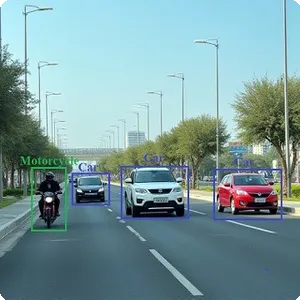
Ứng dụng mạng RetinaNet vào nhận diện đối tượng
1. Bài toán
Xây dựng một hệ thống phát hiện và nhận diện đối tượng dựa trên mạng neural RetinaNet. Hệ thống này sẽ xác định đối tượng bằng cách khoanh hình chữ nhật bao quanh đối tượng và hiển thị tên của đối tượng, sau đó lưu lại hình ảnh đã có thông tin này.
2. Thực hiện
2.1. Cấu trúc chương trình
Với mục đích dễ quản lý source code, chúng ta có thể đặt chương trình như sau:
root@aicandy:/aicandy/projects/AIcandy_RetinaNet_ObjectDetection_mqeprgnq# tree
.
├── aicandy_output_ntroyvui
│ └── aicandy_pretrain_resnet_rvkndbxy.pth
├── aicandy_retinanet_test_cliaskyp.py
├── aicandy_retinanet_train_rpnekclt.py
├── aicandy_utils_src_obilenxc
│ ├── anchors.py
│ ├── arial.ttf
│ ├── evaluate.py
│ ├── dataloader.py
│ ├── losses.py
│ └── model.py
└── image_test.jpg
Trong đó:
– File model.py chứa model RetinaNet
– File aicandy_retinanet_train_rpnekclt.py chứa chương trình train
– File aicandy_retinanet_test_cliaskyp.py chứa chương trình để test.
– Các file trong aicandy_utils_src_obilenxc chứa các hàm tính toán loss, xác định bounding box của đối tượng.
2.2. Dữ liệu
Dữ liệu phục vụ cho việc train và validate được sử dụng theo cấu trúc bộ dữ liệu COCO. Trong bài này, tôi sử dụng một phần của bộ dữ liệu COCO2017, thực hiện train và validate trên 1 bộ đối tượng motorcycle. Khi train với nhiều bộ đối tượng thì chỉ cần bổ sung thêm dataset mà không cần thay đổi chương trình.
Bộ dataset có cấu trúc như sau:
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy# ls
annotations train2017 val2017
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy# ls annotations/
instances_train2017.json instances_val2017.json
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy#
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy# cd train2017/
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy/train2017# tree | head -n 6
.
├── 000000000073.jpg
├── 000000000086.jpg
├── 000000000529.jpg
├── 000000000629.jpg
├── 000000000656.jpg
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy/train2017# cd ../val2017/
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy/val2017# tree | head -n 6
.
├── 000000007386.jpg
├── 000000007816.jpg
├── 000000008211.jpg
├── 000000011149.jpg
├── 000000011511.jpg
root@aicandy:/aicandy/datasets/aicandy_motorcycle_humukdiy/val2017#Bộ dữ liệu sử dụng trong bài là bộ aicandy_motorcycle_humukdiy được download miễn phí tại Kho dữ liệu dành cho học máy
2.3. Build model
Xây dựng mô hình với mạng resnet là mạng cơ sở gồm các thành phần chính:
class BasicBlock(nn.Module):
Tạo BasicBlock cơ bản có 2 lớp tích chập có kích thước 3×3, tiếp sau là chuẩn hóa cho đầu ra của lớp tích chập và sau đó là hàm kích hoạt ReLU.
class Bottleneck(nn.Module):
Lớp Bottleneck được thiết kế để tăng hiệu quả tính toán bằng cách giảm số lượng kênh trước khi áp dụng phép tích chập có kích thước lớn hơn, sau đó mở rộng trở lại số kênh ban đầu. Đây là một cách tiếp cận hiệu quả để giảm bớt độ phức tạp tính toán trong các mạng sâu.
