Tăng tốc huấn luyện mô hình AI với phương pháp Gradient Descent
1. Giới thiệu
Gradient Descent (GD) là một trong những thuật toán tối ưu quan trọng và phổ biến nhất trong học máy (machine learning) và trí tuệ nhân tạo (AI). Mục tiêu chính của thuật toán này là tìm giá trị tối ưu (cực tiểu hoặc cực đại) của một hàm mất mát (loss function) để tối ưu hóa mô hình. Trong bối cảnh học máy, Gradient Descent giúp điều chỉnh các tham số của mô hình, chẳng hạn như trọng số trong mạng neural, sao cho hàm mất mát được giảm thiểu tối đa.
Gradient Descent hoạt động bằng cách tính đạo hàm của hàm mất mát theo các tham số mô hình và điều chỉnh các tham số đó theo hướng ngược lại với đạo hàm (gradient). Bằng cách lặp lại quy trình này, thuật toán dần dần tiến gần đến điểm tối ưu. Có nhiều biến thể của Gradient Descent như Stochastic Gradient Descent (SGD), Mini-batch Gradient Descent, hay Batch Gradient Descent, mỗi loại phù hợp với các bài toán và dữ liệu khác nhau.
2. Cách Gradient Descent hoạt động
Gradient Descent là một thuật toán tối ưu, giúp tìm giá trị cực tiểu của một hàm mục tiêu (thường là hàm mất mát). Nó dựa trên việc tính toán gradient (đạo hàm bậc nhất) của hàm này với các tham số cần tối ưu và điều chỉnh các tham số theo hướng ngược lại của gradient để giảm thiểu hàm mất mát.
2.1. Các bước thực hiện
Khởi tạo tham số ban đầu
Bắt đầu với giá trị khởi tạo cho các tham số cần tối ưu hóa, gọi là \( \theta \). Các giá trị này có thể được chọn ngẫu nhiên hoặc cố định, tùy vào phương pháp khởi tạo.
Ví dụ: trong một bài toán hồi quy tuyến tính, \( \theta \) có thể là các trọng số (weights) của mô hình.
Tính toán giá trị của hàm mất mát
Hàm mất mát \( J(\theta) \) đánh giá độ sai lệch giữa dự đoán của mô hình và giá trị thực tế.
Ví dụ: Với bài toán hồi quy tuyến tính, hàm mất mát phổ biến là hàm sai số bình phương trung bình (Mean Squared Error – MSE):
\[ J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x_i) – y_i)^2 \]
Trong đó, \( m \) là số lượng mẫu dữ liệu, \( h_\theta(x_i) \) là giá trị dự đoán của mô hình với tham số \( \theta \), và \( y_i \) là giá trị thực tế.
Tính gradient của hàm mất mát theo tham số
Gradient của hàm mất mát đối với các tham số là đạo hàm bậc nhất của \( J(\theta) \) theo từng tham số \( \theta \). Nó biểu thị độ dốc và hướng thay đổi của hàm mất mát.
Gradient được ký hiệu là \( \nabla_\theta J(\theta) \), với mỗi phần tử của nó tương ứng với đạo hàm riêng phần theo từng tham số của mô hình.
Ví dụ: Với hàm \( J(\theta) \) đơn giản như \( J(\theta) = \theta^2 \), gradient sẽ là:
\[ \nabla_\theta J(\theta) = 2\theta \]
Điều này cho biết mức độ và hướng mà \( \theta \) nên thay đổi để giảm giá trị của \( J(\theta) \).
Cập nhật các tham số
Sau khi tính toán gradient, ta cập nhật các tham số \( \theta \) theo công thức sau:
\[ \theta = \theta – \alpha \nabla_\theta J(\theta) \]
Ở đây, \( \alpha \) là tốc độ học (learning rate), cho biết kích thước bước đi trong quá trình tối ưu hóa. Nếu \( \alpha \) quá lớn, quá trình có thể bỏ qua điểm cực tiểu; nếu \( \alpha \) quá nhỏ, quá trình hội tụ sẽ rất chậm.
