Tổng quan 4 phương pháp học máy chính trong trí tuệ nhân tạo
1. Giới thiệu về học máy
Học máy (Machine Learning) là một nhánh của trí tuệ nhân tạo (AI) tập trung vào việc phát triển các thuật toán và mô hình giúp máy tính có thể học từ dữ liệu và đưa ra quyết định hoặc dự đoán mà không cần lập trình cụ thể cho từng tác vụ.
Các phương pháp học máy phổ biến hiện nay bao gồm học máy có giám sát (Supervised Learning), học máy không giám sát (Unsupervised Learning), học máy bán giám sát (Semi-Supervised Learning) và học tăng cường (Reinforcement Learning). Mỗi phương pháp có những đặc điểm riêng, được sử dụng trong các trường hợp khác nhau, và có ưu điểm cũng như nhược điểm riêng.
2. Học máy có giám sát (Supervised Learning)
2.1. Định nghĩa
Học máy có giám sát là phương pháp học máy mà trong đó mô hình được huấn luyện trên một tập dữ liệu được gán nhãn sẵn. Dữ liệu đầu vào (input) được liên kết với các nhãn đầu ra (output) mong muốn, và mục tiêu của mô hình là học cách ánh xạ từ đầu vào đến đầu ra dựa trên các cặp dữ liệu này.
2.2. Nguyên lý hoạt động
- Dữ liệu huấn luyện: Bao gồm các cặp dữ liệu đầu vào và đầu ra (ví dụ: hình ảnh của một con chó và nhãn “chó”).
- Quá trình huấn luyện: Mô hình học cách dự đoán đầu ra từ đầu vào bằng cách tối ưu hóa một hàm mất mát (loss function), thường là sự khác biệt giữa dự đoán của mô hình và nhãn thực tế.
- Kiểm tra: Sau khi huấn luyện, mô hình được kiểm tra trên dữ liệu chưa từng thấy để đánh giá độ chính xác và khả năng tổng quát hóa.
2.3. Ưu điểm và nhược điểm
- Ưu điểm:
- Hiệu quả cao với các bài toán có dữ liệu gán nhãn đầy đủ.
- Dễ dàng đánh giá hiệu suất mô hình nhờ vào các số liệu như độ chính xác (accuracy), F1-score, và AUC.
- Nhược điểm:
- Yêu cầu lượng lớn dữ liệu được gán nhãn, tốn kém và mất thời gian để thu thập.
- Không linh hoạt với dữ liệu mới hoặc thay đổi.
2.4. Ứng dụng
- Phân loại hình ảnh: Phân loại hình ảnh vào các danh mục như nhận diện đối tượng, phân loại thư mục.
- Dự đoán tài chính: Dự đoán giá cổ phiếu, rủi ro tín dụng dựa trên dữ liệu lịch sử.
- Xử lý ngôn ngữ tự nhiên (NLP): Phân loại email, phân tích cảm xúc, dịch máy.
3. Học máy không giám sát (Unsupervised Learning)
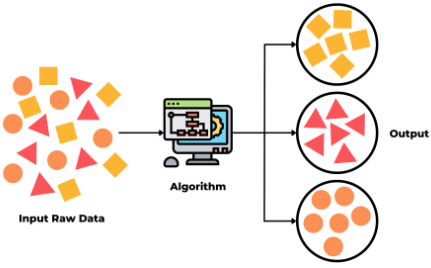
3.1. Định nghĩa
Học máy không giám sát là phương pháp trong đó mô hình được huấn luyện trên một tập dữ liệu không có nhãn. Mục tiêu của mô hình là tìm ra các mẫu (patterns) hoặc cấu trúc tiềm ẩn trong dữ liệu mà không cần biết trước đầu ra mong muốn.
3.2. Nguyên lý hoạt động
- Dữ liệu huấn luyện: Chỉ bao gồm dữ liệu đầu vào mà không có nhãn.
- Quá trình huấn luyện: Mô hình cố gắng nhóm các dữ liệu tương tự nhau (clustering) hoặc giảm số chiều của dữ liệu để dễ dàng phân tích (dimensionality reduction).
- Kiểm tra: Không có một số liệu rõ ràng để đánh giá, thường dựa trên sự quan sát của con người hoặc sử dụng các biện pháp đánh giá như silhouette score trong clustering.
3.3. Ưu điểm và nhược điểm
- Ưu điểm:
- Không cần dữ liệu được gán nhãn, do đó tiết kiệm chi phí và thời gian.
- Phù hợp để khám phá dữ liệu và phát hiện các mẫu mới mà không bị ảnh hưởng bởi định kiến gán nhãn.
- Nhược điểm:
- Khó đánh giá hiệu suất và chất lượng của mô hình.
- Dễ bị ảnh hưởng bởi nhiễu và sự đa dạng trong dữ liệu.
3.4. Ứng dụng
- Phân cụm khách hàng: Phân nhóm khách hàng thành các phân khúc để cá nhân hóa chiến lược marketing.
- Giảm số chiều dữ liệu: Sử dụng phương pháp PCA (Principal Component Analysis) để giảm số chiều của dữ liệu cho việc trực quan hóa và tăng tốc độ xử lý.
- Phát hiện bất thường: Tìm ra các mẫu bất thường trong dữ liệu tài chính hoặc dữ liệu y tế.
