Mạng Retinanet: cái tiến mạnh mẽ với Focal Loss
1. Giới thiệu
1.1. Phát hiện đối tượng và thị giác máy tính
Trong những thập kỷ gần đây, thị giác máy tính (Computer Vision) đã có những bước tiến vượt bậc, trở thành một trong những lĩnh vực nổi bật nhất trong trí tuệ nhân tạo (AI). Thị giác máy tính tập trung vào việc giúp máy tính “nhìn thấy” và “hiểu” hình ảnh hoặc video, từ đó đưa ra những phản hồi tương tự như cách mà con người xử lý thông tin hình ảnh. Một trong những bài toán quan trọng và đầy thách thức trong lĩnh vực này là phát hiện đối tượng (object detection).
Phát hiện đối tượng là quá trình xác định vị trí của các đối tượng cụ thể trong một hình ảnh hoặc một chuỗi video và phân loại chúng thành các danh mục xác định. Chẳng hạn, trong một hình ảnh đường phố, một hệ thống phát hiện đối tượng có thể xác định và phân loại các đối tượng như xe hơi, người đi bộ, biển báo giao thông, cây cối, v.v. Đây là một nhiệm vụ phức tạp, vì các đối tượng có thể xuất hiện với các kích thước, hình dạng, và vị trí khác nhau, thậm chí có thể bị che khuất một phần hoặc lẫn lộn trong môi trường xung quanh.
1.2. Các phương pháp phát hiện đối tượng truyền thống
Trước khi các mô hình học sâu (deep learning) như RetinaNet ra đời, phát hiện đối tượng chủ yếu dựa vào các phương pháp truyền thống như HOG (Histograms of Oriented Gradients), SIFT (Scale-Invariant Feature Transform), và các mô hình như DPM (Deformable Part Models). Những phương pháp này chủ yếu dựa vào việc trích xuất các đặc trưng cứng nhắc từ hình ảnh và sau đó áp dụng các bộ phân loại như SVM (Support Vector Machine) để phát hiện và phân loại các đối tượng.
Mặc dù các phương pháp truyền thống đã đạt được một số thành tựu nhất định, nhưng chúng có nhiều hạn chế, đặc biệt là khi làm việc với các đối tượng có độ biến đổi cao về hình dáng, màu sắc, và kích thước. Hơn nữa, các phương pháp này thường yêu cầu rất nhiều công sức để thiết kế đặc trưng và điều chỉnh thủ công, dẫn đến hiệu suất không cao và khó mở rộng cho các tập dữ liệu lớn.
1.3. Sự ra đời của các mạng phát hiện đối tượng mạnh mẽ
Sự ra đời của học sâu và đặc biệt là mạng nơ-ron tích chập (Convolutional Neural Networks – CNNs) đã thay đổi hoàn toàn cục diện của thị giác máy tính. Các mạng như AlexNet, VGGNet, và ResNet không chỉ đưa ra các phương pháp trích xuất đặc trưng tự động từ dữ liệu, mà còn đạt được những kết quả vượt trội so với các phương pháp truyền thống.
Trong lĩnh vực phát hiện đối tượng, các mô hình CNN tiên tiến như R-CNN, Fast R-CNN, và Faster R-CNN đã tạo nên những cột mốc quan trọng. Các mô hình này sử dụng CNN để trích xuất các đặc trưng từ hình ảnh và áp dụng thêm các lớp phát hiện để xác định vị trí và phân loại các đối tượng. Tuy nhiên, mặc dù độ chính xác cao, các mô hình này thường đòi hỏi thời gian tính toán lớn và không thích hợp cho các ứng dụng thời gian thực.
1.4. Mạng RetinaNet
Được giới thiệu vào năm 2017, RetinaNet là một bước đột phá quan trọng trong lĩnh vực phát hiện đối tượng. Mạng này được phát triển bởi Tsung-Yi Lin và các đồng nghiệp tại Facebook AI Research (FAIR), với mục tiêu giải quyết vấn đề mất cân bằng trong dữ liệu và tối ưu hóa sự cân bằng giữa độ chính xác và tốc độ trong phát hiện đối tượng.
