Tìm hiểu mô hình FaceNet cho bài toán nhận diện khuôn mặt
1. Giới thiệu
FaceNet và đặc trưng ánh xạ không gian

Mạng nơ-ron tích chập và Triplet Loss trong FaceNet
2. Cấu trúc mạng FaceNet
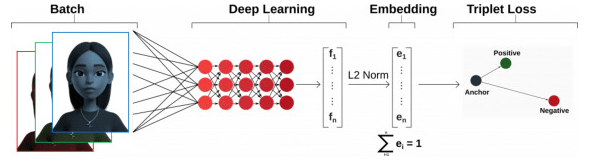
Mô hình FaceNet có một cấu trúc phức tạp với nhiều thành phần khác nhau, mỗi phần đóng một vai trò quan trọng trong việc trích xuất và ánh xạ đặc trưng khuôn mặt. Cấu trúc chính của FaceNet bao gồm các phần sau:
2.1. Mạng nơ-ron tích chập (CNN) để trích xuất đặc trưng
Phần đầu tiên của FaceNet là một mạng nơ-ron tích chập (CNN) được thiết kế để trích xuất các đặc trưng từ hình ảnh khuôn mặt. Mạng này bao gồm nhiều lớp tích chập (convolutional layers) và lớp gộp (pooling layers) để học các đặc trưng hình học và phong cách của khuôn mặt.
Cấu trúc điển hình của mạng CNN trong FaceNet có thể bao gồm:
- Lớp tích chập (Convolutional Layer): Các lớp này giúp phát hiện các đặc trưng cơ bản của hình ảnh, như cạnh và kết cấu. Ví dụ, lớp tích chập đầu tiên có thể có 64 kênh đầu ra với kích thước kernel là 7×7.
- Lớp Gộp (Pooling Layer): Các lớp này giảm kích thước không gian của hình ảnh đầu vào, giúp giảm số lượng tham số và tính toán, đồng thời giữ lại các đặc trưng quan trọng. Lớp gộp thường sử dụng phương pháp gộp tối đa (max pooling) với kích thước kernel là 3×3.
- Lớp Batch Normalization: Lớp này giúp chuẩn hóa đầu ra của các lớp tích chập, giảm thiểu sự thay đổi phân phối trong quá trình huấn luyện.
- Lớp kích hoạt (Activation Layer): Lớp ReLU (Rectified Linear Unit) thường được sử dụng để thêm tính phi tuyến vào mô hình, giúp mô hình học các đặc trưng phức tạp hơn.
Ví dụ về cấu trúc mạng CNN có thể như sau:
$$\text{Input Image} \rightarrow \text{Conv1 (64 filters, 7×7)} \rightarrow \text{ReLU} \rightarrow \text{MaxPool (3×3)} \rightarrow \text{Conv2 (128 filters, 3×3)} \rightarrow \text{ReLU} \rightarrow \text{MaxPool (3×3)}$$
2.2. Lớp Fully Connected (FC) để ánh xạ đặc trưng
Sau khi các đặc trưng được trích xuất bởi các lớp CNN, chúng được đưa qua các lớp fully connected (FC) để ánh xạ các đặc trưng này thành vector embedding có độ dài cố định. Các lớp FC thường được thiết kế để giảm dần số lượng kích thước đặc trưng từ các lớp tích chập xuống một kích thước nhỏ hơn, thường là 128 hoặc 512 chiều cho vector embedding.
Cấu trúc của các lớp FC có thể như sau:
$$\text{Flatten} \rightarrow \text{FC1 (1024 units)} \rightarrow \text{ReLU} \rightarrow \text{FC2 (Embedding Dim)}$$
Trong đó, Embedding Dim là kích thước của vector đặc trưng, thường là 128.
2.3. Hàm mất mát Triplet Loss
Triplet Loss là một trong những hàm mất mát quan trọng nhất trong mô hình FaceNet. Mục tiêu của Triplet Loss là đảm bảo rằng khoảng cách giữa vector đặc trưng của một khuôn mặt (gọi là Anchor) và một khuôn mặt khác của cùng một người (gọi là Positive) phải nhỏ hơn khoảng cách giữa vector đặc trưng của khuôn mặt đó và khuôn mặt của một người khác (gọi là Negative).