Quá trình cập nhật này được gọi là “bước gradient”, và mỗi lần thực hiện được gọi là một “epoch”.
Lặp lại quá trình
Quy trình này được lặp lại nhiều lần cho đến khi hội tụ, tức là khi gradient đủ nhỏ hoặc khi giá trị của hàm mất mát không thay đổi nhiều giữa các bước lặp.
Hội tụ thường đạt được khi gradient tiến gần đến 0, nghĩa là đã đạt đến điểm cực tiểu của hàm mất mát.
Điều kiện dừng
Thuật toán Gradient Descent sẽ dừng khi:
- Số lần lặp (epoch) đạt giới hạn đã định trước.
- Gradient trở nên rất nhỏ, gần như bằng 0, hoặc sự thay đổi trong giá trị của hàm mất mát không đáng kể.
Ví dụ trực quan
Giả sử ta có một hàm đơn giản \( f(x) = x^2 \) và muốn tìm giá trị \( x \) sao cho \( f(x) \) đạt cực tiểu (điểm cực tiểu của \( f(x) \) nằm tại \( x = 0 \)).
Quy trình với Gradient Descent:
Bước 1: Chọn giá trị khởi tạo ban đầu \( x = 4 \), chọn tốc độ học \( \alpha = 0.1 \).
Bước 2: Tính gradient \( \nabla_x f(x) = 2x \): Với \( x = 4 \), gradient là \( 2 \times 4 = 8 \).
Bước 3: Cập nhật giá trị của \( x \): \[ x_{\text{new}} = x_{\text{old}} – \alpha \times \nabla_x f(x_{\text{old}}) = 4 – 0.1 \times 8 = 3.2 \]
Bước 4: Lặp lại quy trình cho đến khi \( x \) gần bằng 0.
Qua mỗi bước, giá trị của \( x \) sẽ càng ngày càng nhỏ, hướng đến giá trị \( 0 \), là điểm cực tiểu của hàm \( f(x) \).
2.2. Giảm thiểu lỗi trong khi học
Trong học máy, hàm mất mát đo lường sự khác biệt giữa giá trị dự đoán của mô hình và giá trị thực tế. Ví dụ, trong hồi quy tuyến tính, mục tiêu là điều chỉnh các tham số của mô hình (như trọng số) sao cho dự đoán của mô hình gần đúng với giá trị thực tế. Gradient Descent giúp tìm các giá trị tham số tối ưu bằng cách giảm thiểu giá trị của hàm mất mát.
2.3. Code minh họa
Dưới đây là ví dụ sử dụng PyTorch để minh họa quá trình cập nhật tham số bằng Gradient Descent cho hàm mất mát đơn giản:
import torch
# Hàm mất mát đơn giản: f(x) = x^2
def loss_function(x):
return x**2
# Khởi tạo giá trị x ban đầu và tốc độ học
x = torch.tensor([4.0], requires_grad=True)
learning_rate = 0.1
# Số bước lặp
for i in range(10):
# Tính giá trị hàm mất mát
loss = loss_function(x)
# Tính gradient của hàm mất mát
loss.backward()
# Cập nhật x theo gradient descent
with torch.no_grad():
x -= learning_rate * x.grad
# Reset gradient cho lần lặp tiếp theo
x.grad.zero_()
print(f'Iteration {i+1}: x = {x.item()}, loss = {loss.item()}')Giải thích:
Ở ví dụ trên, ta khởi tạo \( x = 4 \). Ở mỗi bước, giá trị của \( x \) được cập nhật theo Gradient Descent và dần dần hội tụ về giá trị \( x = 0 \), là điểm cực tiểu của hàm \( f(x) = x^2 \). Giá trị của hàm mất mát (loss) cũng giảm dần theo các bước lặp.