2. Kiến trúc của RetinaNet
Kiến trúc của RetinaNet là sự kết hợp của nhiều cải tiến từ các mạng trước đó, đồng thời đưa ra những ý tưởng mới để cải thiện hiệu suất.
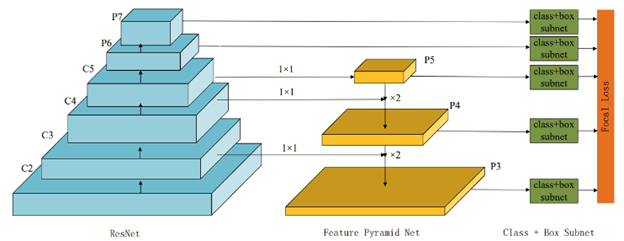
Kiến trúc của RetinaNet có thể được chia thành ba phần chính:
2.1. Backbone (Xương sống)
Backbone là phần chính của mạng, nơi mà các đặc trưng hình ảnh được trích xuất. Trong RetinaNet, các mạng CNN sâu như ResNet-50 hoặc ResNet-101 thường được sử dụng làm backbone. Những mạng này đã được huấn luyện trước trên các tập dữ liệu lớn như ImageNet, cho phép chúng có khả năng trích xuất các đặc trưng phong phú và đa dạng từ hình ảnh.
ResNet là một mạng sâu với nhiều lớp tích chập (convolutional layers) được sắp xếp theo cách mà các kết nối từ các lớp trước đó có thể bỏ qua (skip) một hoặc nhiều lớp trung gian, nhờ vào các kết nối residual. Điều này giúp giảm thiểu vấn đề biến mất gradient (vanishing gradient) trong quá trình huấn luyện và cho phép xây dựng các mạng sâu hơn mà vẫn duy trì hiệu suất cao.
2.2. Feature Pyramid Network (FPN)

Một cải tiến quan trọng trong RetinaNet là việc sử dụng mạng kim tự tháp đặc trưng (Feature Pyramid Network – FPN). FPN giúp kết hợp thông tin từ các cấp độ khác nhau trong mạng backbone. Điều này rất quan trọng vì các đối tượng trong hình ảnh thường xuất hiện với nhiều kích thước khác nhau. Một đối tượng lớn có thể được nhận diện dễ dàng ở các cấp độ cao của mạng (các lớp sau), trong khi các đối tượng nhỏ hơn lại yêu cầu thông tin từ các cấp độ thấp hơn (các lớp đầu).
FPN tạo ra một hệ thống kim tự tháp, nơi mà các đặc trưng từ các tầng khác nhau được kết hợp lại, giúp mạng có thể nhận diện các đối tượng ở nhiều kích thước và tỷ lệ khác nhau một cách hiệu quả.
2.3. Đầu ra phát hiện (Detection Head)
RetinaNet sử dụng hai loại đầu ra chính: một đầu ra để phân loại các đối tượng và một đầu ra để dự đoán các hộp giới hạn (bounding boxes) cho các đối tượng. Cả hai đầu ra này đều được áp dụng trên mỗi cấp độ của FPN, giúp mạng có khả năng phát hiện các đối tượng ở nhiều tỷ lệ khác nhau.
Cụ thể, mỗi điểm trong các đặc trưng của FPN sẽ được gán với một hộp giới hạn cố định (anchor boxes) với các tỷ lệ và kích thước khác nhau. Mỗi anchor sẽ được kiểm tra để xác định xem nó có chứa đối tượng hay không và nếu có, loại đối tượng đó là gì. Điều này cho phép RetinaNet có thể phát hiện các đối tượng với độ chính xác cao trong một khoảng thời gian ngắn.
