Ứng dụng mạng SSD300 vào nhận diện đối tượng
1. Bài toán
Xây dựng một hệ thống phát hiện và nhận diện đối tượng dựa trên mạng SSD300. Hệ thống này sẽ xác định đối tượng bằng cách khoanh hình chữ nhật bao quanh đối tượng và hiển thị tên của đối tượng, sau đó lưu lại hình ảnh đã có thông tin này.

2. Thực hiện
2.1. Cấu trúc chương trình
Với mục đích dễ quản lý source code, chúng ta có thể đặt chương trình như sau:
root@aicandy:/aicandy/projects/AIcandy_SSD300_ObjectDetection_urentmnt# tree
.
├── aicandy_output_gnloibxd
├── aicandy_ssd300_convert_rqicuvtl.py
├── aicandy_ssd300_test_qgtlqrlv.py
├── aicandy_ssd300_train_haykkxnu.py
├── aicandy_utils_src_lkkqrsdm
│ ├── aicandy_ssd300_datasets_kgvvoaac_ok.py
│ ├── aicandy_ssd300_datasets_kgvvoaac.py
│ ├── aicandy_ssd300_model_tahusyda.py
│ ├── aicandy_ssd300_utils_xslstyan.py
│ └── arial.ttf
└── image_test.jpgTrong đó:
– File aicandy_ssd300_model_tahusyda.py chứa model
– File aicandy_ssd300_train_haykkxnu.py chứa chương trình train
– File aicandy_ssd300_test_qgtlqrlv.py chứa chương trình để test.
– File aicandy_ssd300_convert_rqicuvtl.py chứa chương trình chuyển đổi từ model pytorch sang model onnx phục vụ triển khai model trên nhiều thiết bị khác nhau.
2.2. Dữ liệu
Dữ liệu phục vụ cho việc train gồm các ảnh đã được xác định đối tượng bằng các bouding box và đánh nhãn trong file json.
Bộ dataset có cấu trúc như sau:
root@aicandy:/aicandy/datasets/aicandy_obj_nskpbsgv# ls
images label_map.json test_images.json test_objects.json train_images.json train_objects.json
root@aicandy:/aicandy/datasets/aicandy_obj_nskpbsgv# cd images/
root@aicandy:/aicandy/datasets/aicandy_obj_nskpbsgv/images# tree | head -n 6
.
├── 000001.jpg
├── 000002.jpg
├── 000003.jpg
├── 000004.jpg
├── 000005.jpg
root@aicandy:/aicandy/datasets/aicandy_obj_nskpbsgv/images#– File label_map.json chứa thông tin về classes trong bộ dataset
– File test_images.json chứa đường dẫn ảnh phục vụ ‘validation’ model
– File test_objects.json chứa thông tin về bounding box, labels của đối tượng chứa trong ảnh validation.
– File train_images.json chứa đường dẫn tới file ảnh để train.
– File train_objects.json chứa thông tin về bounding box, labels của đối tượng chứa trong ảnh train.
Bộ dữ liệu sử dụng trong bài là aicandy_obj_nskpbsgv được download miễn phí tại Kho dữ liệu dành cho học máy
2.3. Build model
Xây dựng mô hình gồm các thành phần chính:
class VGGBase(nn.Module):
SSD300 được xây đựng dựa trên mạng cơ sở VGG16
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, padding=1):
Tạo một lớp tích chập (convolutional layer) với đầu vào có 3 kênh (RGB), 64 kênh đầu ra, kích thước kernel là 3×3, và thêm padding 1 để giữ kích thước của ảnh không thay đổi sau tích chập.
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
Tương tự như trên nhưng đầu vào là 64 kênh (kết quả từ conv1_1), và đầu ra vẫn là 64 kênh.
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
Tạo một lớp pooling dùng để giảm kích thước không gian của đặc trưng (feature map) với kích thước kernel 2×2 và bước di chuyển là 2.
Tạo tương tự để có nhiều layer Conv2d với đầu ra là 1024 kênh.
self.load_pretrained_layers()
Tải các trọng số đã được huấn luyện trước đó vào mô hình
class AuxiliaryConvolutions(nn.Module):
Tạo lớp dự đoán vị trí của các hộp giới hạn (bounding boxes) và các lớp của đối tượng trong các hộp đó.
self.loc_conv4_3 = nn.Conv2d(512, n_boxes[‘conv4_3’] * 4, kernel_size=3, padding=1)
Định nghĩa các lớp tích chập cho dự đoán vị trí (localization) của các hộp giới hạn. 512 là số lượng kênh đầu vào (input channels), n_boxes[‘conv4_3’] * 4 là số lượng kênh đầu ra (output channels), trong đó * 4 vì mỗi hộp cần 4 giá trị để định nghĩa vị trí (x, y, w, h).
