Xử lý ngôn ngữ NLP: đột phá phân tích văn bản bằng AI
1. Giới thiệu
Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) là một lĩnh vực thuộc trí tuệ nhân tạo (AI) chuyên nghiên cứu cách thức máy tính tương tác với ngôn ngữ con người. NLP tập trung vào việc phát triển các thuật toán và mô hình giúp máy tính có thể hiểu, phân tích, tạo ra và phản hồi ngôn ngữ tự nhiên của con người. Từ việc hiểu các lệnh thoại trong trợ lý ảo như Siri và Google Assistant, đến dịch ngôn ngữ tự động qua các công cụ như Google Dịch, hay phân tích cảm xúc và ý kiến từ các bài viết trên mạng xã hội, NLP đang trở thành một phần không thể thiếu trong cuộc sống và công việc hiện đại.

2. Các thành thần chính của NLP
Xử lý ngôn ngữ tự nhiên (NLP) bao gồm nhiều bước và phương pháp khác nhau để phân tích và hiểu ngôn ngữ của con người. Dưới đây là các thành phần chính thường được sử dụng trong quy trình xử lý NLP:

2.1. Phân tích cú pháp (Syntax Analysis)
Phân tích cú pháp là quá trình xác định cấu trúc ngữ pháp của câu, đảm bảo rằng câu đó tuân thủ các quy tắc ngữ pháp của ngôn ngữ. Bước này thường bao gồm:
Xác định các thành phần của câu
Chủ ngữ, động từ, tân ngữ, v.v.
Phân tích cấu trúc cây (parse tree)
Cấu trúc cây biểu diễn cách các từ trong câu kết hợp với nhau dựa trên ngữ pháp.
Ví dụ
Câu “Con mèo bắt con chuột” sẽ được phân tích cú pháp thành một cây, trong đó “Con mèo” là chủ ngữ, “bắt” là động từ, và “con chuột” là tân ngữ.
Ý nghĩa
Phân tích cú pháp giúp hiểu cấu trúc ngữ pháp của câu và đóng vai trò quan trọng trong việc tạo ra các hệ thống dịch thuật tự động hoặc sinh văn bản.
2.2. Phân tích ngữ nghĩa (Semantic Analysis)
Phân tích ngữ nghĩa là quá trình hiểu ý nghĩa của các từ và câu trong ngữ cảnh cụ thể. Nó tập trung vào việc làm rõ các khái niệm, thực thể và quan hệ trong câu.
Ngữ nghĩa từ vựng
Hiểu nghĩa của từ trong câu dựa trên từ điển hoặc các mô hình từ (word embeddings).
Ngữ nghĩa câu
Kết hợp các từ trong câu để hiểu toàn bộ ý nghĩa của câu. Ví dụ, câu “Con mèo ăn cá” có nghĩa là một con mèo đang tiêu thụ thức ăn là cá.
Ý nghĩa
Phân tích ngữ nghĩa giúp mô hình NLP hiểu sâu hơn về nội dung và ý nghĩa tổng thể của văn bản, thay vì chỉ nhận dạng từ ngữ đơn lẻ.
2.3. Phân tích ngữ cảnh (Contextual Analysis)
Phân tích ngữ cảnh là việc hiểu nội dung của từ và câu trong bối cảnh cụ thể. Một từ có thể mang nhiều ý nghĩa khác nhau tùy thuộc vào ngữ cảnh, và phân tích ngữ cảnh giúp xác định nghĩa đúng của từ trong câu.
Ví dụ
Từ “đá” trong câu “anh ấy đá bóng” có nghĩa là hành động, nhưng trong câu “cục đá nằm trên mặt đất”, từ “đá” lại mang nghĩa là một vật thể.
Cơ chế chú ý (Attention Mechanism)
Trong các mô hình hiện đại như Transformer, cơ chế này giúp máy học tập trung vào các từ quan trọng trong ngữ cảnh, đồng thời hiểu rõ mối liên hệ giữa các từ trong một câu dài hoặc một đoạn văn.
Ý nghĩa
Phân tích ngữ cảnh giúp mô hình NLP hiểu được ý nghĩa của từ dựa trên câu hoặc đoạn văn xung quanh, nâng cao độ chính xác trong các tác vụ như dịch thuật hoặc trả lời câu hỏi.