Kết quả thực hiện code:
Iteration 1: x = 3.200000047683716, loss = 16.0
Iteration 2: x = 2.559999942779541, loss = 10.24000072479248
Iteration 3: x = 2.047999858856201, loss = 6.553599834442139
Iteration 4: x = 1.6383998394012451, loss = 4.194303512573242
Iteration 5: x = 1.3107198476791382, loss = 2.684354066848755
Iteration 6: x = 1.0485758781433105, loss = 1.7179864645004272
Iteration 7: x = 0.8388606905937195, loss = 1.0995113849639893
Iteration 8: x = 0.6710885763168335, loss = 0.7036872506141663
Iteration 9: x = 0.5368708372116089, loss = 0.45035988092422485
Iteration 10: x = 0.4294966757297516, loss = 0.2882302999496463. Vấn đề trong Gradient Descent truyền thống
Gradient Descent là một trong những thuật toán tối ưu hóa phổ biến nhất trong học máy. Tuy nhiên, nó cũng gặp phải nhiều vấn đề khi được áp dụng trong thực tế. Dưới đây là các vấn đề chính mà Gradient Descent truyền thống gặp phải:
3.1. Overfitting
Overfitting là một hiện tượng phổ biến trong quá trình huấn luyện mô hình học máy, khi mô hình học quá kỹ các chi tiết và nhiễu từ tập dữ liệu huấn luyện. Khi đó, mô hình có khả năng dự đoán rất tốt trên dữ liệu huấn luyện nhưng lại hoạt động kém trên dữ liệu kiểm tra hoặc dữ liệu thực tế.
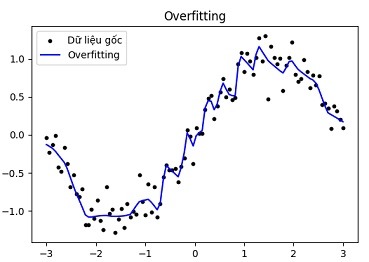
Một số đặc điểm của overfitting:
Mô hình quá phức tạp
Overfitting thường xảy ra khi mô hình có quá nhiều tham số, chẳng hạn như các mạng nơ-ron với quá nhiều lớp hoặc quá nhiều nút trong từng lớp. Những mô hình này có thể dễ dàng khớp với các biến đổi nhỏ và nhiễu trong tập dữ liệu, nhưng lại mất khả năng tổng quát hóa khi gặp các dữ liệu mới.
Hiệu suất giảm trên dữ liệu mới
Dù mô hình có thể đạt hiệu suất rất cao trên tập huấn luyện, khi áp dụng trên dữ liệu mới hoặc dữ liệu kiểm tra, kết quả có thể kém hơn đáng kể. Điều này là do mô hình đã học các mẫu không đại diện cho xu hướng chung của dữ liệu.
Dấu hiệu overfitting
Một dấu hiệu rõ ràng của overfitting là sự chênh lệch lớn giữa độ chính xác trên tập huấn luyện và độ chính xác trên tập kiểm tra. Khi mô hình liên tục cải thiện trên dữ liệu huấn luyện nhưng không cải thiện trên dữ liệu kiểm tra, đó là dấu hiệu mô hình đã bắt đầu overfit.
Cách giảm thiểu overfitting:
Sử dụng regularization
Các kỹ thuật như L1/L2 regularization hoặc Dropout giúp giảm thiểu overfitting bằng cách giới hạn độ phức tạp của mô hình.
Thêm dữ liệu huấn luyện
Nếu có thêm dữ liệu, mô hình sẽ học được nhiều mẫu phong phú hơn và giảm thiểu khả năng overfit.
Early stopping
Theo dõi hiệu suất trên tập kiểm tra và dừng quá trình huấn luyện khi mô hình bắt đầu có dấu hiệu overfit thay vì tiếp tục huấn luyện quá lâu.
3.2. Underfitting
Underfitting xảy ra khi một mô hình học máy không đủ khả năng để khớp với dữ liệu huấn luyện, dẫn đến hiệu suất kém trên cả tập huấn luyện và dữ liệu kiểm tra. Đây là vấn đề khi mô hình quá đơn giản hoặc không đủ phức tạp để học các đặc điểm quan trọng của dữ liệu.