self.cl_conv4_3 = nn.Conv2d(512, n_boxes[‘conv4_3’] * n_classes, kernel_size=3, padding=1)
Định nghĩa các lớp tích chập cho dự đoán lớp (class prediction) của đối tượng trong mỗi hộp. n_boxes[‘conv4_3’] * n_classes là số lượng kênh đầu ra, trong đó mỗi hộp cần một dự đoán lớp cho từng lớp đối tượng.
class SSD300(nn.Module):
đại diện cho mô hình SSD (Single Shot Multibox Detector) với đầu vào kích thước 300×300.
self.aux_convs = AuxiliaryConvolutions()
self.aux_convs đại diện cho các lớp tích chập phụ (auxiliary convolutions), được thêm vào để trích xuất thêm các đặc trưng từ các mức độ khác nhau của ảnh. Những lớp này giúp mô hình dự đoán các đối tượng ở các kích thước khác nhau.
self.pred_convs = PredictionConvolutions(n_classes)
self.pred_convs đại diện cho các lớp tích chập dự đoán (prediction convolutions), được sử dụng để dự đoán vị trí và lớp của các đối tượng trong ảnh. Đây là lớp đã được giải thích ở câu hỏi trước.
self.priors_cxcy = self.create_prior_boxes()
create_prior_boxes() Hộp prior là các hộp giới hạn với kích thước và tỷ lệ khung hình (aspect ratios) khác nhau, được đặt cố định trên ảnh đầu vào. Chúng được sử dụng làm cơ sở để dự đoán vị trí của các đối tượng.
def detect_objects(self, predicted_locs, predicted_scores, min_score, max_overlap):
Tạo hàm để phát hiện các đối tượng trong ảnh từ các đầu ra của mô hình (vị trí dự đoán và điểm số dự đoán), trong đó:
- predicted_locs: Các vị trí dự đoán của các hộp giới hạn.
- predicted_scores: Các điểm số dự đoán cho mỗi hộp và mỗi lớp.
- min_score: Ngưỡng điểm số tối thiểu mà một hộp giới hạn phải đạt được để được coi là phát hiện một đối tượng.
- max_overlap: Ngưỡng tối đa cho phép của sự chồng lấn (overlap) giữa các hộp giới hạn, được sử dụng để thực hiện NMS (Non-Maximum Suppression).
gcxgcy_to_cxcy(predicted_locs[i], self.priors_cxcy))
Tạo hàm giải mã các tọa độ dự đoán của các hộp giới hạn từ định dạng mà mô hình sử dụng sang định dạng (x_min, y_min, x_max, y_max) truyền thống, sau đó lưu trữ các hộp, nhãn và điểm số tương ứng.
overlap = find_jaccard_overlap(class_decoded_locs, class_decoded_locs)
Tính toán độ chồng lấn giữa tất cả các hộp giới hạn được dự đoán cho một lớp đối tượng cụ thể trong một ảnh. Độ chồng lấn này thường được gọi là IoU (Intersection over Union) và được sử dụng để xác định mức độ chồng lấn giữa hai hộp giới hạn.
class MultiBoxLoss(nn.Module):
Tính toán hàm mất mát (loss function) cho mô hình SSD (Single Shot MultiBox Detector). Đây là một hàm mất mát kết hợp giữa hàm mất mát tọa độ (localization loss) và hàm mất mát phân loại (confidence loss). Lớp này triển khai một trong những yếu tố quan trọng nhất của SSD: nó xác định cách mà mô hình học cách phát hiện các đối tượng trong ảnh.
self.smooth_l1 = nn.L1Loss()
Sử dụng để tính localization loss (mất mát về vị trí). Đây là phần của hàm mất mát chịu trách nhiệm đo lường mức độ chính xác của mô hình khi dự đoán vị trí của các hộp giới hạn (bounding boxes) so với vị trí thực tế (ground truth).
self.cross_entropy = nn.CrossEntropyLoss(reduction=’none’)
sử dụng để tính confidence loss (mất mát về độ tin cậy). Đây là phần của hàm mất mát đánh giá mức độ chính xác của mô hình khi phân loại các đối tượng trong hộp giới hạn.
2.4. Chương trình train
Bước 1: lựa chọn sử dụng CPU hay GPU để train, chúng ta sử dụng câu lệnh:
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
Bước 2: Kiểm tra xem train từ đầu hay train từ 1 bản checkpoint đã train rồi (train tiếp từ checkpoint đã có).
