Support Vector Machine (SVM): xử lý dữ liệu phi tuyến
1. Giới thiệu
Trong học máy, việc phân tích và xử lý dữ liệu là một yếu tố quan trọng để xây dựng các mô hình dự đoán. Một trong những khía cạnh phức tạp nhất của dữ liệu là đặc tính phi tuyến tính. Dữ liệu phi tuyến tính đặt ra nhiều thách thức cho các mô hình học máy tuyến tính truyền thống.
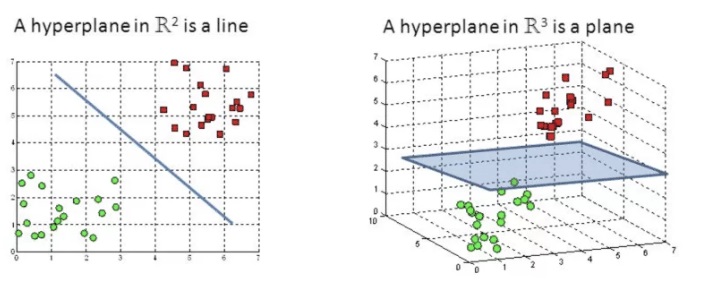
Dữ liệu tuyến tính
Dữ liệu tuyến tính là dữ liệu có thể phân tách bằng một đường thẳng (trong không gian 2D) hoặc một siêu phẳng (trong không gian nhiều chiều). Nói cách khác, các lớp dữ liệu có thể được chia tách một cách rõ ràng bằng một hàm tuyến tính.
Dữ liệu phi tuyến tính
Dữ liệu phi tuyến tính là dữ liệu mà các lớp không thể phân tách bằng một đường thẳng hoặc siêu phẳng. Trong trường hợp này, việc sử dụng các mô hình tuyến tính sẽ không hiệu quả. Các điểm dữ liệu có thể tạo thành các hình dạng phức tạp như vòng tròn, xoắn ốc, hoặc các bề mặt phi tuyến.
Support Vector Machine (SVM)
Support Vector Machine (SVM) là một thuật toán học máy thuộc loại supervised learning, được sử dụng chủ yếu cho các bài toán phân loại và hồi quy. Ý tưởng chính của SVM là tìm ra một siêu phẳng (hyperplane) tối ưu để phân tách các lớp dữ liệu. Trong không gian hai chiều, siêu phẳng này là một đường thẳng, còn trong không gian nhiều chiều, đó là một mặt phẳng hoặc một siêu phẳng.
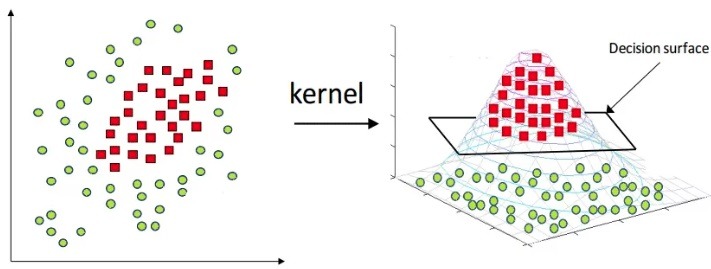
Trong trường hợp dữ liệu không thể phân tách tuyến tính (dữ liệu phi tuyến tính), SVM sử dụng kỹ thuật kernel để chuyển dữ liệu từ không gian gốc sang một không gian đặc trưng cao hơn, nơi dữ liệu có thể trở thành tuyến tính. Thay vì tính toán trực tiếp các tọa độ mới, SVM sử dụng một hàm kernel để tính toán sản phẩm vô hướng trong không gian đặc trưng đó.
2. Nguyên lý hoạt động
2.1. SVM cho bài toán tuyến tính
Khi dữ liệu là tuyến tính, nghĩa là có thể phân tách các lớp dữ liệu bằng một đường thẳng (trong không gian 2D) hoặc một siêu phẳng (trong không gian nhiều chiều), SVM sẽ tìm cách xác định siêu phẳng này sao cho nó có margin (khoảng cách) lớn nhất giữa các lớp dữ liệu. Điều này giúp tối ưu hóa khả năng phân loại và giảm thiểu lỗi phân loại.