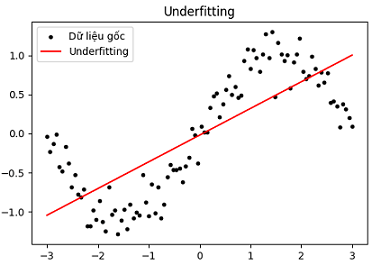
Đặc điểm của Underfitting:
Mô hình quá đơn giản
Underfitting thường xảy ra khi mô hình không đủ phức tạp để nắm bắt các mối quan hệ trong dữ liệu. Ví dụ, sử dụng một mô hình tuyến tính cho dữ liệu có quan hệ phi tuyến có thể dẫn đến underfitting, vì mô hình tuyến tính không thể đại diện cho các biến thể phức tạp trong dữ liệu.
Hiệu suất kém trên cả tập huấn luyện và dữ liệu kiểm tra
Khi một mô hình bị underfit, cả độ chính xác trên tập huấn luyện và độ chính xác trên dữ liệu kiểm tra đều thấp. Điều này cho thấy mô hình không thể học được các đặc điểm cần thiết từ dữ liệu.
Dấu hiệu của underfitting
Một dấu hiệu rõ ràng của underfitting là khi độ chính xác trên tập huấn luyện không đạt mức mong muốn và không cải thiện nhiều khi so với độ chính xác trên dữ liệu kiểm tra. Mô hình không thể học đủ từ dữ liệu để cải thiện hiệu suất.
Cách khắc phục underfitting:
Tăng độ phức tạp của mô hình
Sử dụng mô hình phức tạp hơn hoặc thêm nhiều lớp và nút trong mạng nơ-ron có thể giúp mô hình học được các đặc điểm phức tạp hơn từ dữ liệu.
Thay đổi đặc trưng dữ liệu
Tạo thêm đặc trưng hoặc áp dụng các kỹ thuật khai thác đặc trưng có thể giúp mô hình học được nhiều thông tin hơn từ dữ liệu.
Giảm regularization
Nếu mô hình đang sử dụng các kỹ thuật regularization như L1/L2, giảm mức regularization có thể giúp mô hình học được nhiều hơn từ dữ liệu huấn luyện.
3.3. Lựa chọn learning rate không tối ưu
Learning rate (\( \alpha \)) là tham số quan trọng trong Gradient Descent. Nếu không chọn đúng giá trị learning rate, thuật toán có thể gặp nhiều vấn đề:
3.3.1. Learning rate quá lớn
Không hội tụ
Learning rate lớn khiến các bước nhảy trong quá trình tối ưu hóa trở nên quá lớn, khiến mô hình bỏ qua điểm tối ưu cục bộ hoặc toàn cục. Điều này làm cho quá trình huấn luyện không hội tụ và mất ổn định, dẫn đến kết quả không chính xác.
Dao động quanh điểm tối ưu
Thay vì dần dần giảm thiểu hàm mất mát và tiến đến điểm tối ưu, một learning rate quá lớn có thể làm cho mô hình dao động xung quanh điểm tối ưu mà không bao giờ đạt được sự hội tụ. Điều này xảy ra do mô hình liên tục vượt qua điểm tối ưu mà không có khả năng dừng lại.
Giảm độ chính xác
Nếu learning rate quá cao, mô hình có thể học quá nhanh và không kịp tối ưu hóa các trọng số chính xác cho từng bước. Điều này dẫn đến sai số lớn hơn và làm giảm độ chính xác của mô hình, ngay cả khi mô hình có thể tiềm năng đạt hiệu quả tốt hơn.
Hàm mất mát tăng cao
Trong một số trường hợp, learning rate lớn có thể làm cho giá trị hàm mất mát tăng thay vì giảm, do các cập nhật trọng số lớn gây ra sự thay đổi mạnh trong hướng gradient, khiến mô hình trở nên kém hiệu quả hơn.