2.4. Focal Loss
Một trong những thách thức lớn nhất trong phát hiện đối tượng là việc xử lý các tập dữ liệu mất cân bằng, nơi mà số lượng các mẫu nền (background) chiếm ưu thế so với số lượng các đối tượng cần phát hiện. Điều này dẫn đến các mô hình truyền thống như Faster R-CNN hoặc SSD thường bỏ qua các đối tượng nhỏ hoặc hiếm gặp, do chúng chiếm tỷ lệ nhỏ trong toàn bộ tập dữ liệu.
Để giải quyết vấn đề này, RetinaNet giới thiệu một hàm mất mát mới gọi là Focal Loss. Focal Loss được thiết kế để làm giảm ảnh hưởng của các mẫu dễ (như nền) và tập trung vào việc học các mẫu khó (như các đối tượng nhỏ hoặc hiếm gặp).
Focal Loss là một biến thể của hàm Cross-Entropy Loss truyền thống, với một trọng số thêm vào để làm giảm ảnh hưởng của các mẫu dễ dàng phân loại. Hàm mất mát này có thể được biểu diễn như sau:

Focal Loss giúp giảm thiểu vấn đề mất cân bằng dữ liệu bằng cách tập trung vào các mẫu khó hơn, từ đó cải thiện hiệu suất của mạng trong việc phát hiện các đối tượng nhỏ hoặc ít xuất hiện.
3. Hiệu suất của RetinaNet
Mạng RetinaNet đã tạo ra một cú sốc trong cộng đồng nghiên cứu thị giác máy tính với hiệu suất vượt trội trong phát hiện đối tượng. Để hiểu rõ hơn về hiệu suất của RetinaNet, chúng ta sẽ phân tích các khía cạnh chính như độ chính xác, tốc độ, và ứng dụng thực tiễn của nó.
3.1. Độ chính xác
RetinaNet đã đạt được những kết quả ấn tượng trên nhiều tập dữ liệu tiêu chuẩn trong lĩnh vực phát hiện đối tượng. Một trong những tập dữ liệu nổi bật mà RetinaNet được thử nghiệm là COCO (Common Objects in Context). Tập dữ liệu COCO chứa hàng trăm ngàn hình ảnh với hơn 80 loại đối tượng khác nhau, bao gồm các đối tượng có kích thước khác nhau, bị che khuất và nằm trong các cảnh phức tạp.
- Precision and Recall: RetinaNet đạt được điểm số mAP (mean Average Precision) cao, đặc biệt là trong việc phát hiện các đối tượng nhỏ và ít xuất hiện. Với Focal Loss, RetinaNet có khả năng tập trung vào các đối tượng khó phát hiện hơn, từ đó cải thiện độ chính xác trong các tình huống khó khăn. Trên tập dữ liệu COCO, RetinaNet đã đạt được một trong những điểm số mAP cao nhất trong các mô hình phát hiện đối tượng, đặc biệt là khi so với các mạng trước đó như Faster R-CNN và SSD.
- Khả năng phát hiện các đối tượng nhỏ và hiếm: Focal Loss giúp RetinaNet làm giảm ảnh hưởng của các đối tượng dễ phát hiện (như nền) và tập trung vào các đối tượng khó hơn. Điều này giúp cải thiện khả năng phát hiện các đối tượng nhỏ và hiếm gặp, vốn là một thách thức lớn trong nhiều mô hình phát hiện đối tượng khác.
3.2. Hiệu suất so với các mô hình khác
- So Với Faster R-CNN: Mặc dù Faster R-CNN nổi tiếng với độ chính xác cao, nó thường gặp khó khăn trong việc duy trì tốc độ xử lý cao trên các tập dữ liệu lớn. RetinaNet, với Focal Loss và kiến trúc FPN, không chỉ cải thiện độ chính xác mà còn duy trì tốc độ xử lý cao hơn, làm cho nó trở thành một lựa chọn hấp dẫn cho các ứng dụng thời gian thực.