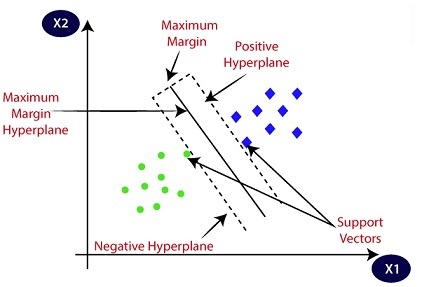
Giả sử chúng ta có một tập dữ liệu với hai lớp, trong đó mỗi điểm dữ liệu \( \mathbf{x}_i \) thuộc về một trong hai lớp \( y_i \in \{-1, 1\} \).
Mục tiêu của SVM là tìm ra siêu phẳng dưới dạng:
\[\mathbf{w}^T \mathbf{x} + b = 0\]
Trong đó, \( \mathbf{w} \) là vector trọng số và \( b \) là bias. Siêu phẳng này phải đảm bảo phân tách hai lớp dữ liệu một cách chính xác, nghĩa là:
\[y_i (\mathbf{w}^T \mathbf{x}_i + b) \geq 1, \forall i\]
Khoảng cách từ một điểm dữ liệu đến siêu phẳng được tính bằng công thức:
\[\frac{| \mathbf{w}^T \mathbf{x} + b |}{\|\mathbf{w}\|}\]
SVM sẽ tìm cách tối ưu hóa trọng số \( \mathbf{w} \) và bias \( b \) sao cho margin (khoảng cách giữa hai lớp) là lớn nhất. Các điểm dữ liệu gần siêu phẳng nhất được gọi là support vectors, và chính các điểm này đóng vai trò quan trọng trong việc xác định siêu phẳng phân loại.
Bài toán SVM tuyến tính được biểu diễn như một bài toán tối ưu hóa, với mục tiêu là tối ưu hóa margin giữa các lớp. Ta cần cực tiểu hóa hàm mục tiêu sau:
\[\min_{\mathbf{w}, b} \frac{1}{2} \|\mathbf{w}\|^2\]
với các ràng buộc:
\[y_i (\mathbf{w}^T \mathbf{x}_i + b) \geq 1, \forall i\]
Hàm mục tiêu \( \frac{1}{2} \|\mathbf{w}\|^2 \) nhằm tối thiểu hóa độ lớn của vector trọng số \( \mathbf{w} \), tức là tối đa hóa khoảng cách margin. Bài toán này có thể được giải bằng cách sử dụng các kỹ thuật tối ưu hóa bậc hai (Quadratic Programming).
2.2. SVM với Soft Margin
Trong thực tế, dữ liệu có thể không hoàn toàn tuyến tính và đôi khi có nhiễu, dẫn đến việc không thể phân tách chính xác các lớp dữ liệu bằng một siêu phẳng. Để giải quyết vấn đề này, SVM tuyến tính sử dụng một biến số slack \( \xi_i \) để cho phép một số điểm dữ liệu nằm trong margin hoặc bị phân loại sai. Mô hình này được gọi là Soft Margin SVM.
Bài toán tối ưu hóa của Soft Margin SVM được viết lại như sau:
\[\min_{\mathbf{w}, b, \xi} \frac{1}{2} \|\mathbf{w}\|^2 + C \sum_{i=1}^{n} \xi_i\]
với các ràng buộc:
\[y_i (\mathbf{w}^T \mathbf{x}_i + b) \geq 1 – \xi_i, \forall i\quad \text{và} \quad \xi_i \geq 0\]
Trong đó, \( C \) là một tham số điều chỉnh, giúp cân bằng giữa việc tối thiểu hóa lỗi phân loại và tối đa hóa margin. Khi \( C \) lớn, mô hình sẽ cố gắng giảm thiểu lỗi phân loại, nhưng có thể dẫn đến overfitting. Ngược lại, khi \( C \) nhỏ, mô hình sẽ tập trung vào việc tối đa hóa margin nhưng có thể chấp nhận một số lỗi phân loại.
2.3. Kỹ thuật Kernel: Giải quyết vấn đề phi tuyến tính
Kỹ thuật kernel là phương pháp chính để mở rộng SVM từ các vấn đề tuyến tính sang phi tuyến tính. Ý tưởng chính là biến đổi dữ liệu từ không gian ban đầu thành một không gian đặc trưng có chiều cao hơn, nơi dữ liệu có thể được phân tách tuyến tính.