2.4. Phân đoạn văn bản (Text Segmentation)
Phân đoạn văn bản là quá trình chia nhỏ văn bản thành các phần có ý nghĩa như từ, câu hoặc đoạn văn.
Phân đoạn từ (Tokenization)
Tách văn bản thành các đơn vị nhỏ hơn gọi là từ (tokens). Ví dụ, câu “Tôi thích học máy” có thể được tách thành các từ “Tôi”, “thích”, “học”, “máy”.
Phân đoạn câu (Sentence Segmentation)
Tách văn bản thành các câu rời rạc. Điều này rất quan trọng trong các ứng dụng như phân tích cảm xúc hay tóm tắt văn bản.
Ý nghĩa
Phân đoạn văn bản là bước quan trọng đầu tiên trong nhiều hệ thống NLP, giúp các mô hình xử lý và phân tích văn bản dễ dàng hơn.
2.5. Nhận dạng thực thể (Named Entity Recognition – NER)
Nhận dạng thực thể có tên (Named Entity Recognition – NER) là quá trình xác định và phân loại các thực thể trong văn bản, như tên người, địa điểm, tổ chức, hoặc các số liệu cụ thể.
Ví dụ
Trong câu “Bill Gates thành lập Microsoft tại Hoa Kỳ”, NER sẽ xác định “Bill Gates” là một người, “Microsoft” là tổ chức, và “Hoa Kỳ” là địa điểm.
Các loại thực thể phổ biến:
- Tên người (Person): Ví dụ, Elon Musk, Barack Obama.
- Địa điểm (Location): Ví dụ, Hà Nội, New York.
- Tổ chức (Organization): Ví dụ, Apple, Google.
- Ngày tháng (Date): Ví dụ, 2023, tháng 9.
Ý nghĩa
NER giúp trích xuất các thông tin quan trọng từ văn bản và là một phần quan trọng trong các hệ thống phân tích dữ liệu lớn, tìm kiếm thông tin và trợ lý ảo.
3. Phương pháp trong NLP
Xử lý ngôn ngữ tự nhiên (NLP) là một lĩnh vực phức tạp, bao gồm nhiều phương pháp khác nhau để phân tích và hiểu ngôn ngữ của con người. Trong phần này, chúng ta sẽ đi sâu vào các phương pháp chính được sử dụng trong NLP, từ những kỹ thuật cơ bản như Bag of Words, TF-IDF, đến những mô hình tiên tiến hơn như Word Embeddings và Transformer.

3.1. Bag of Words (BoW)
Bag of Words (BoW) là một trong những kỹ thuật cơ bản và đơn giản nhất trong NLP để biểu diễn văn bản. BoW không quan tâm đến ngữ pháp hay thứ tự của các từ mà chỉ tập trung vào tần suất xuất hiện của các từ trong một văn bản.
Nguyên lý hoạt động
BoW xem văn bản như một tập hợp các từ (hay “túi từ”), sau đó biểu diễn văn bản dưới dạng vector số dựa trên tần suất của mỗi từ. Ví dụ, với hai câu “Mèo uống sữa” và “Chó uống nước”, túi từ sẽ bao gồm [mèo, uống, sữa, chó, nước]. Sau đó, mỗi văn bản sẽ được biểu diễn thành một vector tần suất, chẳng hạn như [1, 1, 1, 0, 0] cho câu đầu tiên và [0, 1, 0, 1, 1] cho câu thứ hai.
Ưu điểm
Đơn giản, dễ hiểu, có thể áp dụng cho các bài toán phân loại văn bản và truy vấn thông tin.
Nhược điểm
BoW không xem xét đến ngữ nghĩa hay thứ tự từ trong câu, dẫn đến mất mát thông tin ngữ cảnh.
3.2. TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF là một cải tiến của BoW, giúp giảm thiểu ảnh hưởng của các từ phổ biến nhưng ít quan trọng trong văn bản, ví dụ như “và”, “là”, “nhưng”.
Cách tính toán
- TF (Term Frequency): Là tần suất xuất hiện của từ trong văn bản.
