái tế bào
- odot: phép nhân từng phần tử
Ví dụ code PyTorch cho mạng LSTM
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h_0 = torch.zeros(1, x.size(0), hidden_size)
c_0 = torch.zeros(1, x.size(0), hidden_size)
out, _ = self.lstm(x, (h_0, c_0))
out = self.fc(out[:, -1, :])
return out
model = LSTMModel(input_size, hidden_size, output_size)3.3. GRU (Gated Recurrent Unit)
GRU là một biến thể khác của LSTM, nhưng đơn giản hơn vì nó không có trạng thái tế bào riêng biệt. GRU kết hợp trạng thái ẩn và trạng thái tế bào thành một, giúp tăng hiệu quả tính toán.
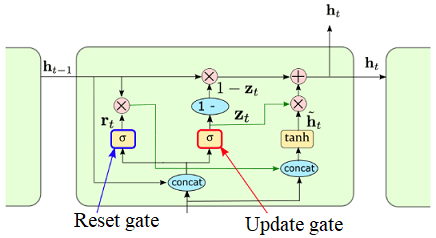
Công thức cập nhật của GRU:
$$ z_t = \sigma(W_z x_t + U_z h_{t-1} + b_z) $$
$$ r_t = \sigma(W_r x_t + U_r h_{t-1} + b_r) $$
$$ \tilde{h}_t = \tanh(W_h x_t + r_t \odot U_h h_{t-1}) $$
$$ h_t = (1 – z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t $$
Ví dụ code PyTorch cho mạng GRU
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(GRUModel, self).__init__()
self.gru = nn.GRU(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h_0 = torch.zeros(1, x.size(0), hidden_size)
out, _ = self.gru(x, h_0)
out = self.fc(out[:, -1, :])
return out
model = GRUModel(input_size, hidden_size, output_size)4. Ứng dụng thực tế
RNN (Recurrent Neural Networks), LSTM (Long Short-Term Memory), và GRU (Gated Recurrent Unit) đều là các loại mạng nơ-ron hồi quy, được sử dụng chủ yếu trong các bài toán liên quan đến dữ liệu tuần tự và thời gian. Chúng đã và đang mang lại những kết quả xuất sắc trong nhiều lĩnh vực khác nhau. Dưới đây là một số ứng dụng thực tế tiêu biểu của chúng:
4.1. Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP)
Dịch máy (Machine Translation)
Các mô hình RNN, đặc biệt là LSTM và GRU, được sử dụng rộng rãi trong việc dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác. Chúng có khả năng ghi nhớ thông tin từ các từ trước đó để dự đoán các từ tiếp theo, giúp dịch máy trở nên mượt mà hơn. Ví dụ, mô hình seq2seq sử dụng LSTM cho việc dịch ngôn ngữ.
Tóm tắt văn bản (Text Summarization)
Mô hình LSTM và GRU có thể được sử dụng để tóm tắt các đoạn văn bản dài thành các câu ngắn hơn mà vẫn giữ được ý chính.
Phân tích cảm xúc (Sentiment Analysis)
RNN và các biến thể của nó giúp phân tích cảm xúc từ các câu văn bản như đánh giá sản phẩm, bài viết trên mạng xã hội.
Nhận diện giọng nói (Speech Recognition)
Các mạng LSTM và GRU có khả năng xử lý các chuỗi âm thanh dài, giúp phân tích và chuyển đổi âm thanh thành văn bản trong các hệ thống như Siri, Google Assistant.
4.2. Dự đoán chuỗi thời gian (Time Series Prediction)
Dự báo tài chính
Trong lĩnh vực tài chính, LSTM và GRU thường được sử dụng để dự đoán các chỉ số chứng khoán, tỷ giá hối đoái và các biến động tài chính dựa trên dữ liệu quá khứ. Chúng có khả năng xử lý dữ liệu có tính tuần tự và thời gian dài, giúp cải thiện độ chính xác trong dự báo.
Dự báo thời tiết
Các mô hình RNN cũng được sử dụng để dự báo các hiện tượng thời tiết, phân tích dữ liệu thời gian dài để dự đoán các thay đổi trong khí hậu.
4.3. Xử lý tín hiệu âm thanh và video
Nhận diện giọng nói và tổng hợp giọng nói
LSTM và GRU thường được sử dụng trong các hệ thống nhận diện giọng nói và tổng hợp giọng nói như Google Speech, Amazon Alexa. Chúng giúp phân tích và chuyển đổi các chuỗi âm thanh thành dữ liệu văn bản, hoặc ngược lại.
Nhận dạng đối tượng trong video (Video Classification)
Các mô hình RNN có thể xử lý chuỗi các khung hình của video để phân loại và nhận diện các đối tượng hoặc hành động xuất hiện trong video.
4.4. Chăm sóc sức khỏe
Dự đoán tình trạng bệnh nhân
Các mô hình RNN có thể phân tích dữ liệu chuỗi thời gian về sức khỏe của bệnh nhân, như nhịp tim, huyết áp, để dự đoán các biến chứng hoặc sự chuyển biến của bệnh.
Phân tích tín hiệu y sinh (Biomedical Signal Processing)
RNN, LSTM và GRU có khả năng xử lý các tín hiệu sinh học như điện tâm đồ (ECG) và điện não đồ (EEG) để chẩn đoán các bệnh liên quan đến tim mạch và thần kinh.
5. kết luận
Recurrent Neural Networks (RNN) là một trong những phương pháp mạnh mẽ và phổ biến trong việc xử lý các loại dữ liệu tuần tự như chuỗi thời gian, văn bản, và tín hiệu âm thanh. Với khả năng duy trì trạng thái và ghi nhớ các thông tin trước đó trong chuỗi dữ liệu, RNN đã mở ra nhiều ứng dụng tiên tiến trong các lĩnh vực như xử lý ngôn ngữ tự nhiên (NLP), nhận dạng giọng nói, dự báo chuỗi thời gian, và nhiều lĩnh vực khác.
RNN cùng với LSTM và GRU vẫn là những lựa chọn quan trọng và hiệu quả cho nhiều bài toán liên quan đến dữ liệu tuần tự. Những mô hình này tiếp tục đóng vai trò then chốt trong nhiều nghiên cứu và ứng dụng thực tiễn của trí tuệ nhân tạo, từ việc cải thiện các hệ thống gợi ý, dịch máy, cho đến chăm sóc sức khỏe và sáng tạo nội dung. Trong tương lai, RNN và các biến thể của nó có thể sẽ được kết hợp với các mô hình khác để tạo ra những hệ thống thông minh, mạnh mẽ hơn.