Định nghĩa:
$$\mathcal{L} = \sum_{i=1}^{N} \left[ \|f(x_i^A) – f(x_i^P)\|_2^2 – \|f(x_i^A) – f(x_i^N)\|_2^2 + \alpha \right]_+$$
Trong đó:
- \( x_i^A \): Hình ảnh Anchor (mỏ neo)
- \( x_i^P \): Hình ảnh Positive (tích cực, cùng một người với Anchor)
- \( x_i^N \): Hình ảnh Negative (tiêu cực, người khác với Anchor)
- \( f(x) \): Hàm ánh xạ hình ảnh \( x \) thành vector đặc trưng (embedding)
- \( \alpha \): Một siêu tham số gọi là margin, giúp kiểm soát khoảng cách tối thiểu giữa Positive và Negative
Hàm mất mát này yêu cầu rằng khoảng cách giữa Anchor và Positive nhỏ hơn khoảng cách giữa Anchor và Negative ít nhất là một lượng bằng \(\alpha\). Điều này giúp mô hình học cách phân biệt rõ ràng giữa các khuôn mặt khác nhau.
Hoạt động:
Hàm Triplet Loss dựa trên việc điều chỉnh ba hình ảnh: Anchor (A), Positive (P), và Negative (N). Mục tiêu của mô hình là học sao cho:
$$\|f(x_i^A) – f(x_i^P)\|_2^2 + \alpha < \|f(x_i^A) – f(x_i^N)\|_2^2$$
Trong đó, \(\|.\|_2^2\) là khoảng cách Euclidean giữa các vector đặc trưng. Điều này có nghĩa là khoảng cách giữa Anchor và Positive sẽ được thu nhỏ, trong khi khoảng cách giữa Anchor và Negative sẽ được mở rộng.
Ví dụ, nếu \( f(x_i^A) \) là vector đặc trưng cho một khuôn mặt, \( f(x_i^P) \) là vector đặc trưng cho cùng một khuôn mặt nhưng với biểu cảm khác, và \( f(x_i^N) \) là vector đặc trưng cho một khuôn mặt khác, thì hàm Triplet Loss sẽ cố gắng đảm bảo rằng:
$$\|f(x_i^A) – f(x_i^P)\|_2^2 + \alpha < \|f(x_i^A) – f(x_i^N)\|_2^2$$
Nếu điều kiện này không được thoả mãn, mô hình sẽ điều chỉnh các trọng số để giảm giá trị mất mát, làm cho các vector đặc trưng di chuyển gần hoặc xa nhau tùy theo yêu cầu.
2.4. Kỹ thuật tăng cường (Data Augmentation)
Để cải thiện khả năng tổng quát của mô hình và giảm hiện tượng overfitting, các kỹ thuật tăng cường dữ liệu thường được sử dụng. Các kỹ thuật này có thể bao gồm:
Chuyển đổi màu sắc
Thay đổi độ sáng, độ tương phản, và bão hòa của hình ảnh.
Biến dạng hình học
Xoay, cắt, và thay đổi kích thước của hình ảnh.
Làm mờ và nhiễu
Thêm nhiễu hoặc làm mờ hình ảnh để làm cho mô hình mạnh mẽ hơn với các điều kiện không giống như trong dữ liệu huấn luyện.
Việc áp dụng các kỹ thuật tăng cường giúp mô hình FaceNet có khả năng xử lý các biến thể trong điều kiện thực tế và cải thiện hiệu suất nhận diện khuôn mặt.