- IDF (Inverse Document Frequency): Là nghịch đảo của tần suất xuất hiện của từ trong toàn bộ tập tài liệu. Các từ xuất hiện thường xuyên trong nhiều tài liệu sẽ có trọng số thấp hơn.
Công thức TF-IDF:
\[\text{TF-IDF}(t, d) = \text{TF}(t, d) \times \log\left(\frac{N}{\text{DF}(t)}\right)\]
Trong đó:
- t: Một từ
- d: Một tài liệu cụ thể
- N: Tổng số tài liệu trong tập dữ liệu
- DF(t): Số tài liệu chứa từ t
Ưu điểm
TF-IDF giúp loại bỏ các từ thường xuyên xuất hiện nhưng không mang nhiều giá trị ngữ nghĩa, đồng thời làm nổi bật các từ đặc trưng của từng văn bản.
Nhược điểm
Giống như BoW, TF-IDF không xem xét đến ngữ cảnh hay thứ tự từ, do đó không phù hợp cho các bài toán đòi hỏi hiểu sâu về ngữ nghĩa.
3.3. Word Embeddings
Word Embeddings là một bước tiến lớn trong NLP, giúp biểu diễn các từ dưới dạng vector số trong không gian liên tục, trong đó các từ có ngữ nghĩa tương tự sẽ nằm gần nhau. Phương pháp này đã cải thiện đáng kể hiệu suất của các mô hình học máy trong các tác vụ ngôn ngữ.
Word2Vec
- Skip-gram: Dự đoán từ ngữ cảnh dựa trên từ hiện tại. Mô hình này cố gắng dự đoán các từ xung quanh (ngữ cảnh) của một từ trung tâm.
- Continuous Bag of Words (CBOW): Dự đoán từ hiện tại dựa trên ngữ cảnh. Mô hình CBOW dự đoán từ ở giữa dựa trên các từ xung quanh.
- Cả hai phương pháp này đều học cách biểu diễn các từ dưới dạng vector số, trong đó khoảng cách giữa các vector phản ánh mức độ tương đồng về ngữ nghĩa giữa các từ.
GloVe (Global Vectors for Word Representation)
Khác với Word2Vec, GloVe học các vector từ dựa trên tần suất đồng xuất hiện của từ trong toàn bộ tập dữ liệu. Nó cố gắng tối ưu hóa việc biểu diễn các từ sao cho các từ xuất hiện cùng nhau trong văn bản sẽ có vector gần nhau.
- Ưu điểm: Word embeddings giúp máy học nắm bắt được mối quan hệ ngữ nghĩa giữa các từ và có thể áp dụng cho nhiều tác vụ NLP như phân loại văn bản, dịch máy và phân tích cảm xúc.
- Nhược điểm: Không thể xử lý tốt các từ không có trong từ điển (out-of-vocabulary words) và không nắm bắt được ngữ cảnh thay đổi theo thời gian.
3.4. Mô hình Transformer
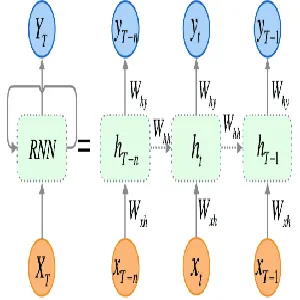
Mô hình Transformer là một trong những đột phá lớn nhất trong lĩnh vực NLP, đặc biệt sau khi mô hình này được giới thiệu bởi Vaswani và các cộng sự vào năm 2017. Transformer đã thay thế hoàn toàn các mô hình dựa trên RNN và LSTM trong nhiều tác vụ ngôn ngữ, bao gồm dịch máy và sinh văn bản.
Cấu trúc mô hình
Transformer sử dụng cơ chế Attention (cơ chế chú ý) để xác định những phần nào của câu cần được chú trọng trong quá trình xử lý. Cụ thể, cơ chế này giúp mô hình tự động học cách tập trung vào các từ quan trọng trong câu khi phân tích hoặc dịch văn bản.
- Self-Attention: Mỗi từ trong câu có thể “chú ý” đến tất cả các từ khác trong câu, không phụ thuộc vào khoảng cách vị trí giữa các từ.
- Encoder-Decoder: Mô hình Transformer bao gồm một phần Encoder (mã hóa) và Decoder (giải mã), đặc biệt hữu ích trong các tác vụ dịch máy.