- So Với SSD (Single Shot MultiBox Detector): SSD là một mô hình nổi bật với khả năng phát hiện nhanh chóng, nhưng nó thường gặp khó khăn trong việc phát hiện các đối tượng nhỏ và hiếm gặp. RetinaNet vượt trội hơn trong việc xử lý các đối tượng nhỏ nhờ vào cách tiếp cận Focal Loss và kiến trúc FPN, cung cấp độ chính xác cao hơn trong khi vẫn duy trì tốc độ xử lý cạnh tranh.
4. Ưu điểm
4.1. Tốc độ xử lý
Một trong những ưu điểm lớn của RetinaNet là khả năng duy trì tốc độ xử lý cao trong khi vẫn đạt được độ chính xác vượt trội. Mặc dù các mô hình như Faster R-CNN có thể cung cấp độ chính xác cao, nhưng chúng thường yêu cầu thời gian tính toán lớn, làm giảm khả năng xử lý thời gian thực.
4.2. Khả năng xử lý thời gian thực
RetinaNet với kiến trúc FPN và các cải tiến khác cho phép nó xử lý hình ảnh với tốc độ nhanh, điều này rất quan trọng cho các ứng dụng yêu cầu thời gian thực như hệ thống giám sát an ninh, xe tự lái, và phân tích video thời gian thực.
4.3. Tối ưu hóa tính toán
RetinaNet đã được tối ưu hóa để làm việc hiệu quả trên các GPU hiện đại. Việc sử dụng các mạng CNN sâu như ResNet làm backbone giúp cải thiện khả năng xử lý, đồng thời kiến trúc FPN cũng giúp tăng hiệu suất tính toán mà không làm giảm độ chính xác.
5. Ứng dụng của RetinaNet
RetinaNet, với khả năng phát hiện đối tượng chính xác và hiệu quả, đã chứng minh sự hữu ích của nó trong nhiều lĩnh vực khác nhau. Dưới đây là những ứng dụng nổi bật của RetinaNet trong các lĩnh vực thực tiễn:
5.1. Giám sát an ninh
Trong lĩnh vực giám sát an ninh, RetinaNet là một công cụ mạnh mẽ cho việc phát hiện và theo dõi các hành vi bất thường. Nhờ vào khả năng phát hiện đối tượng nhỏ và hiếm gặp, RetinaNet có thể nhận diện các tình huống nguy hiểm trong video giám sát, chẳng hạn như:
- Phát hiện vũ khí: RetinaNet có thể nhận diện các đối tượng như vũ khí hoặc thiết bị nguy hiểm trong các khu vực công cộng, giúp các hệ thống an ninh phản ứng kịp thời.
- Phát hiện hành vi bất thường: Mô hình có thể phân tích hành vi của người trong video, phát hiện các hành vi nghi ngờ hoặc hành động bất thường, từ đó giúp các cơ quan an ninh có biện pháp xử lý nhanh chóng.
5.2. Y tế
Trong ngành y tế, RetinaNet đóng vai trò quan trọng trong việc phân tích và phát hiện các bất thường trong các ảnh y tế, giúp cải thiện chẩn đoán và chăm sóc sức khỏe. Một số ứng dụng cụ thể bao gồm:
- Phát hiện tổn thương trong ảnh X-quang và MRI: RetinaNet có khả năng phát hiện các tổn thương nhỏ, chẳng hạn như khối u hoặc các dấu hiệu của bệnh lý trong ảnh X-quang và MRI. Điều này giúp các bác sĩ đưa ra chẩn đoán sớm và chính xác hơn.
- Phân tích ảnh sinh học: Trong nghiên cứu y học, mô hình có thể phân tích các ảnh sinh học, phát hiện các biến thể trong cấu trúc tế bào, từ đó hỗ trợ nghiên cứu và phát triển các phương pháp điều trị mới.