4. Học máy bán giám sát (Semi-Supervised Learning)
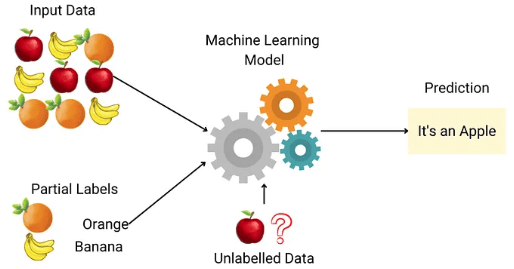
4.1. Định nghĩa
Học máy bán giám sát là phương pháp kết hợp giữa học máy có giám sát và không giám sát. Trong đó, một phần nhỏ của dữ liệu huấn luyện được gán nhãn, còn lại là dữ liệu không gán nhãn. Mục tiêu là tận dụng thông tin từ cả dữ liệu được gán nhãn và không gán nhãn để cải thiện độ chính xác của mô hình.
4.2. Nguyên lý hoạt động
- Dữ liệu huấn luyện: Bao gồm một phần nhỏ dữ liệu được gán nhãn và phần lớn dữ liệu không có nhãn.
- Quá trình huấn luyện: Mô hình học từ dữ liệu gán nhãn và sử dụng dữ liệu không gán nhãn để tìm ra cấu trúc tiềm ẩn, sau đó cải thiện dự đoán cho các dữ liệu chưa được gán nhãn.
- Kiểm tra: Được thực hiện trên tập dữ liệu không gán nhãn hoặc trên một tập dữ liệu kiểm tra riêng biệt.
4.3. Ưu điểm và nhược điểm
Ưu điểm:
- Hiệu quả hơn so với học máy có giám sát khi chỉ có một lượng nhỏ dữ liệu gán nhãn.
- Tận dụng được thông tin từ dữ liệu không gán nhãn để cải thiện hiệu suất mô hình.
Nhược điểm:
- Phức tạp hơn về mặt triển khai so với học máy có giám sát.
- Đòi hỏi sự cân nhắc cẩn thận trong việc lựa chọn dữ liệu và phương pháp huấn luyện.
4.4. Ứng dụng
Phân loại văn bản
- Dùng một số lượng nhỏ tài liệu được gán nhãn để phân loại toàn bộ cơ sở dữ liệu văn bản.
Nhận diện hình ảnh
- Sử dụng một tập nhỏ hình ảnh được gán nhãn để huấn luyện mô hình và sau đó áp dụng lên một tập lớn hình ảnh không gán nhãn.
Phân tích y học
- Phân loại hình ảnh y tế với một số lượng nhỏ các hình ảnh được chuyên gia y tế gán nhãn.
5. Học tăng cường (Reinforcement Learning)
5.1. Định nghĩa
Học tăng cường (Reinforcement Learning – RL) là một phương pháp học máy, trong đó một tác nhân (agent) học cách thực hiện các hành động trong một môi trường để tối ưu hóa phần thưởng nhận được theo thời gian. Tác nhân không được cung cấp sẵn nhãn cho từng hành động, mà thay vào đó, nó phải khám phá môi trường và học từ những kinh nghiệm thông qua tương tác.
5.2. Nguyên lý hoạt động
Học tăng cường hoạt động dựa trên một chu trình lặp lại giữa tác nhân và môi trường. Tác nhân thực hiện một hành động dựa trên trạng thái hiện tại của môi trường, và nhận được phần thưởng cùng với trạng thái mới. Mục tiêu của tác nhân là tối đa hóa tổng phần thưởng nhận được trong dài hạn. Một số thuật toán phổ biến trong học tăng cường bao gồm Q-learning, SARSA, và Deep Q-Network (DQN).
5.3. Ưu điểm và nhược điểm
Ưu điểm:
Tính tự động hóa
- Học tăng cường có khả năng học và điều chỉnh chiến lược mà không cần can thiệp của con người sau khi được thiết lập.
Khả năng thích ứng
- Tác nhân có thể thích ứng với các thay đổi trong môi trường và tối ưu hóa chiến lược để đạt hiệu suất cao hơn.
Ứng dụng rộng rãi
- RL có thể được áp dụng trong nhiều lĩnh vực khác nhau như trò chơi, robot, và tối ưu hóa các hệ thống phức tạp.
Nhược điểm:
Thời gian học lâu
- Để đạt được chiến lược tối ưu, RL thường yêu cầu thời gian học rất dài, đặc biệt là trong các môi trường phức tạp.
Độ khó trong việc thiết lập
- Việc thiết lập các tham số và môi trường học tăng cường có thể phức tạp và đòi hỏi nhiều kinh nghiệm.
Rủi ro khám phá
- Trong quá trình khám phá môi trường, tác nhân có thể thực hiện các hành động gây hại hoặc không hiệu quả trước khi tìm được chiến lược tối ưu.
5.4. Ứng dụng
Học tăng cường đã được ứng dụng thành công trong nhiều lĩnh vực như:
Trò chơi điện tử
- RL đã được sử dụng để phát triển các tác nhân chơi game có khả năng vượt qua con người, như AlphaGo của Google DeepMind.
Robot học
- Các robot có thể sử dụng RL để học cách di chuyển, tương tác với môi trường và hoàn thành các nhiệm vụ phức tạp.
Tối ưu hóa hệ thống
- RL được áp dụng để tối ưu hóa các hệ thống phức tạp như mạng lưới giao thông, quản lý năng lượng, và tài chính.
6. Kết luận
Học máy có giám sát, không giám sát, bán giám sát và học tăng cường đều là những phương pháp quan trọng trong lĩnh vực học máy, mỗi phương pháp có ưu và nhược điểm riêng và phù hợp với các loại dữ liệu và ứng dụng khác nhau. Việc hiểu rõ sự khác biệt giữa chúng sẽ giúp bạn chọn phương pháp phù hợp nhất cho các bài toán cụ thể, từ đó tối ưu hóa hiệu suất và hiệu quả của các hệ thống AI.