Tạo 3 lớp tích chập, lớp thứ nhất có kích thước nhân 1×1 để giảm số lượng kênh đầu vào, giảm độ phức tạp tính toán. Lớp thứ hai có kích thước nhân 3×3 để trích xuất đặc trưng từ dữ liệu. Lớp thứ 3 để mở rộng số lượng kênh đầu vào. Sau đó sử dụng hàm Relu để thêm tính phi tuyến cho mô hình.
class BBoxTransform(nn.Module):
Tạo lớp BBoxTransform để thực hiện biến đổi trên các bounding box dựa trên các giá trị mean và std.
class ClipBoxes(nn.Module):
Lớp ClipBoxes được sử dụng trong các mô hình phát hiện đối tượng để đảm bảo rằng các bounding boxes (hộp giới hạn) dự đoán nằm hoàn toàn trong giới hạn của hình ảnh. Khi một mô hình dự đoán vị trí của một hộp giới hạn, có thể xảy ra trường hợp một phần của hộp nằm ngoài biên của hình ảnh. Lớp ClipBoxes sẽ điều chỉnh lại các tọa độ của hộp sao cho chúng không vượt ra ngoài các biên của ảnh.
class PyramidFeatures(nn.Module):
Lớp PyramidFeatures được thiết kế để thực hiện trích xuất đặc trưng từ các tầng khác nhau của một mạng nơ-ron tích chập (CNN) sử dụng kiến trúc Feature Pyramid Network (FPN).
FPN là một kiến trúc kết hợp các đặc trưng từ các tầng khác nhau của mạng CNN. Điều này giúp cải thiện khả năng phát hiện đối tượng ở nhiều kích thước khác nhau.
class RegressionModel(nn.Module):
Lớp RegressionModel được thiết kế để dự đoán các hộp giới hạn (bounding boxes) cho các đối tượng trong bài toán phát hiện đối tượng.
Cấu trúc của nó bao gồm bốn lớp tích chập liên tiếp với các hàm kích hoạt ReLU để trích xuất và tinh chỉnh các đặc trưng từ đầu vào. Lớp cuối cùng là một lớp tích chập có nhiệm vụ dự đoán tọa độ của các hộp giới hạn cho các anchor boxes.
class ClassificationModel(nn.Module):
Lớp ClassificationModel được thiết kế để thực hiện phân loại đối tượng cho từng anchor box trong bài toán phát hiện đối tượng.
Cấu trúc của lớp này bao gồm bốn lớp tích chập liên tiếp với các hàm kích hoạt ReLU để trích xuất và tinh chỉnh các đặc trưng từ đầu vào. Lớp cuối cùng là một lớp tích chập có nhiệm vụ phân loại đối tượng cho các anchor boxes.
class ResNet(nn.Module):
Lớp ResNet xây dựng một mạng nơ-ron dựa trên kiến trúc Residual Network, bao gồm các khối residual được xếp chồng lên nhau để trích xuất đặc trưng từ hình ảnh đầu vào.
Các tầng residual sử dụng các khối block để cải thiện khả năng học của mạng bằng cách cho phép gradient truyền ngược qua các lớp mà không bị suy giảm quá nhiều (gradient vanishing problem).
Các tầng residual này thường có stride 2 để giảm kích thước đặc trưng không gian và tăng số lượng kênh, giúp mạng học các đặc trưng ở nhiều mức độ khác nhau.
2.4. Chương trình train
Bước 1: Load dataset vào tập train và tập validate
dataset_train = CocoDataset(train_dir, set_name=’train2017′,
transform=transforms.Compose([Normalizer(), Augmenter(), Resizer()]))
dataset_val = CocoDataset(train_dir, set_name=’val2017′,
transform=transforms.Compose([Normalizer(), Resizer()]))
- Normalizer(): Chuẩn hóa các giá trị pixel của hình ảnh, chuẩn hóa theo các giá trị trung bình và độ lệch chuẩn.
- Augmenter(): Thực hiện các kỹ thuật tăng cường dữ liệu như xoay, dịch chuyển, thay đổi độ sáng, tương phản, hoặc lật ảnh. Mục đích là để tạo ra sự biến thể trong dữ liệu huấn luyện, giúp mạng học được các đặc trưng mạnh mẽ hơn và cải thiện khả năng tổng quát.
- Resizer(): Thực hiện việc thay đổi kích thước hình ảnh về kích thước cố định. Việc thay đổi kích thước thường là cần thiết để đưa tất cả các hình ảnh về cùng một kích thước đầu vào cho mạng nơ-ron.
sampler_train = AspectRatioBasedSampler(dataset_train, batch_size=batch_size, drop_last=False)
AspectRatioBasedSampler: được thiết kế để tối ưu hóa kích thước của các batch dữ liệu sao cho các ảnh trong cùng một batch có tỷ lệ khung hình tương tự nhau. Điều này giúp giảm thiểu số lượng ảnh cần phải padding (thêm viền) để đảm bảo kích thước đồng nhất trong một batch, từ đó cải thiện hiệu quả và hiệu suất của quá trình huấn luyện.