Với train từ đầu:
Khởi tạo một mô hình SSD300 mới với số lượng lớp là num_classes.
optimizer = torch.optim.SGD(params=[{‘params’: bias_params, ‘lr’: 2 * learning_rate}, {‘params’: non_bias_params}],
lr=learning_rate, momentum=optim_momentum, weight_decay=weight_decay_factor)
Các tham số bias có một learning rate gấp đôi so với các tham số còn lại (2 * learning_rate). Điều này có thể giúp tăng tốc độ hội tụ cho các tham số bias.
Momentum và weight decay được sử dụng để cải thiện quá trình tối ưu hóa.
Với trường hợp train tiếp từ checkpoint:
torch.load(model_checkpoint):
Sử dụng torch.load để tải bộ trọng số tử checkpoint đã có.
optimizer = model_checkpoint[‘optimizer’]
Trạng thái của optimizer cũng được tải từ checkpoint, điều này đảm bảo rằng quá trình huấn luyện tiếp tục đúng với những gì đã diễn ra trước đó.
Bước 3: Thiết lập hàm mất mát
criterion = MultiBoxLoss(priors_cxcy=model.priors_cxcy).to(device)
Thiết lập hàm mất mát (loss function) cho mô hình SSD và di chuyển nó đến thiết bị (CPU hoặc GPU) để phù hợp với môi trường huấn luyện. Hàm mất mát này được định nghĩa trong file model.
.to(device): Phương thức này di chuyển đối tượng (trong trường hợp này là hàm mất mát criterion) tới thiết bị được chỉ định. Điều này đảm bảo rằng tất cả các phép toán liên quan đến hàm mất mát đều diễn ra trên thiết bị phù hợp, giúp tăng tốc quá trình huấn luyện nếu sử dụng GPU.
Bước 4: Load dataset
with open(os.path.join(folder_path, self.dataset_split + ‘_images.json’), ‘r’) as img_file:
self.image_list = json.load(img_file)
with open(os.path.join(folder_path, self.dataset_split + ‘_objects.json’), ‘r’) as obj_file:
self.object_list = json.load(obj_file)
Sử dụng json.load Đọc nội dung của tệp JSON và chuyển đổi nó thành một đối tượng list.
Các đối tượng Python được lưu vào các thuộc tính của lớp (self.image_list và self.object_list) để sử dụng trong các bước xử lý tiếp theo.
__getitem__(self, index)
Sử dụng phương thức trong lớp tùy chỉnh __getitem__, được sử dụng trong các lớp kế thừa từ torch.utils.data.Dataset để lấy một mục dữ liệu từ dataset.
bbox = torch.FloatTensor(obj_details[‘boxes’])
obj_labels = torch.LongTensor(obj_details[‘labels’])
obj_difficulties = torch.ByteTensor(obj_details[‘difficulties’])
- torch.FloatTensor(obj_details[‘boxes’]):
- obj_details[‘boxes’]: Một danh sách các bounding box, mỗi bounding box là một danh sách chứa tọa độ của nó.
- torch.FloatTensor(…): Chuyển đổi danh sách các bounding box thành tensor kiểu Float, phù hợp với định dạng yêu cầu của mô hình.
- torch.LongTensor(obj_details[‘labels’]):
- obj_details[‘labels’]: Một danh sách các nhãn của các đối tượng, có thể là các chỉ số lớp.
- torch.LongTensor(…): Chuyển đổi danh sách các nhãn thành tensor kiểu Long, thường dùng để biểu diễn các chỉ số lớp trong PyTorch.
- torch.ByteTensor(obj_details[‘difficulties’]):
- obj_details[‘difficulties’]: Một danh sách các giá trị khó khăn của các đối tượng, thường là các giá trị nhị phân hoặc boolean.
- torch.ByteTensor(…): Chuyển đổi danh sách các giá trị difficulties thành tensor kiểu Byte, phù hợp với các giá trị nhị phân.
collate_fn(self, batch)
Hàm collate_fn được sử dụng để hợp nhất các mục dữ liệu từ một batch thành các tensor lớn hơn để có thể được sử dụng cho việc huấn luyện hoặc kiểm tra mô hình.
for i, (images, boxes, labels, _) in enumerate(train_loader):
images = images.to(device)
boxes = [b.to(device) for b in boxes]
labels = [l.to(device) for l in labels]
predicted_locs, predicted_scores = model(images)
loss = criterion(predicted_locs, predicted_scores, boxes, labels)
Xử lý và tính toán loss cho mỗi batch_size, trong đó hàm mất mát (loss function) được định nghĩa để tính toán độ lỗi giữa các dự đoán của mô hình và các giá trị thực tế.