3.3.2. Learning rate quá nhỏ
Quá trình huấn luyện chậm chạp
Learning rate nhỏ làm cho các bước cập nhật trọng số rất nhỏ, dẫn đến tốc độ hội tụ chậm. Mô hình cần nhiều thời gian và số lần lặp để đạt đến điểm tối ưu, làm kéo dài quá trình huấn luyện, đặc biệt với các tập dữ liệu lớn và mô hình phức tạp.
Hội tụ tại điểm cục bộ
Một learning rate nhỏ có thể khiến mô hình bị “mắc kẹt” ở các điểm tối ưu cục bộ thay vì đạt đến điểm tối ưu toàn cục. Điều này xảy ra khi bước cập nhật quá nhỏ để thoát khỏi các thung lũng trong không gian hàm mất mát, dẫn đến kết quả không tối ưu.
Chi phí tính toán tăng cao
Với learning rate quá nhỏ, số lần lặp cần thiết để giảm thiểu hàm mất mát tăng lên, kéo theo chi phí tính toán cũng tăng. Điều này có thể gây lãng phí tài nguyên tính toán mà không đạt được hiệu suất tốt hơn.
Nguy cơ overfitting
Do quá trình huấn luyện kéo dài, mô hình có thể học quá kỹ các chi tiết của tập dữ liệu huấn luyện, dẫn đến overfitting. Mặc dù hàm mất mát trên tập huấn luyện giảm dần, mô hình có thể không tổng quát tốt trên dữ liệu kiểm tra, làm giảm khả năng dự đoán chính xác.
Ví dụ minh họa lựa chọn learning rate:
import torch
import torch.optim as optim
import torch.nn as nn
import matplotlib.pyplot as plt
# Khởi tạo mô hình đơn giản với một tham số
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.weight = nn.Parameter(torch.tensor([1.0])) # Khởi tạo weight = 1.0
def forward(self, x):
return x * self.weight
# Khởi tạo mô hình và dữ liệu
model = SimpleModel()
criterion = nn.MSELoss() # Mean Squared Error Loss
optimizer = optim.SGD(model.parameters(), lr=0.5) # Learning rate nhỏ gây hội tụ chậm
# Dữ liệu đầu vào đơn giản
x = torch.tensor([2.0]) # Đầu vào
y = torch.tensor([4.0]) # Mục tiêu (output đúng là 2 * 2 = 4)
# Lưu giá trị loss cho việc vẽ đồ thị
loss_values = []
# Huấn luyện mô hình
epochs = 200
for epoch in range(epochs):
optimizer.zero_grad() # Xóa gradient trước khi tính toán lại
output = model(x) # Tính output của mô hình
loss = criterion(output, y) # Tính loss
loss.backward() # Tính toán gradient
optimizer.step() # Cập nhật tham số mô hình
# Lưu lại giá trị loss
loss_values.append(loss.item())
# In ra loss mỗi 100 epochs
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
# Vẽ biểu đồ quá trình hội tụ loss
plt.plot(range(epochs), loss_values)
plt.title('Quá trình hội tụ với Learning Rate là 0.5')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.show()
Kết quả:
khi lựa chọn learning rate là 0.5, chương trình không hội tụ
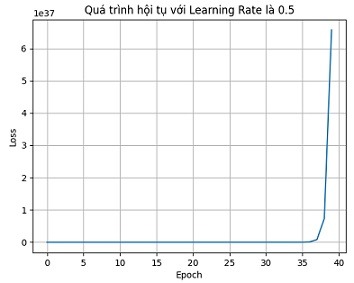
Khi lựa chọn learning rate là 0.01, chương trình hội tụ nhanh và ổn định.
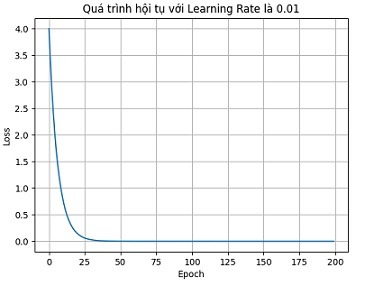
Khi lựa chọn learning rate là 0.001, chương trình hội tụ rất chậm.