Bước 2: Khởi tạo model và load model lên ‘GPU’ (nếu có)
retinanet = model.create_base_resnet(num_classes=dataset_train.num_classes())
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
retinanet = retinanet.to(device)
Bước 3: Tính toán hàm mất mát và tối ưu
optimizer = optim.Adam(retinanet.parameters(), lr=1e-5)
optim.Adam: Đây là một thuật toán tối ưu hóa được sử dụng để cập nhật trọng số của mô hình trong quá trình huấn luyện. Adam (Adaptive Moment Estimation) là một thuật toán tối ưu hóa dựa trên gradient, kết hợp các ý tưởng từ Momentum và AdaGrad. Nó điều chỉnh tỷ lệ học (learning rate) cho mỗi trọng số dựa trên các ước lượng trung bình và phương sai của các gradient.
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience=3, verbose=True)
optim.lr_scheduler.ReduceLROnPlateau: Đây là một trình lập lịch tỷ lệ học (learning rate scheduler) giúp điều chỉnh tỷ lệ học tự động trong quá trình huấn luyện. Lớp này giảm tỷ lệ học khi hiệu suất của mô hình không cải thiện.
optimizer.zero_grad()
optimizer.zero_grad() đảm bảo rằng trước khi tính toán gradient mới cho một bước huấn luyện, các giá trị gradient cũ không còn ảnh hưởng đến phép toán mới. Điều này rất quan trọng để đảm bảo rằng các gradient được tính toán chính xác cho từng batch dữ liệu và không bị ảnh hưởng bởi các phép toán trước đó.
Bước 4: Đánh giá mô hình
scores, labels, boxes = model(data[‘img’].permute(2, 0, 1).cuda().float().unsqueeze(dim=0))
permute(2, 0, 1) chuyển đổi tensor từ định dạng (H, W, C) thành (C, H, W). Đây là định dạng yêu cầu cho các mô hình trong PyTorch, vì các mô hình thường yêu cầu đầu vào có thứ tự chiều (C, H, W).
unsqueeze(dim=0):Thêm một chiều mới ở vị trí dim=0. Điều này có nghĩa là biến đổi tensor từ kích thước (C, H, W) thành (1, C, H, W). Chiều mới này đại diện cho kích thước của batch, trong đó 1 là số lượng hình ảnh trong batch. Đây là định dạng yêu cầu cho các mô hình PyTorch khi xử lý nhiều hình ảnh cùng lúc, ngay cả khi bạn chỉ có một hình ảnh trong batch.
coco_eval.evaluate()
Thực hiện đánh giá các dự đoán so với nhãn thực tế. Phương thức này sẽ tính toán các chỉ số đánh giá như Precision, Recall, mAP (mean Average Precision), và các chỉ số khác liên quan đến chất lượng của các dự đoán.
coco_eval.accumulate()
Tính toán các số liệu tổng hợp từ kết quả đánh giá. Phương thức này tổng hợp các kết quả đánh giá cho từng hình ảnh để tính toán các chỉ số cuối cùng.
coco_eval.summarize()
In ra các báo cáo và tóm tắt kết quả đánh giá. Phương thức này sẽ in ra các chỉ số tổng hợp như mAP và các thông tin liên quan khác, giúp bạn hiểu hiệu suất của mô hình.
Bước 5: Lưu model
print(‘Epoch: {}/{} Running loss: {:1.5f}’.format(epoch_num + 1, epochs, running_loss))
if running_loss < running_loss_best:
running_loss_best = running_loss
torch.save(retinanet.state_dict(), model_path)
Trong mỗi epoch, kiểm tra xem kết quả sai số có được cải thiện không, nếu cải thiện thì lưu lại model.
2.5. Chương trình test
Bước 1: Load thông tin đối tượng chứa trong labels.txt
with open(label_path, ‘r’) as f:
labels = {int(line.split(“: “)[0]): line.split(“: “)[1].strip() for line in f}
Mục đích của bước này là xác định các đối tượng đã được train trong model.