Bước 5: Lưu checkpoint nếu loss mới nhỏ hơn loss đã lưu trước đó.
if loss < min_loss:
min_loss = loss
save_checkpoint(epoch, model, optimizer)
print(f’Saved best model with loss: {min_loss:.4f}’)
2.5. Chương trình test
Bước 1: Load checkpoint và chuyển model về chế độ đánh giá
checkpoint = torch.load(checkpoint, map_location=device)
model.eval()
model.eval() chuyển mô hình sang chế độ đánh giá (evaluation mode), vô hiệu hóa dropout và batch normalization (nếu có) để mô hình có thể thực hiện dự đoán chính xác hơn.
Bước 2: Resize ảnh về cùng chuẩn với ảnh khi train và thực hiện transform
resize = transforms.Resize((300, 300))
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
- mean=[0.485, 0.456, 0.406] và std=[0.229, 0.224, 0.225] là các giá trị trung bình và độ lệch chuẩn được sử dụng để chuẩn hóa các kênh màu của hình ảnh (thông thường tương ứng với các kênh RGB).
- Chuẩn hóa giúp mô hình học sâu hoạt động tốt hơn bằng cách làm cho các giá trị đầu vào có phạm vi tương đồng hơn.
Bước 3: Thực hiện dự đoán về thông tin có trong ảnh
predicted_locs, predicted_scores = model(image.unsqueeze(0))
image.unsqueeze(0)
image là một tensor có thể có kích thước [C, H, W] (trong đó C là số kênh, H là chiều cao và W là chiều rộng).
image.unsqueeze(0) sẽ thêm một chiều mới ở vị trí đầu tiên, biến tensor thành kích thước [1, C, H, W]. Điều này là cần thiết để phù hợp với format của model khi train.
predicted_locs: là một tensor chứa tọa độ các bounding boxes (vị trí) được mô hình dự đoán cho các đối tượng trong hình ảnh.
predicted_scores: là một tensor chứa các điểm số dự đoán (xác suất hoặc confidence scores) cho từng bounding box, tương ứng với các lớp khác nhau trong mô hình.
det_boxes, det_labels, det_scores = model.detect_objects(predicted_locs, predicted_scores, min_score=min_score, max_overlap=max_overlap)
- Sử dụng model.detect_objects để thực hiện quá trình nén non-maximum suppression (NMS) và lọc các dự đoán.
- min_score: Điểm số tối thiểu mà một bounding box cần có để được coi là một dự đoán hợp lệ. Những dự đoán có điểm số thấp hơn min_score sẽ bị loại bỏ.
- max_overlap: Ngưỡng tối đa cho phép của tỷ lệ chồng lấp giữa các bounding boxes. NMS sẽ giữ lại bounding box có điểm số cao nhất và loại bỏ những cái khác có mức độ chồng lấp cao hơn max_overlap.
Bước 4: Vẽ khung và dán nhãn cho đối tượng
draw.rectangle(xy=box_location, outline=label_color_map[det_labels[i]])
draw.rectangle(xy=[l + 1. for l in box_location], outline=label_color_map[det_labels[i]])
draw.rectangle(xy=[l + 2. for l in box_location], outline=label_color_map[det_labels[i]])
draw.rectangle(xy=[l + 3. for l in box_location], outline=label_color_map[det_labels[i]])
draw.text(xy=text_location, text=text, fill=’white’, font=font)
Sử dụng thư viện ImageDraw trong PIL để thực hiện vẽ các bounding boxes xung quanh đối tượng đã được phát hiện với các đường viền dày hơn và có màu sắc dựa trên nhãn của từng đối tượng.
2.6. Chương trình chuyển đổi model
Bước 1: Khởi tạo model và đưa model về chế độ đánh giá
checkpoint = torch.load(checkpoint_path, map_location=’cpu’)
model = SSD300(n_classes=n_classes)
model.load_state_dict(checkpoint[‘model’].state_dict())
model.eval()
model.eval() chuyển mô hình sang chế độ đánh giá (evaluation mode), vô hiệu hóa dropout và batch normalization (nếu có) để mô hình có thể thực hiện dự đoán chính xác hơn.
