Tìm hiểu mô hình YOLOv5: Hiệu quả trong nhận diện đối tượng
1. Giới thiệu
YOLOv5 (You Only Look Once version 5) là một trong những mô hình phát hiện đối tượng tiên tiến và hiệu quả hiện nay, được phát triển để nhận diện và định vị các đối tượng trong ảnh với tốc độ cực nhanh và độ chính xác cao. YOLOv5 là sự tiếp nối của các phiên bản trước của mô hình YOLO, nhưng được cải thiện về cả kiến trúc và khả năng tối ưu hóa, giúp việc triển khai trở nên dễ dàng hơn và hiệu quả hơn trong các ứng dụng thực tế.
YOLOv5 chia ảnh đầu vào thành các lưới (grid), sau đó dự đoán bounding box và lớp của các đối tượng nằm trong từng ô lưới đó. Điều đặc biệt ở YOLO là mô hình chỉ cần một lần duyệt qua toàn bộ ảnh (single forward pass) để dự đoán tất cả các bounding box và nhãn của chúng, giúp giảm đáng kể thời gian tính toán so với các mô hình khác.
2. Kiến trúc
Kiến trúc của YOLOv5 có thể được chia thành ba phần chính: Backbone, Neck và Head. Đây là một thiết kế phổ biến trong các mô hình phát hiện đối tượng hiện đại nhằm đảm bảo khả năng trích xuất đặc trưng mạnh mẽ, xử lý nhiều kích thước đối tượng và cuối cùng là dự đoán chính xác bounding box và nhãn.
2.1. Backbone
Backbone là phần mạng nơ-ron chịu trách nhiệm trích xuất các đặc trưng cơ bản từ hình ảnh đầu vào. YOLOv5 sử dụng CSPDarknet53 (Cross Stage Partial Network), một phiên bản cải tiến của Darknet53 được giới thiệu từ YOLOv4. CSPDarknet53 giúp tăng hiệu quả tính toán và giảm bớt chi phí tính toán bằng cách chia nhỏ quá trình tính toán trong các stage (giai đoạn) của mạng.
Backbone bao gồm nhiều lớp convolution và batch normalization nhằm trích xuất các đặc trưng quan trọng từ ảnh đầu vào. Cụ thể:
- Convolution Layers: Các lớp convolution đóng vai trò trích xuất các đặc trưng như cạnh, hình dạng và các chi tiết nhỏ của đối tượng.
- Batch Normalization: Lớp này giúp chuẩn hóa các đặc trưng trong quá trình huấn luyện, tăng tốc độ huấn luyện và giúp mạng hội tụ nhanh hơn.
- Activation Function (Mish): YOLOv5 sử dụng hàm kích hoạt Mish thay vì ReLU hoặc Leaky ReLU thông thường. Mish giúp duy trì thông tin quan trọng trong mạng và cải thiện độ chính xác của mô hình.
2.2. Neck
Neck của YOLOv5 sử dụng hai kỹ thuật nổi bật là Feature Pyramid Network (FPN) và Path Aggregation Network (PANet). Mục tiêu của Neck là kết hợp các đặc trưng từ nhiều cấp độ khác nhau trong Backbone, giúp mô hình dự đoán các đối tượng có kích thước khác nhau (nhỏ, trung bình, lớn).
Feature Pyramid Network (FPN)
FPN giúp tăng cường khả năng phát hiện các đối tượng nhỏ bằng cách kết hợp các đặc trưng từ nhiều lớp khác nhau. Quá trình này giúp thông tin từ các lớp sâu của mạng (các lớp có đặc trưng trừu tượng) được kết hợp với thông tin từ các lớp nông (các lớp chứa đặc trưng chi tiết).
Path Aggregation Network (PANet)
ANet cải thiện việc truyền thông tin qua lại giữa các lớp khác nhau của Backbone, giúp mô hình học được nhiều thông tin hơn về mối quan hệ giữa các đặc trưng. PANet chủ yếu được sử dụng để cải thiện việc phát hiện các đối tượng ở mức độ chi tiết và tăng hiệu suất của mô hình.
2.3. Head
Phần Head của YOLOv5 chịu trách nhiệm dự đoán bounding box, xác suất của đối tượng và nhãn phân loại. Tại mỗi bước trong head, mô hình sẽ trả về các thông tin sau:
Bounding Box
Tọa độ của các hộp bao quanh (bounding box) chứa đối tượng trong ảnh. YOLOv5 sử dụng anchor box để dự đoán bounding box.
Objectness Score
Giá trị dự đoán xác suất có đối tượng trong bounding box.
Class Prediction
Xác suất dự đoán đối tượng thuộc về các lớp đã được định nghĩa trước (ví dụ như người, xe hơi, chó, v.v.).