Việc lựa chọn learning rate ảnh hưởng nhiều tới khả năng cũng như tốc độ hội tụ của chương trình. Để tìm được giá trị learning rate tốt, cần thử nghiệm nhiều lần và với bộ dữ liệu tương đối lớn.
4. Phương pháp tối ưu Gradient Descent
Phương pháp Gradient Descent là một trong những thuật toán tối ưu phổ biến nhất để điều chỉnh các tham số của mô hình nhằm giảm thiểu hàm mất mát. Quá trình này được thực hiện bằng cách cập nhật các tham số của mô hình theo hướng
ngược lại của gradient của hàm mất mát.
4.1. Gradient Descent cơ bản
Gradient Descent cơ bản cập nhật tham số bằng cách di chuyển theo hướng ngược lại của gradient của hàm mất mát, được tính toán dựa trên toàn bộ tập dữ liệu.
Cập nhật tham số \( \theta \) có thể được viết dưới dạng:
\[ \theta \leftarrow \theta – \eta \frac{\partial J}{\partial \theta} \]
Trong đó:
- \( \theta \): các tham số của mô hình
- \( J(\theta) \): hàm mất mát
- \( \eta \): tốc độ học (learning rate)
- \( \frac{\partial J}{\partial \theta} \): gradient của hàm mất mát đối với các tham số
Phương pháp này có thể chậm nếu tập dữ liệu quá lớn, vì mỗi lần tính toán gradient yêu cầu duyệt qua toàn bộ dữ liệu.
Để tăng tốc, có một số biến thể của Gradient Descent đã được phát triển, mỗi phương pháp nhằm mục đích cải thiện hiệu quả huấn luyện.
4.2. Stochastic Gradient Descent (SGD)
Thay vì tính toán gradient dựa trên toàn bộ tập dữ liệu, Stochastic Gradient Descent (SGD) cập nhật tham số dựa trên
một mẫu nhỏ dữ liệu (mini-batch). Điều này giúp giảm chi phí tính toán và tăng tốc độ huấn luyện, tuy nhiên cũng có thể gây ra dao động lớn hơn trong quá trình hội tụ.
Công thức cập nhật SGD là:
\[ \theta \leftarrow \theta – \eta \frac{\partial J_i}{\partial \theta} \]
Trong đó \( J_i \) là hàm mất mát của một điểm dữ liệu ngẫu nhiên \( i \).
Chương trình mẫu với pytorch:
Ví dụ cho chuỗi đầu vào là \( x = [[1.0], [2.0], [3.0], [4.0]] \), tương ứng với đầu ra là \( y = [[3.0], [5.0], [7.0], [9.0]] \). Chương trình sẽ dự đoán khi \( x = [[5.0]] \) thì \( y \) là bao nhiêu?