Dưới đây là một ví dụ về cách sử dụng torchvision.transforms để thực hiện các kỹ thuật tăng cường dữ liệu:
import torchvision.transforms as transforms
from PIL import Image
# Định nghĩa các kỹ thuật tăng cường dữ liệu
transform = transforms.Compose([
transforms.Resize((128, 128)), # Thay đổi kích thước hình ảnh
transforms.RandomRotation(degrees=30), # Xoay hình ảnh ngẫu nhiên trong phạm vi 30 độ
transforms.RandomHorizontalFlip(), # Lật ngang hình ảnh với xác suất 0.5
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2), # Thay đổi màu sắc
transforms.ToTensor() # Chuyển đổi hình ảnh thành tensor
])
# Tải và áp dụng các kỹ thuật tăng cường dữ liệu lên một hình ảnh
image = Image.open('path_to_your_image.jpg')
augmented_image = transform(image)
# Hiển thị hình ảnh gốc và hình ảnh đã tăng cường
import matplotlib.pyplot as plt
def show_image(image, title):
plt.imshow(image.permute(1, 2, 0)) # Chuyển đổi tensor thành định dạng hình ảnh
plt.title(title)
plt.axis('off')
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
show_image(transforms.ToTensor()(image), 'Original Image')
plt.subplot(1, 2, 2)
show_image(augmented_image, 'Augmented Image')
plt.show()
Trong đoạn mã trên:
- transforms.Resize: Thay đổi kích thước hình ảnh để có kích thước đồng nhất.
- transforms.RandomRotation: Xoay hình ảnh một cách ngẫu nhiên trong phạm vi góc cho phép.
- transforms.RandomHorizontalFlip: Lật ngang hình ảnh với xác suất 0.5.
- transforms.ColorJitter: Thay đổi các thuộc tính màu sắc của hình ảnh như độ sáng, độ tương phản, bão hòa và sắc thái.
- transforms.ToTensor: Chuyển đổi hình ảnh thành tensor, điều này là cần thiết cho việc đưa dữ liệu vào mô hình học máy trong PyTorch.
Kết quả mẫu khi thực hiện đoạn code trên:

Bằng cách áp dụng các kỹ thuật tăng cường dữ liệu này, bạn có thể cải thiện khả năng tổng quát của mô hình và giúp nó hoạt động tốt hơn trên dữ liệu thực tế với các biến thể khác nhau.
3. Triển khai và ứng dụng FaceNet
FaceNet có thể được triển khai trên nhiều nền tảng và framework khác nhau, bao gồm TensorFlow và PyTorch. Trong phần này, chúng ta sẽ xem xét cách triển khai một mô hình FaceNet đơn giản bằng PyTorch và các ứng dụng của mô hình này trong thực tế.
3.1. Triển khai FaceNet bằng PyTorch
Để triển khai FaceNet, trước tiên chúng ta cần định nghĩa một kiến trúc mạng nơ-ron tích chập. Dưới đây là một ví dụ đơn giản về cách định nghĩa mô hình FaceNet bằng PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# Định nghĩa mô hình FaceNet
class FaceNet(nn.Module):
def __init__(self, embedding_dim=128):
super(FaceNet, self).__init__()
self.convnet = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(3, stride=2),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.BatchNorm2d(192),
nn.ReLU(),
nn.MaxPool2d(3, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(192 * 6 * 6, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, embedding_dim)
)
def forward(self, x):
x = self.convnet(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# Khởi tạo mô hình
model = FaceNet(embedding_dim=128)
Trong đoạn mã trên, chúng ta đã định nghĩa một mô hình FaceNet đơn giản bao gồm một mạng tích chập (convolutional network) và các lớp fully connected để ánh xạ hình ảnh đầu vào thành vector embedding.