Head của YOLOv5 hoạt động dựa trên các dự đoán tại mỗi ô lưới (grid cell) được chia từ hình ảnh đầu vào. Mỗi ô lưới sẽ dự đoán bounding box và xác suất của các lớp tương ứng.
3. Nguyên lý hoạt động
Hình ảnh đầu vào được chia thành nhiều ô lưới, mỗi ô lưới tương ứng với một vị trí trong ảnh và dự đoán các bounding box cho các đối tượng trong ô lưới đó. YOLOv5 sử dụng anchor boxes để dự đoán các bounding box, và quá trình này được thực hiện song song với việc dự đoán xác suất của các lớp.
Quá trình này có thể được mô tả bằng công thức:
\[P(c | x, y, w, h) = \sigma(s_c) \cdot \text{IoU}(\text{bbox}_\text{pred}, \text{bbox}_\text{truth})\]
Trong đó:
- \(P(c | x, y, w, h)\): Xác suất đối tượng thuộc lớp \(c\) với bounding box có tọa độ \(x, y\), chiều rộng \(w\), và chiều cao \(h\).
- \(s_c\): Điểm tin cậy (confidence score) của đối tượng trong ô lưới.
- \(\text{IoU}\): Intersection over Union, đánh giá mức độ trùng khớp giữa bounding box dự đoán và bounding box thực tế.
3.1. Intersection over Union (IoU)
Intersection over Union (IoU) là một trong những thước đo quan trọng trong các mô hình phát hiện đối tượng như YOLOv5. IoU đo lường mức độ trùng khớp giữa các hộp giới hạn (bounding boxes) dự đoán và hộp giới hạn thực tế của đối tượng. IoU được tính bằng cách lấy phần giao nhau giữa hai hộp (phần diện tích mà hai hộp cùng bao phủ) chia cho phần hợp lại của chúng (tổng diện tích mà hai hộp bao phủ).
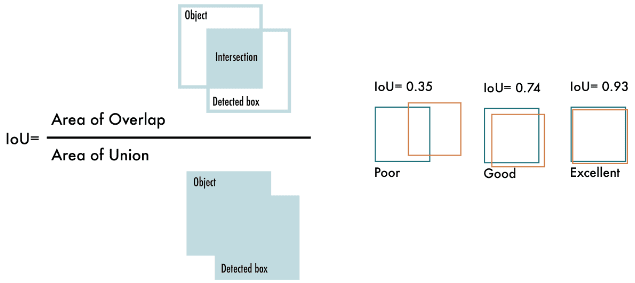
Công thức toán học của IoU được biểu diễn như sau:
\[\text{IoU} = \frac{ \text{Area of Overlap} }{ \text{Area of Union} }\]
Trong đó:
- Area of Overlap: Diện tích giao nhau giữa hộp giới hạn dự đoán và hộp giới hạn thực tế.
- Area of Union: Tổng diện tích của cả hai hộp giới hạn, trừ đi phần giao nhau (nếu có).
Giá trị IoU luôn nằm trong khoảng từ 0 đến 1:
- IoU = 0: Nghĩa là không có sự trùng khớp nào giữa hai hộp.
- IoU = 1: Hai hộp hoàn toàn trùng khớp với nhau.
3.2. Anchor boxes
Trong ảnh có thể chứa nhiều đối tượng với kích thước và hình dạng khác nhau, từ những vật thể nhỏ đến lớn. Thay vì để mô hình tự học cách dự đoán bounding box cho mọi đối tượng từ đầu, ta định nghĩa sẵn các anchor boxes có kích thước khác nhau và cho mô hình dự đoán sự điều chỉnh dựa trên các anchor này. Việc này giúp mô hình dự đoán bounding box nhanh và chính xác hơn.
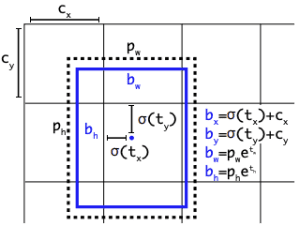
Các anchor boxes được xác định từ trước và cố định trong quá trình huấn luyện. Chúng bao phủ nhiều kích thước và tỷ lệ khung hình để tương thích với các đối tượng có kích thước đa dạng. Mỗi vị trí trên ảnh được gán với một hoặc nhiều anchor boxes, và nhiệm vụ của mô hình là dự đoán độ dời (offset) để điều chỉnh anchor boxes sao cho phù hợp với đối tượng thực tế.
Ví dụ về Anchor Boxes
Giả sử ta có một anchor box với kích thước là (w_a, h_a) ở một vị trí xác định trong ảnh. Mô hình sẽ dự đoán các giá trị độ dời (offset) theo công thức sau:
\[\text{Bounding Box Predicted} = \text{Anchor Box} + \text{Offset}\]
Trong đó:
- \(\text{Anchor Box}\): Kích thước và vị trí của anchor box ban đầu.