Bước 2: Xuất mô hình sang onnx
torch.onnx.export(model, dummy_input, onnx_path,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=[‘input’],
output_names=[‘locations’, ‘class_scores’],
dynamic_axes={‘input’: {0: ‘batch_size’},
‘locations’: {0: ‘batch_size’},
‘class_scores’: {0: ‘batch_size’}})
export_params=True: Nếu True, tất cả các tham số của mô hình (weights và biases) sẽ được lưu trữ trong tệp ONNX. Điều này giúp đảm bảo mô hình ONNX có thể được sử dụng ngay mà không cần tham số bên ngoài.
do_constant_folding=True: Khi True, quá trình “constant folding” sẽ được thực hiện. Đây là kỹ thuật tối ưu hóa trong đó các biểu thức có giá trị không đổi sẽ được tính toán trước và lưu trữ dưới dạng giá trị cố định trong mô hình ONNX. Điều này giúp tăng hiệu suất của mô hình trong quá trình suy luận.
3. Kết quả train
Thực hiện train với epoch 500, sai số thấp nhất là 0.5266, đạt được ở epoch 496. Đây là chương trình mẫu, để tăng độ chính xác, chúng ta cũng cần điều chỉnh thêm một số tham số, tăng epoch cũng như tăng số lượng mẫu. Dưới đây là log train ở 50 epoch cuối:
Epoch [451/500], Loss: 1.9724
Epoch [452/500], Loss: 1.3054
Epoch [453/500], Loss: 1.4420
Epoch [454/500], Loss: 2.3634
Epoch [455/500], Loss: 1.6822
Epoch [456/500], Loss: 1.2972
Epoch [457/500], Loss: 1.5108
Epoch [458/500], Loss: 1.5547
Epoch [459/500], Loss: 0.8404
Saved best model with loss: 0.8404
Epoch [460/500], Loss: 1.3319
Epoch [461/500], Loss: 1.3806
Epoch [462/500], Loss: 1.2653
Epoch [463/500], Loss: 1.7959
Epoch [464/500], Loss: 1.8718
Epoch [465/500], Loss: 1.3260
Epoch [466/500], Loss: 1.4745
Epoch [467/500], Loss: 1.6370
Epoch [468/500], Loss: 1.5249
Epoch [469/500], Loss: 1.5585
Epoch [470/500], Loss: 1.8633
Epoch [471/500], Loss: 1.3570
Epoch [472/500], Loss: 1.4954
Epoch [473/500], Loss: 1.6374
Epoch [474/500], Loss: 2.6870
Epoch [475/500], Loss: 1.1409
Epoch [476/500], Loss: 1.0631
Epoch [477/500], Loss: 1.7663
Epoch [478/500], Loss: 1.7983
Epoch [479/500], Loss: 0.8267
Saved best model with loss: 0.8267
Epoch [480/500], Loss: 2.1896
Epoch [481/500], Loss: 3.2248
Epoch [482/500], Loss: 0.9545
Epoch [483/500], Loss: 2.1468
Epoch [484/500], Loss: 1.3124
Epoch [485/500], Loss: 1.2318
Epoch [486/500], Loss: 1.7113
Epoch [487/500], Loss: 0.7660
Saved best model with loss: 0.7660
Epoch [488/500], Loss: 1.8685
Epoch [489/500], Loss: 2.6370
Epoch [490/500], Loss: 2.2104
Epoch [491/500], Loss: 1.5808
Epoch [492/500], Loss: 2.0320
Epoch [493/500], Loss: 1.6568
Epoch [494/500], Loss: 1.7546
Epoch [495/500], Loss: 0.9757
Epoch [496/500], Loss: 0.5266
Saved best model with loss: 0.5266
Epoch [497/500], Loss: 1.0903
Epoch [498/500], Loss: 1.5227
Epoch [499/500], Loss: 1.5718
Epoch [500/500], Loss: 1.75284. Kết quả test
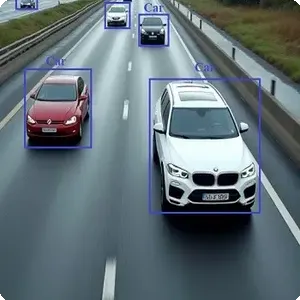
Thử nghiệm với một số ảnh, chương trình đã xác định vị trí tốt các đối tượng có trong ảnh.
root@aicandy:/aicandy/projects/AIcandy_SSD300_ObjectDetection_urentmnt# python aicandy_ssd300_test_qgtlqrlv.py --image_path image_test.jpg --checkpoint aicandy_output_gnloibxd/aicandy_checkpoint_ssd300.pth
Loaded checkpoint from epoch 496.
The results have been saved in: output/image_output.jpg
root@aicandy:/aicandy/projects/AIcandy_SSD300_ObjectDetection_urentmnt#
5. Source code
Toàn bộ source code được public miễn phí tại đây