3.2. Huấn luyện mô hình với Triplet Loss
Để huấn luyện mô hình FaceNet, chúng ta cần chuẩn bị dữ liệu và thiết lập hàm mất mát Triplet Loss. Dưới đây là một ví dụ về cách thiết lập và huấn luyện mô hình:
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative):
distance_positive = torch.norm(anchor - positive, p=2, dim=1)
distance_negative = torch.norm(anchor - negative, p=2, dim=1)
losses = torch.relu(distance_positive - distance_negative + self.margin)
return torch.mean(losses)
# Khởi tạo hàm mất mát và trình tối ưu hóa
triplet_loss = TripletLoss(margin=1.0)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Huấn luyện mô hình
def train(model, dataloader, criterion, optimizer, num_epochs=10):
model.train()
for epoch in range(num_epochs):
running_loss = 0.0
for data in dataloader:
anchor, positive, negative = data
optimizer.zero_grad()
# Forward pass
anchor_embedding = model(anchor)
positive_embedding = model(positive)
negative_embedding = model(negative)
# Tính toán mất mát
loss = criterion(anchor_embedding, positive_embedding, negative_embedding)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(dataloader)}")
# Ví dụ về dữ liệu (cần chuẩn bị trước)
# dataloader = DataLoader(...)
# Huấn luyện mô hình
# train(model, dataloader, triplet_loss, optimizer)
Trong đoạn mã trên, chúng ta định nghĩa lớp TripletLoss và thiết lập trình tối ưu hóa Adam. Hàm train thực hiện huấn luyện mô hình với dữ liệu dạng triplet (Anchor, Positive, Negative).
3.3. Ứng dụng của FaceNet

FaceNet có nhiều ứng dụng thực tiễn trong các lĩnh vực khác nhau:
Nhận diện khuôn mặt
FaceNet có thể được sử dụng để nhận diện khuôn mặt trong các hệ thống bảo mật và nhận diện danh tính. Ví dụ, hệ thống nhận diện khuôn mặt trong các sân bay hoặc ngân hàng.
Xác thực khuôn mặt
Trong các hệ thống xác thực bảo mật, FaceNet có thể xác nhận xem một khuôn mặt có khớp với danh tính đã biết trước hay không, ví dụ như trong việc mở khóa điện thoại di động bằng nhận diện khuôn mặt.
Tìm kiếm khuôn mặt
FaceNet có thể giúp tìm kiếm khuôn mặt trong một cơ sở dữ liệu lớn. Ví dụ, trong các hệ thống giám sát công cộng, nó có thể tìm kiếm và nhận diện các cá nhân từ các video an ninh.
Nhóm khuôn mặt
FaceNet có thể phân loại và nhóm các khuôn mặt thành các nhóm khác nhau dựa trên sự tương đồng. Ví dụ, trong các ứng dụng quản lý hình ảnh, nó có thể giúp nhóm các bức ảnh của cùng một người lại với nhau.
4. Kết luận
Mặc dù FaceNet đã đạt được nhiều thành công, vẫn còn một số thách thức và hướng phát triển tương lai:
Đối phó với điều kiện ánh sáng và góc nhìn khác nhau
Mặc dù FaceNet hoạt động rất tốt trong điều kiện lý tưởng, nhưng việc nhận diện khuôn mặt trong các điều kiện ánh sáng yếu hoặc góc nhìn khác nhau vẫn là một thách thức.
Khả năng chống lại các cuộc tấn công spoofing
Các cuộc tấn công spoofing, chẳng hạn như sử dụng hình ảnh in trên giấy hoặc video giả, có thể gây khó khăn cho các hệ thống nhận diện khuôn mặt. Việc phát triển các phương pháp bảo vệ chống lại các cuộc tấn công này là rất quan trọng.
Cải thiện khả năng phân loại với số lượng dữ liệu lớn
Khi số lượng dữ liệu tăng lên, việc duy trì hiệu suất của mô hình là một thách thức. Các nghiên cứu về các kỹ thuật học sâu và các kiến trúc mạng mới có thể giúp cải thiện khả năng phân loại và giảm thiểu lỗi.
Với sự phát triển không ngừng của trí tuệ nhân tạo, chúng ta có thể kỳ vọng rằng các công nghệ nhận diện khuôn mặt sẽ tiếp tục tiến bộ, mở rộng khả năng ứng dụng và nâng cao độ chính xác. FaceNet là một bước tiến quan trọng trong lĩnh vực này và đã mở đường cho nhiều nghiên cứu và ứng dụng tiếp theo.