- \(\text{Offset}\): Các giá trị điều chỉnh được mô hình dự đoán để điều chỉnh kích thước và vị trí của anchor box sao cho phù hợp với đối tượng thực tế.
3.3. Non-Maximum Suppression (NMS)
Sau khi dự đoán, mô hình thường tạo ra nhiều bounding box cho cùng một đối tượng, do sử dụng nhiều anchor boxes tại cùng một vị trí. Để xử lý điều này, YOLOv5 áp dụng thuật toán Non-Maximum Suppression (NMS) để giữ lại bounding box tốt nhất và loại bỏ các box dư thừa. NMS sử dụng chỉ số Intersection over Union (IoU) để chọn ra bounding box có độ chồng lấp thấp nhất với các bounding box còn lại.

3.4. Loss Function
Hàm mất mát tổng quát của YOLOv5 được biểu diễn như sau:
\[\text{Loss} = \lambda_{\text{box}} \cdot \text{MSE}(\text{bbox}_{\text{pred}}, \text{bbox}_{\text{true}}) + \lambda_{\text{obj}} \cdot \text{BCE}(\hat{o}, o) + \lambda_{\text{cls}} \cdot \text{BCE}(\hat{p}, p)\]
Trong đó:
- \(\text{MSE}\): Mean Squared Error, dùng để đo lường lỗi dự đoán vị trí bounding box.
- \(\text{BCE}\): Binary Cross Entropy, dùng để tính lỗi giữa xác suất dự đoán và giá trị thực tế cho các lớp và đối tượng.
- \(\lambda_{\text{box}}, \lambda_{\text{obj}}, \lambda_{\text{cls}}\): Các hệ số điều chỉnh trọng số của các thành phần khác nhau trong hàm mất mát.
4. Các phiên bản của YOLOv5
YOLOv5 có 5 phiên bản chính: YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, và YOLOv5x. Mỗi phiên bản được thiết kế với quy mô và cấu trúc khác nhau để cân bằng giữa tốc độ xử lý và độ chính xác, giúp người dùng dễ dàng lựa chọn mô hình phù hợp với yêu cầu cụ thể của họ.
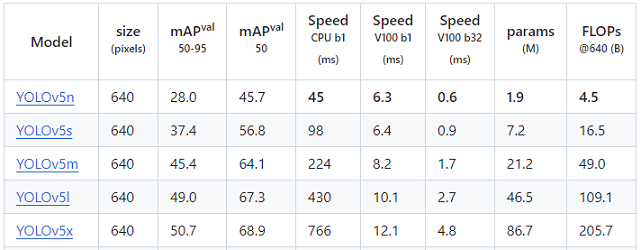
- YOLOv5n (Nano): Phiên bản nhỏ nhất và nhanh nhất, phù hợp với các thiết bị rất hạn chế về tài nguyên như các hệ thống nhúng, thiết bị IoT, hoặc di động. YOLOv5n hy sinh một phần độ chính xác để tăng tối đa tốc độ.
- YOLOv5s (Small): Nhỏ gọn nhưng vẫn giữ được độ chính xác hợp lý, YOLOv5s phù hợp với các tác vụ yêu cầu xử lý thời gian thực mà vẫn đạt được hiệu quả cao.
- YOLOv5m (Medium): Có số lượng tham số và lớp nhiều hơn YOLOv5s, YOLOv5m cải thiện độ chính xác mà vẫn duy trì tốc độ xử lý nhanh.
- YOLOv5l (Large): Phiên bản lớn hơn, cung cấp độ chính xác cao hơn nhưng yêu cầu nhiều tài nguyên tính toán hơn.
- YOLOv5x (Extra Large): Phiên bản lớn nhất với số lượng tham số và lớp nhiều nhất, cung cấp độ chính xác tối đa, phù hợp với các hệ thống tính toán mạnh mẽ.
5. Ứng dụng thực tế
YOLOv5 là một trong những mô hình phát hiện đối tượng tiên tiến và hiệu quả nhất hiện nay. Nhờ tốc độ xử lý nhanh và độ chính xác cao, YOLOv5 đã được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau, từ giám sát an ninh đến xe tự lái. Dưới đây là một số ứng dụng thực tế phổ biến của YOLOv5:
5.1. Giám sát an ninh và phát hiện đối tượng
YOLOv5 được sử dụng rộng rãi trong các hệ thống giám sát an ninh để phát hiện và theo dõi đối tượng trong thời gian thực. Với khả năng phát hiện đối tượng nhanh và hiệu quả, YOLOv5 giúp các camera giám sát tự động nhận diện con người, xe cộ hoặc các hành vi bất thường trong khu vực giám sát. Những hệ thống này có thể được sử dụng tại sân bay, nhà ga, bến xe, hoặc các tòa nhà công cộng nhằm nâng cao mức độ an ninh và phản ứng kịp thời khi có sự cố xảy ra.