Các mô hình Transformer phổ biến
- BERT (Bidirectional Encoder Representations from Transformers): Một mô hình mạnh mẽ trong NLP, được huấn luyện theo hai chiều, nghĩa là nó học cách dự đoán các từ dựa trên cả bối cảnh trước và sau trong một câu.
- GPT (Generative Pretrained Transformer): Một mô hình lớn khác, được huấn luyện chủ yếu theo một chiều (từ trước ra sau), nổi tiếng với khả năng sinh văn bản tự nhiên, sáng tạo.
Ưu điểm
Transformer có khả năng xử lý song song, nhanh hơn và hiệu quả hơn so với các mô hình tuần tự như LSTM, đồng thời cho phép học các mối quan hệ phức tạp giữa các từ trong văn bản.
Nhược điểm
Mô hình Transformer đòi hỏi lượng tài nguyên tính toán lớn, dẫn đến chi phí cao trong huấn luyện.
4. Ứng dụng thực tế của NLP
Với khả năng biến ngôn ngữ tự nhiên thành dạng mà máy móc có thể hiểu được, NLP đã có những ứng dụng mạnh mẽ trong nhiều lĩnh vực khác nhau. Dưới đây là một số ứng dụng thực tế nổi bật của NLP trong cuộc sống và công việc hàng ngày.

4.1. Trợ lý ảo và Chatbot
Một trong những ứng dụng phổ biến nhất của NLP là trong các trợ lý ảo như Siri, Google Assistant, và Alexa. Các hệ thống này sử dụng NLP để hiểu các câu lệnh bằng ngôn ngữ tự nhiên từ người dùng, sau đó đưa ra phản hồi hoặc thực hiện hành động dựa trên yêu cầu đó. Chatbot cũng hoạt động tương tự, hỗ trợ dịch vụ khách hàng, trả lời các câu hỏi thường gặp, và thậm chí giúp tự động hóa quy trình tư vấn y tế hoặc tài chính.
4.2. Tìm kiếm thông tin
NLP được sử dụng để cải thiện khả năng tìm kiếm thông tin trên các công cụ tìm kiếm như Google hoặc Bing. Khi bạn nhập truy vấn tìm kiếm, hệ thống NLP sẽ phân tích ngôn ngữ của truy vấn đó và đưa ra kết quả phù hợp nhất. Ngoài ra, các hệ thống này còn có thể dự đoán từ khóa, cải thiện trải nghiệm tìm kiếm của người dùng.
4.3. Phân tích cảm xúc
Phân tích cảm xúc (Sentiment Analysis) là một ứng dụng quan trọng khác của NLP, đặc biệt trong lĩnh vực marketing và nghiên cứu thị trường. Công nghệ này cho phép các doanh nghiệp phân tích phản hồi từ khách hàng trên mạng xã hội, đánh giá cảm xúc từ các bài viết, bình luận và từ đó hiểu rõ hơn về tâm lý của khách hàng đối với sản phẩm hoặc thương hiệu.
4.4. Dịch ngôn ngữ tự động
Các công cụ dịch ngôn ngữ như Google Dịch, Microsoft Translator cũng là kết quả của NLP. Những hệ thống này có khả năng dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác với độ chính xác ngày càng cao, nhờ việc phân tích ngữ pháp, cú pháp và ngữ nghĩa của câu.
4.5. Tự động hóa quy trình kinh doanh
NLP cũng giúp tự động hóa nhiều quy trình trong doanh nghiệp như xử lý email, phân loại tài liệu, và quản lý thông tin. Ví dụ, trong lĩnh vực tài chính, NLP được sử dụng để phân tích văn bản pháp lý, báo cáo tài chính, và thậm chí là dự đoán xu hướng thị trường thông qua phân tích các tin tức và thông cáo báo chí.
4.6. Chẩn đoán y tế
Trong lĩnh vực y tế, NLP được ứng dụng để phân tích hồ sơ bệnh án, chẩn đoán bệnh dựa trên triệu chứng được mô tả bằng văn bản và hỗ trợ bác sĩ trong việc đưa ra quyết định. Điều này giúp tiết kiệm thời gian và giảm thiểu sai sót trong quy trình chẩn đoán và điều trị.