import torch
import torch.nn as nn
import torch.optim as optim
# 1. Tạo dữ liệu mẫu (x, y) cho bài toán hồi quy tuyến tính y = 2x + 1
x_train = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
y_train = torch.tensor([[3.0], [5.0], [7.0], [9.0]], dtype=torch.float32)
# 2. Định nghĩa mô hình hồi quy tuyến tính
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 1 input feature, 1 output
def forward(self, x):
return self.linear(x)
# 3. Khởi tạo mô hình
model = LinearRegressionModel()
# 4. Định nghĩa hàm mất mát và bộ tối ưu SGD
criterion = nn.MSELoss() # Mean Squared Error Loss
optimizer = optim.SGD(model.parameters(), lr=0.001) # Giảm learning rate từ 0.01 xuống 0.001
# 5. Huấn luyện mô hình
num_epochs = 5000 # Tăng số lượng epoch để quá trình huấn luyện dài hơn
for epoch in range(num_epochs):
# Forward pass: tính toán dự đoán
y_pred = model(x_train)
# Tính toán mất mát
loss = criterion(y_pred, y_train)
# Backward pass: tính gradient
optimizer.zero_grad() # Xóa gradient trước đó
loss.backward() # Tính toán gradient
# Cập nhật tham số mô hình
optimizer.step()
# In thông tin về loss theo từng bước huấn luyện
if (epoch+1) % 500 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.6f}')
# 6. Dự đoán với dữ liệu mới
x_test = torch.tensor([[5.0]], dtype=torch.float32)
y_test_pred = model(x_test)
print(f'Prediction for input 5: {y_test_pred.item()}')
Kết quả
Epoch [500/5000], Loss: 0.004743
Epoch [1000/5000], Loss: 0.003514
Epoch [1500/5000], Loss: 0.002605
Epoch [2000/5000], Loss: 0.001931
Epoch [2500/5000], Loss: 0.001431
Epoch [3000/5000], Loss: 0.001061
Epoch [3500/5000], Loss: 0.000786
Epoch [4000/5000], Loss: 0.000583
Epoch [4500/5000], Loss: 0.000432
Epoch [5000/5000], Loss: 0.000320
Model weight: 1.9851078987121582
Model bias: 1.0437837839126587
Prediction for input 5: 10.969323158264164.3. Momentum
SGD có thể gặp khó khăn trong việc hội tụ nhanh do dao động mạnh khi gradient thay đổi đột ngột.
Để khắc phục điều này, phương pháp Momentum được sử dụng nhằm giảm dao động và giúp quá trình hội tụ nhanh hơn.
Momentum lưu giữ thông tin từ các gradient trước đó và tăng tốc theo hướng của gradient tích lũy.
Công thức cập nhật với Momentum là:
Cập nhật vận tốc (velocity):
\[ v_t = \gamma v_{t-1} + \eta \frac{\partial J}{\partial \theta} \]
- \( v_t \): Vận tốc tại thời điểm \( t \), đại diện cho tổng hợp của các gradient trước đó.
- \( \gamma \): Hệ số Momentum, thường nằm trong khoảng \( 0 \leq \gamma < 1 \) (thường là 0.9).
- \( \eta \): Tốc độ học (learning rate).
- \( \frac{\partial J}{\partial \theta} \): Gradient của hàm mất mát \( J(\theta) \) theo tham số \( \theta \).
Cập nhật tham số mô hình:
\[ \theta_t = \theta_{t-1} – v_t \]
- \( \theta_t \): Tham số mô hình tại thời điểm \( t \).
- \( v_t \): Vận tốc đã được tính ở bước trên.
4.4. Adam (Adaptive Moment Estimation)
Adam là một phương pháp tối ưu hiện đại kết hợp giữa Momentum và RMSProp (Root Mean Square Propagation).
Phương pháp này sử dụng cả hai thông tin: moment thứ nhất (trung bình động của gradient) và moment thứ hai (trung bình động của bình phương gradient), giúp cân bằng việc điều chỉnh tốc độ học và giữ lại tính ổn định.
Công thức toán học:
Tính toán moment bậc nhất:
\[ m_t = \beta_1 m_{t-1} + (1 – \beta_1) \frac{\partial J}{\partial \theta} \]
Trong đó:
- \( m_t \): Moment bậc nhất tại thời điểm \( t \), trung bình động của gradient.
- \( \beta_1 \): Hệ số giảm bớt moment bậc nhất, thường có giá trị khoảng 0.9.
- \( \frac{\partial J}{\partial \theta} \): Gradient của hàm mất mát \( J(\theta) \) theo tham số \( \theta \).
Tính toán moment bậc hai:
\[ v_t = \beta_2 v_{t-1} + (1 – \beta_2) \left( \frac{\partial J}{\partial \theta} \right)^2 \]
Trong đó:
- \( v_t \): Moment bậc hai tại thời điểm \( t \), trung bình động của bình phương gradient.
- \( \beta_2 \): Hệ số giảm bớt moment bậc hai, thường có giá trị khoảng 0.999.