Ví dụ:
Các hệ thống camera sử dụng YOLOv5 để nhận diện khuôn mặt, phát hiện các vật thể bỏ quên, hoặc theo dõi hành vi đáng ngờ trong khu vực nhạy cảm.
5.2. Xe tự lái và hệ thống hỗ trợ lái xe
Trong lĩnh vực xe tự lái, YOLOv5 đóng vai trò quan trọng trong việc phát hiện các đối tượng xung quanh xe như phương tiện, người đi bộ, biển báo giao thông, và các vật thể khác. Với khả năng phát hiện đối tượng nhanh và chính xác, mô hình giúp xe tự lái ra quyết định an toàn và phản ứng phù hợp với môi trường giao thông xung quanh.
Ví dụ:
Xe tự lái có thể sử dụng YOLOv5 để phát hiện người qua đường, các phương tiện đang đến gần, hoặc các chướng ngại vật trên đường để từ đó tự động phanh, đổi hướng hoặc điều chỉnh tốc độ.
5.3. Thị giác máy tính trong y tế
YOLOv5 cũng được ứng dụng trong lĩnh vực y tế để hỗ trợ các bác sĩ trong việc phân tích hình ảnh y tế như ảnh X-quang, MRI, và CT-scan. Mô hình này giúp phát hiện nhanh các dấu hiệu bệnh lý từ hình ảnh, hỗ trợ quá trình chẩn đoán và điều trị.
Ví dụ:
YOLOv5 có thể được sử dụng để phát hiện khối u trong ảnh X-quang phổi, giúp bác sĩ phát hiện sớm các dấu hiệu ung thư hoặc các bệnh lý khác.
5.4. Ứng dụng trong bán lẻ và kiểm kê hàng hóa
Trong lĩnh vực bán lẻ, YOLOv5 được sử dụng để theo dõi hàng hóa và kiểm kê hàng tồn kho tự động. Các hệ thống này sử dụng camera để theo dõi hàng hóa trên kệ, phát hiện các sản phẩm bị thiếu hoặc nhận diện hàng hóa không đúng vị trí. Điều này giúp các cửa hàng giảm thiểu việc thất thoát và tối ưu hóa quá trình quản lý kho hàng.
Ví dụ:
Một hệ thống kiểm kê tự động sử dụng YOLOv5 có thể quét toàn bộ cửa hàng và phát hiện các sản phẩm cần được bổ sung kịp thời, đồng thời giúp quản lý kho chính xác hơn.
5.5. Ứng dụng trong nông nghiệp thông minh
YOLOv5 cũng đã tìm được ứng dụng trong lĩnh vực nông nghiệp thông minh, nơi mô hình này được sử dụng để giám sát cây trồng, phát hiện sâu bệnh, và tự động thu hoạch. Các drone được trang bị camera có thể bay qua các cánh đồng và sử dụng YOLOv5 để nhận diện cây trồng bị bệnh hoặc phát hiện các khu vực cần tưới nước, bón phân.
Ví dụ:
Hệ thống nông nghiệp thông minh sử dụng YOLOv5 để phát hiện sâu bệnh trên cây trồng, giúp nông dân kịp thời điều trị và giảm thiểu thiệt hại.
5.6. Ứng dụng trong thể thao
Trong thể thao, YOLOv5 được sử dụng để theo dõi các vận động viên, phân tích hiệu suất và cung cấp thông tin trong thời gian thực. Nhờ khả năng phát hiện và theo dõi đối tượng nhanh, YOLOv5 có thể phân tích các chuyển động của cầu thủ, giám sát vị trí của bóng, và hỗ trợ trong việc phân tích chiến thuật thi đấu.
Ví dụ:
Hệ thống camera thể thao có thể sử dụng YOLOv5 để theo dõi và phân tích chuyển động của cầu thủ trong suốt trận đấu, từ đó cung cấp các dữ liệu hữu ích cho huấn luyện viên và đội ngũ phân tích.
6. Kết luận
YOLOv5 là một mô hình mạnh mẽ và tiên tiến trong lĩnh vực phát hiện đối tượng. Với kiến trúc tối ưu và khả năng phát hiện nhanh chóng, YOLOv5 đã trở thành một lựa chọn hàng đầu cho các ứng dụng thời gian thực. Hiểu rõ về cách hoạt động của mô hình này không chỉ giúp bạn phát triển các giải pháp phát hiện đối tượng hiệu quả mà còn mở ra nhiều cơ hội ứng dụng trong các ngành công nghiệp khác nhau.