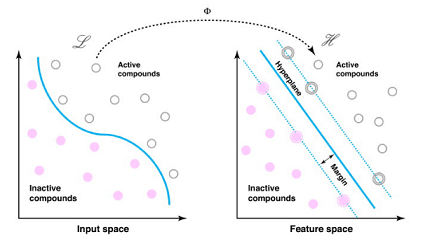
Hãy xem xét một hàm biến đổi phi tuyến \( \phi(\mathbf{x}) \), chuyển dữ liệu từ không gian gốc \( \mathbb{R}^n \) sang không gian đặc trưng cao hơn \( \mathbb{R}^m\). Thay vì tính trực tiếp sản phẩm vô hướng trong không gian đặc trưng, chúng ta sử dụng một hàm kernel \( K(\mathbf{x}_i, \mathbf{x}_j) \) thỏa mãn:
\[K(\mathbf{x}_i, \mathbf{x}_j) = \langle \phi(\mathbf{x}_i), \phi(\mathbf{x}_j) \rangle\]
Phương trình tối ưu hóa trong SVM với kernel sẽ trở thành:
\[\min_{\alpha} \frac{1}{2} \sum_{i,j} \alpha_i \alpha_j y_i y_j K(\mathbf{x}_i, \mathbf{x}_j) – \sum_i \alpha_i\]
với ràng buộc:
\[\sum_i \alpha_i y_i = 0 \quad \text{và} \quad \alpha_i \geq 0\]
Một số hàm kernel phổ biến bao gồm:
Kernel đa thức (Polynomial Kernel):
\[K(\mathbf{x}_i, \mathbf{x}_j) = (\mathbf{x}_i^T \mathbf{x}_j + c)^d\]
Kernel Gaussian hay RBF (Radial Basis Function):
\[K(\mathbf{x}_i, \mathbf{x}_j) = \exp\left(-\frac{\|\mathbf{x}_i – \mathbf{x}_j\|^2}{2\sigma^2}\right)\]
Kernel sigmoid:
\[K(\mathbf{x}_i, \mathbf{x}_j) = \tanh(\kappa \mathbf{x}_i^T \mathbf{x}_j + c)\]
3. Ưu điểm và nhược điểm
3.1. Ưu điểm của SVM
Hiệu quả cao với dữ liệu có số lượng đặc trưng lớn
SVM hoạt động tốt khi số lượng đặc trưng (features) của dữ liệu lớn hơn nhiều so với số lượng mẫu dữ liệu. Điều này làm cho SVM trở thành lựa chọn lý tưởng cho các bài toán như phân loại văn bản và nhận dạng hình ảnh, nơi số lượng đặc trưng thường rất lớn.
Hiệu suất cao với dữ liệu phi tuyến tính
Khi dữ liệu không thể phân tách tuyến tính, SVM có thể sử dụng các kỹ thuật kernel để chuyển đổi dữ liệu sang không gian có thể phân tách. Các kernel phổ biến bao gồm kernel Gaussian (RBF), kernel Polynomial, và Sigmoid.
Tối ưu hóa margin
SVM tối đa hóa margin giữa các lớp dữ liệu, giúp cải thiện khả năng tổng quát hóa (generalization) của mô hình. Margin càng lớn thì mô hình càng ít có nguy cơ bị overfitting và có thể phân loại chính xác hơn trên dữ liệu chưa từng gặp.
Lời giải duy nhất và tối ưu
Bài toán tối ưu hóa của SVM có lời giải duy nhất và tối ưu nhờ vào việc sử dụng kỹ thuật tối ưu hóa bậc hai (Quadratic Programming). Điều này giúp mô hình trở nên ổn định và dễ giải thích.
Xử lý hiệu quả với outliers
SVM có khả năng xử lý tốt các dữ liệu ngoại lai (outliers) bằng cách sử dụng Soft Margin. Điều này cho phép mô hình phân loại chính xác ngay cả khi có dữ liệu bị nhiễu.
3.2. Nhược điểm của SVM
Khó khăn trong việc chọn kernel phù hợp
Một trong những thách thức lớn nhất khi sử dụng SVM là lựa chọn kernel phù hợp cho dữ liệu. Nếu chọn kernel không đúng, mô hình có thể không hoạt động tốt và gây ra hiện tượng overfitting hoặc underfitting.