5.3. Xe tự lái
RetinaNet đóng vai trò quan trọng trong các hệ thống điều khiển xe tự lái nhờ khả năng phát hiện các đối tượng và chướng ngại vật trên đường. Các ứng dụng bao gồm:
- Phát hiện người đi bộ và xe cộ: Mô hình có thể nhận diện và theo dõi người đi bộ, xe cộ, và các chướng ngại vật khác trên đường, từ đó giúp hệ thống điều khiển xe tự lái điều chỉnh hành vi một cách an toàn.
- Xử lý cảnh bị che khuất: RetinaNet có khả năng xử lý các tình huống khó khăn như đối tượng bị che khuất một phần, giúp cải thiện sự an toàn trong việc lái xe tự động.
5.4. Thương mại điện tử
Trong lĩnh vực thương mại điện tử, RetinaNet có thể cải thiện trải nghiệm người dùng và quản lý hàng tồn kho:
- Phát hiện sản phẩm trong ảnh: Mô hình có thể nhận diện và phân loại các sản phẩm trong ảnh, giúp cải thiện quá trình tìm kiếm và gợi ý sản phẩm cho người tiêu dùng.
- Quản lý hàng tồn kho: RetinaNet có thể giúp quản lý hàng tồn kho bằng cách phát hiện và theo dõi số lượng sản phẩm trong các kho hàng hoặc cửa hàng trực tuyến.
5.5. Nông nghiệp
Trong nông nghiệp, RetinaNet có thể hỗ trợ trong việc theo dõi và phân tích cây trồng và vật nuôi:
- Theo dõi sâu bệnh và cây cối: Mô hình có thể phát hiện các bệnh tật hoặc sâu bệnh trên cây trồng từ các ảnh vệ tinh hoặc ảnh chụp trên mặt đất, giúp nông dân đưa ra các biện pháp phòng ngừa và điều trị kịp thời.
- Quản lý vật nuôi: RetinaNet có thể theo dõi và phân loại các vật nuôi trong trang trại, giúp quản lý tốt hơn và đảm bảo sức khỏe cho vật nuôi.
5.6. Giải trí và truyền thông
Trong ngành giải trí và truyền thông, RetinaNet có thể được sử dụng để cải thiện các trải nghiệm người dùng:
- Tạo nội dung tự động: Mô hình có thể giúp tự động phân loại và gắn thẻ nội dung video hoặc hình ảnh, từ đó hỗ trợ các hệ thống quản lý nội dung và cải thiện khả năng tìm kiếm.
- Phân tích nội dung video: RetinaNet có thể phân tích nội dung video để nhận diện các đối tượng, hành động, hoặc cảnh cụ thể, giúp cải thiện các dịch vụ phát trực tuyến và phân tích video.
5.7. Nghiên cứu và phát triển
Trong nghiên cứu khoa học và phát triển công nghệ, RetinaNet có thể hỗ trợ trong việc:
- Khám phá khoa học: Mô hình có thể được sử dụng để phân tích dữ liệu từ các thí nghiệm khoa học, chẳng hạn như phát hiện các đối tượng trong ảnh từ kính hiển vi hoặc dữ liệu hình ảnh từ các nghiên cứu thiên văn học.
- Phát triển công nghệ mới: RetinaNet có thể đóng vai trò quan trọng trong việc phát triển và thử nghiệm các công nghệ mới, từ các mô hình máy học đến các ứng dụng thực tế.
6. Kết luận
RetinaNet đã chứng minh là một mô hình phát hiện đối tượng mạnh mẽ với hiệu suất vượt trội trong cả độ chính xác và tốc độ. Với khả năng xử lý các đối tượng nhỏ và hiếm gặp, cùng với tốc độ xử lý nhanh chóng, RetinaNet đã trở thành một công cụ quan trọng trong nhiều ứng dụng thực tiễn như giám sát an ninh, y tế, và xe tự lái.
Mặc dù còn một số hạn chế, các cải tiến liên tục trong nghiên cứu và phát triển hứa hẹn sẽ giúp RetinaNet duy trì vị thế của nó trong lĩnh vực phát hiện đối tượng và mở rộng khả năng ứng dụng trong tương lai.