Hiệu chỉnh moment bậc nhất và bậc hai (bias correction):
\[ \hat{m}_t = \frac{m_t}{1 – \beta_1^t} \]
\[ \hat{v}_t = \frac{v_t}{1 – \beta_2^t} \]
Cập nhật tham số:
\[ \theta_t = \theta_{t-1} – \eta \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon} \]
Trong đó:
- \( \eta \): Tốc độ học (learning rate).
- \( \epsilon \): Một giá trị rất nhỏ (thường là \( 10^{-8} \)) để tránh chia cho 0.
- \( \theta_t \): Tham số mô hình tại thời điểm \( t \).
Chương trình mẫu với pytorch:
Ví dụ cho chuỗi đầu vào là \( x = [[1.0], [2.0], [3.0], [4.0]] \), tương ứng với đầu ra là \( y = [[3.0], [5.0], [7.0], [9.0]] \). Chương trình sẽ dự đoán khi \( x = [[5.0]] \) thì \( y \) là bao nhiêu?
import torch
import torch.nn as nn
import torch.optim as optim
# 1. Tạo dữ liệu mẫu (x, y) cho bài toán hồi quy tuyến tính y = 2x + 1
x_train = torch.tensor([[1.0], [2.0], [3.0], [4.0]], dtype=torch.float32)
y_train = torch.tensor([[3.0], [5.0], [7.0], [9.0]], dtype=torch.float32)
# 2. Định nghĩa mô hình hồi quy tuyến tính
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1) # 1 input feature, 1 output
def forward(self, x):
return self.linear(x)
# 3. Khởi tạo mô hình
model = LinearRegressionModel()
# 4. Định nghĩa hàm mất mát và bộ tối ưu Adam
criterion = nn.MSELoss() # Mean Squared Error Loss
optimizer = optim.Adam(model.parameters(), lr=0.01) # Sử dụng Adam với learning rate = 0.01
# 5. Huấn luyện mô hình
num_epochs = 1000
for epoch in range(num_epochs):
# Forward pass: tính toán dự đoán
y_pred = model(x_train)
# Tính toán mất mát
loss = criterion(y_pred, y_train)
# Backward pass: tính gradient
optimizer.zero_grad() # Xóa gradient trước đó
loss.backward() # Tính toán gradient
# Cập nhật tham số mô hình
optimizer.step()
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# 6. Dự đoán với dữ liệu mới
x_test = torch.tensor([[5.0]], dtype=torch.float32)
y_test_pred = model(x_test)
print(f'Prediction for input 5: {y_test_pred.item()}')Kết quả:
Epoch [100/1000], Loss: 0.9058
Epoch [200/1000], Loss: 0.0475
Epoch [300/1000], Loss: 0.0345
Epoch [400/1000], Loss: 0.0275
Epoch [500/1000], Loss: 0.0211
Epoch [600/1000], Loss: 0.0156
Epoch [700/1000], Loss: 0.0111
Epoch [800/1000], Loss: 0.0076
Epoch [900/1000], Loss: 0.0051
Epoch [1000/1000], Loss: 0.0032
Prediction for input 5: 10.8961238861083985. Kết luận
Gradient Descent là một trong những thuật toán nền tảng và quan trọng nhất trong quá trình huấn luyện mô hình AI. Với khả năng tối ưu hóa các tham số của mô hình thông qua việc giảm thiểu hàm mất mát, Gradient Descent giúp các mô hình học máy đạt được độ chính xác và hiệu quả cao hơn.
Tuy nhiên, để đạt được tốc độ hội tụ nhanh và tránh các vấn đề như overfitting hay underfitting, việc áp dụng các phương pháp tối ưu như Momentum, Adam, và Learning Rate Scheduling là cần thiết. Bằng cách kết hợp các kỹ thuật này, chúng ta không chỉ cải thiện được tốc độ huấn luyện mà còn tăng chất lượng của mô hình.
Trong tương lai, tối ưu hóa Gradient Descent sẽ tiếp tục đóng vai trò quan trọng trong sự phát triển của AI và học máy.