Độ phức tạp tính toán cao
SVM thường yêu cầu tính toán phức tạp, đặc biệt là với các bộ dữ liệu lớn. Khi số lượng mẫu tăng lên, chi phí tính toán của SVM tăng theo cấp số nhân, điều này làm giảm tính khả thi của nó đối với các bài toán dữ liệu lớn.
Nhạy cảm với dữ liệu nhiễu
Mặc dù SVM có khả năng xử lý outliers tốt, nhưng nó vẫn có thể bị ảnh hưởng bởi các dữ liệu nhiễu. Nếu dữ liệu bị nhiễu quá mức, hiệu suất của SVM có thể giảm mạnh.
Thời gian huấn luyện lâu
Với các bộ dữ liệu lớn hoặc có nhiều đặc trưng, thời gian huấn luyện của SVM có thể rất lâu, đặc biệt khi cần sử dụng kernel phức tạp. Điều này có thể là một hạn chế lớn khi xử lý dữ liệu thời gian thực hoặc yêu cầu huấn luyện nhanh.
Khó mở rộng với nhiều lớp
Mặc dù SVM hoạt động tốt với bài toán phân loại hai lớp, việc mở rộng SVM cho bài toán phân loại đa lớp (multi-class classification) có thể trở nên phức tạp và kém hiệu quả hơn so với các thuật toán khác như Random Forest hay Gradient Boosting.
4. Ứng dụng của SVM trong thực tế
Support Vector Machine (SVM) là một trong những thuật toán học máy mạnh mẽ, được sử dụng rộng rãi trong nhiều lĩnh vực khác nhau. SVM không chỉ giới hạn trong việc phân loại dữ liệu tuyến tính mà còn mở rộng để xử lý các dữ liệu phi tuyến tính phức tạp thông qua các kỹ thuật kernel. Dưới đây là một số ứng dụng nổi bật của SVM trong thực tế.
4.1. Nhận dạng hình ảnh
SVM là một công cụ mạnh mẽ trong các bài toán nhận dạng hình ảnh. Các ứng dụng phổ biến bao gồm nhận diện khuôn mặt, nhận dạng chữ viết tay, và phân loại đối tượng trong ảnh. Ví dụ, trong hệ thống nhận diện khuôn mặt, SVM có thể được sử dụng để phân loại các đặc trưng khuôn mặt thành các lớp khác nhau, giúp xác định danh tính của người dùng.
Một ví dụ khác là nhận dạng chữ viết tay (Handwritten Character Recognition). Trong ứng dụng này, mỗi ký tự viết tay được chuyển thành một vector đặc trưng, và SVM sẽ phân loại các vector này vào các lớp tương ứng với từng ký tự.
4.2. Phân loại căn bản và lọc thư rác
SVM cũng được ứng dụng trong xử lý ngôn ngữ tự nhiên (NLP), đặc biệt là phân loại văn bản. Một trong những ứng dụng phổ biến nhất là lọc thư rác (spam filtering). Trong bài toán này, mỗi email được biểu diễn dưới dạng một vector đặc trưng (chẳng hạn như tần suất xuất hiện của từ ngữ), và SVM sẽ phân loại email vào nhóm thư rác hoặc không phải thư rác.
Ứng dụng này giúp các hệ thống email lọc bỏ những email không mong muốn, tăng cường hiệu suất làm việc và bảo vệ người dùng khỏi các mối đe dọa an ninh mạng.
4.3. Phát hiện gian lận
Trong lĩnh vực tài chính, SVM được sử dụng để phát hiện các hành vi gian lận trong giao dịch. Với khả năng phân loại chính xác, SVM có thể phát hiện các giao dịch bất thường dựa trên các mẫu dữ liệu lịch sử. Những ứng dụng như vậy đặc biệt quan trọng trong việc bảo vệ các tổ chức tài chính khỏi các hoạt động lừa đảo và giảm thiểu rủi ro.
Các công ty thẻ tín dụng, ngân hàng và dịch vụ tài chính thường sử dụng SVM để phát hiện các giao dịch gian lận trong thời gian thực, giúp họ đưa ra các biện pháp ngăn chặn kịp thời.