5. Thách thức của NLP
5.1. Hiểu ngữ nghĩa sâu sắc
Một trong những thách thức lớn nhất của NLP là khả năng hiểu ngữ nghĩa sâu sắc của ngôn ngữ tự nhiên. Máy móc có thể hiểu từ vựng và cú pháp, nhưng việc nắm bắt ý nghĩa thực sự của câu nói trong ngữ cảnh phức tạp lại là một bài toán khó. Ngôn ngữ con người chứa nhiều ẩn dụ, từ đa nghĩa và ngữ cảnh văn hóa có thể thay đổi hoàn toàn nghĩa của một câu. NLP cần phải hiểu được các sắc thái này để có thể phản hồi chính xác.
5.2. Xử lý ngôn ngữ đa dạng
Thế giới có hàng nghìn ngôn ngữ và thậm chí trong cùng một ngôn ngữ cũng có vô số biến thể và phương ngữ. Việc phát triển các mô hình NLP có thể hoạt động tốt trên tất cả các ngôn ngữ và biến thể đó là một thách thức lớn. Ngoài ra, nguồn dữ liệu huấn luyện cho các ngôn ngữ ít phổ biến cũng rất hạn chế, khiến việc phát triển các hệ thống NLP đa ngôn ngữ trở nên khó khăn hơn.
5.3. Dữ liệu không đồng nhất và phân biệt đối xử
Dữ liệu đầu vào cho các mô hình NLP thường không đồng nhất và có thể mang tính phân biệt đối xử. Các hệ thống học máy thường bị ảnh hưởng bởi thiên vị trong dữ liệu huấn luyện, dẫn đến việc tạo ra những kết quả không công bằng hoặc mang định kiến. Ví dụ, các mô hình NLP có thể thiên vị về giới tính, chủng tộc hoặc ngôn ngữ dựa trên dữ liệu mà chúng được huấn luyện. Khắc phục vấn đề này là một nhiệm vụ quan trọng để đảm bảo các hệ thống NLP công bằng và đáng tin cậy hơn.
5.4.. Quyền riêng tư và bảo mật
Với việc NLP được ứng dụng rộng rãi trong việc phân tích văn bản và giọng nói, vấn đề quyền riêng tư và bảo mật trở thành mối lo ngại lớn. Khi các mô hình NLP xử lý thông tin nhạy cảm như email cá nhân hoặc hồ sơ y tế, cần phải đảm bảo rằng dữ liệu được bảo vệ và không bị lạm dụng.
5.5. Hiệu suất và chi phí
Các mô hình NLP hiện đại, như các mô hình dựa trên Transformer (ví dụ GPT), yêu cầu rất nhiều tài nguyên tính toán để huấn luyện và triển khai. Điều này làm tăng chi phí và giảm khả năng tiếp cận của các doanh nghiệp nhỏ hoặc các tổ chức phi lợi nhuận. Tối ưu hóa hiệu suất và giảm chi phí triển khai là những thách thức quan trọng trong tương lai.
6. Kết luận
Xử lý ngôn ngữ tự nhiên (NLP) đã và đang trở thành một lĩnh vực quan trọng trong trí tuệ nhân tạo, với tiềm năng cải thiện đáng kể cách máy tính hiểu và tương tác với ngôn ngữ của con người. Từ phân tích cú pháp, ngữ nghĩa đến nhận dạng thực thể, NLP mang đến những tiến bộ vượt bậc trong các ứng dụng thực tế như dịch thuật, trợ lý ảo, phân tích cảm xúc và nhiều lĩnh vực khác.
Mặc dù NLP đã đạt được nhiều thành tựu, thách thức vẫn còn tồn tại, đặc biệt là trong việc nắm bắt ngữ cảnh phức tạp, xử lý ngôn ngữ đa dạng và loại bỏ thiên vị trong dữ liệu. Tuy nhiên, với sự phát triển của các mô hình ngôn ngữ lớn và kỹ thuật học máy hiện đại, tương lai của NLP rất hứa hẹn, mở ra nhiều cơ hội mới để giải quyết các vấn đề ngôn ngữ ngày càng phức tạp và mang lại lợi ích lớn cho xã hội.