Bước 2: Khởi tạo và load model
model = ResNet(len(labels), BasicBlock, [2, 2, 2, 2])
model.load_state_dict(torch.load(model_path, map_location=device))
Khởi tạo model có cấu trúc giống với cấu trúc model khi train dữ liệu.
model.load_state_dict() tải trọng số đã huấn luyện trước đó vào mô hình
Bước 3: Load ảnh và hiệu chỉnh ảnh để phù hợp với model
image = cv2.imread(image_path)
Sử dụng thư viện openCV để đọc ảnh và image
image = cv2.resize(image, (int(round(cols * scale)), int(round((rows * scale)))))
Resize lại ảnh đầu vào cho phù hợp với kích thước yêu cầu của model.
image = np.transpose(image, (0, 3, 1, 2))
Thay đổi thứ tự các chiều của mảng từ (batch, height, width, channels) thành (batch, channels, height, width) để phù hợp với định dạng đầu vào của PyTorch.
Bước 4: Dự đoán và lưu ảnh
scores, classification, transformed_anchors = model(image.float())
scores: Điểm số này cho biết độ tin cậy của mô hình trong việc dự đoán một đối tượng ở một vùng cụ thể của ảnh.
classification: mỗi đối tượng trong ảnh sẽ được gán một lớp dự đoán từ các lớp có thể có.
transformed_anchors là các hình chữ nhật cố định mà mô hình sử dụng để dự đoán vị trí và kích thước của các đối tượng trong ảnh.
cv2.rectangle(image_orig, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
Thực hiện vẽ khung chữ nhật để đánh dấu đối tượng có trong ảnh.
cv2.imwrite(output_path, image_orig)
Lưu ảnh đã bổ sung thông tin theo đường dẫn ảnh mới.
3. Kết quả train
Thực hiện train với epoch 100, độ sai số thấp nhất là 0.06982, đạt được ở epoch 99. Đây là chương trình mẫu, để tăng độ chính xác, chúng ta cũng cần điều chỉnh thêm một số tham số, tăng epoch cũng như tăng số lượng mẫu. Thông tin về bộ chỉ số IOU ở 5 epoch cuối như sau:
Epoch: 95/100 Running loss: 0.07242
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.14s).
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.303
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.621
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.278
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.121
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.217
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.514
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.228
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.351
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.370
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.160
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.288
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.593
Epoch: 96/100 Running loss: 0.07080
Saved model with loss: 0.07079677626118064
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.14s).
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.310
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.629
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.264
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.122
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.221
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.521
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.234
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.358
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.376
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.170
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.301
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.591
Epoch: 97/100 Running loss: 0.07173
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.14s).
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.312
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.630
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.284
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.115
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.239
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.520
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.230
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.361
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.378
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.145
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.322
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.591
Epoch: 98/100 Running loss: 0.07078
Saved model with loss: 0.07078446097113192
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.15s).
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.314
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.630
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.285
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.128
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.239
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.516
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.231
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.355
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.381
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.159
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.317
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.594
Epoch: 99/100 Running loss: 0.06982
Saved model with loss: 0.0698248950317502
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.21s).
Accumulating evaluation results...
DONE (t=0.03s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.309
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.637
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.267
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.118
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.230
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.518
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.228
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.357
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.376
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.159
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.308
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.591
Epoch: 100/100 Running loss: 0.07061
root@aicandy:/aicandy/projects/AIcandy_RetinaNet_ObjectDetection_mqeprgnq#4. Kết quả test
Thử nghiệm với một số ảnh, chương trình đã xác định vị trí tốt đối tượng motorcycle có trong ảnh.

root@aicandy:/aicandy/projects/AIcandy_RetinaNet_ObjectDetection_mqeprgnq# python aicandy_retinanet_test_cliaskyp.py --image_path image_test.jpg --model_path 'aicandy_output_ntroyvui/aicandy_model_retina_lgkrymnl.pth' --class_list labels.txt --output_path aicandy_output_ntroyvui/image_out.jpg
image_test.jpg
torch.Size([1, 3, 640, 928]) (427, 640, 3) 1.423887587822014
Elapsed time: 0.06023120880126953
tensor([342.3197, 246.7439, 859.4058, 577.5422], device='cuda:0') torch.Size([1])
Saved image to aicandy_output_ntroyvui/image_out.jpg
root@aicandy:/aicandy/projects/AIcandy_RetinaNet_ObjectDetection_mqeprgnq#
5. Source code
Toàn bộ source code được public miễn phí tại đây