4.4. Ứng dụng trong Y tế và sinh học
Trong lĩnh vực y tế, SVM được sử dụng để phân tích dữ liệu y khoa, chẩn đoán bệnh, và dự đoán kết quả điều trị. Một ví dụ điển hình là việc sử dụng SVM để phân loại các tế bào ung thư dựa trên các mẫu sinh học. Bằng cách phân tích dữ liệu tế bào học hoặc dữ liệu hình ảnh y tế, SVM có thể hỗ trợ các bác sĩ trong việc chẩn đoán bệnh nhanh chóng và chính xác hơn.
Trong nghiên cứu sinh học, SVM được sử dụng để phân loại dữ liệu gene và protein, giúp các nhà khoa học xác định các mẫu sinh học và mối liên hệ giữa các bệnh lý và gene.
5. Xây dựng chương trình SVM
Tạo dữ liệu mẫu: Sử dụng make_classification từ sklearn để tạo một tập dữ liệu mẫu với 2 lớp.
Chuẩn hóa dữ liệu: Sử dụng StandardScaler để chuẩn hóa dữ liệu về dạng phân phối chuẩn.
Định nghĩa mô hình SVM: SVM được xây dựng bằng cách sử dụng một lớp tuyến tính (nn.Linear). Chúng ta sử dụng hàm mất mát Hinge (nn.HingeEmbeddingLoss) để thực hiện huấn luyện mô hình.
Huấn luyện mô hình: Chúng ta sử dụng optimizer Adam để cập nhật trọng số, và huấn luyện mô hình trong một số epoch nhất định.
Đánh giá mô hình: Sau khi huấn luyện, chúng ta đánh giá mô hình trên tập test và tính toán độ chính xác.
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 1. Tạo dữ liệu mẫu với 2 lớp (binary classification)
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_classes=2, random_state=42)
y = y * 2 - 1 # Chuyển đổi nhãn từ {0, 1} thành {-1, 1} cho SVM
# 2. Chia dữ liệu thành tập train và test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Chuẩn hóa dữ liệu
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Chuyển dữ liệu thành tensor PyTorch
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1) # Thêm chiều cho nhãn
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1)
# 3. Định nghĩa mô hình SVM
class SVM(nn.Module):
def __init__(self, input_size):
super(SVM, self).__init__()
self.linear = nn.Linear(input_size, 1) # Mô hình tuyến tính
def forward(self, x):
return self.linear(x)
# 4. Khởi tạo mô hình, optimizer và hàm mất mát
model = SVM(X_train.shape[1])
optimizer = optim.Adam(model.parameters(), lr=0.01)
hinge_loss = nn.HingeEmbeddingLoss()
# 5. Huấn luyện mô hình
num_epochs = 100
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
# Tính toán dự đoán
outputs = model(X_train)
# Tính toán hàm mất mát SVM với Hinge Loss
loss = hinge_loss(outputs, y_train)
# Cập nhật trọng số
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 6. Đánh giá mô hình trên tập test
model.eval()
with torch.no_grad():
test_outputs = model(X_test)
test_preds = torch.sign(test_outputs) # Dự đoán lớp bằng dấu của đầu ra
accuracy = (test_preds == y_test).float().mean().item()
print(f'Accuracy on test set: {accuracy * 100:.2f}%')
6. Kết luận
SVM là một thuật toán học máy có tính ứng dụng cao với nhiều ưu điểm vượt trội như hiệu suất cao với dữ liệu có số lượng đặc trưng lớn, khả năng xử lý dữ liệu phi tuyến tính với kernel, và tối ưu hóa margin. Tuy nhiên, SVM cũng có những nhược điểm như độ phức tạp tính toán cao, khó khăn trong việc chọn kernel phù hợp, và nhạy cảm với dữ liệu nhiễu.
Việc lựa chọn SVM làm thuật toán học máy phụ thuộc vào đặc điểm của bài toán cụ thể. Nếu bài toán có số lượng đặc trưng lớn, dữ liệu phức tạp và cần mô hình có khả năng tổng quát hóa tốt, SVM có thể là một lựa chọn lý tưởng. Tuy nhiên, đối với các bài toán với dữ liệu lớn và yêu cầu thời gian xử lý nhanh, các thuật toán khác có thể phù hợp hơn.