1. Giới thiệu về CNN
Convolutional Neural Networks (CNN) là một trong những kiến trúc mạng nơ-ron nhân tạo đặc biệt, chủ yếu được sử dụng để xử lý dữ liệu hình ảnh, video, và các dạng dữ liệu có cấu trúc không gian như tín hiệu âm thanh và chuỗi dữ liệu. CNN xuất phát từ việc mô phỏng lại cơ chế hoạt động của vỏ não thị giác của con người, nơi các tế bào thần kinh có khả năng phản ứng với các kích thích thị giác, từ các đường biên đến các hình dạng phức tạp.
CNN đã có sự phát triển đáng kể trong vài thập kỷ qua, với bước ngoặt là sự thành công của mô hình LeNet-5 do Yann LeCun giới thiệu vào năm 1998, được sử dụng cho việc nhận dạng chữ số viết tay. Tuy nhiên, CNN thực sự trở nên nổi tiếng nhờ mô hình AlexNet, chiến thắng trong cuộc thi ImageNet Large Scale Visual Recognition Challenge (ILSVRC) vào năm 2012. Sự thành công của AlexNet mở ra một kỷ nguyên mới cho nghiên cứu trong thị giác máy tính và học sâu.
2. Cấu trúc của CNN
CNN được xây dựng từ nhiều lớp khác nhau, mỗi lớp thực hiện một nhiệm vụ cụ thể trong quá trình trích xuất và xử lý đặc trưng từ dữ liệu đầu vào. Cấu trúc điển hình của CNN bao gồm bốn loại lớp chính: Convolutional Layer, Activation Layer, Pooling Layer, và Fully Connected Layer. Mỗi lớp có vai trò cụ thể và cùng nhau tạo thành một mạng CNN mạnh mẽ.
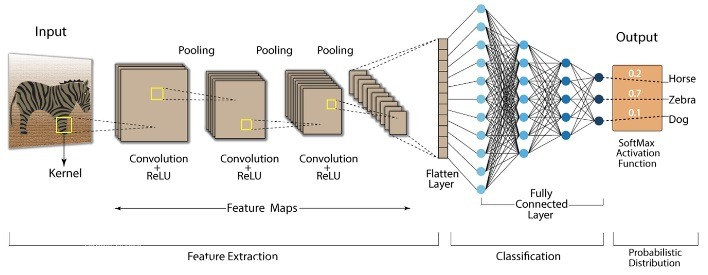
2.1. Convolutional Layer
Lớp tích chập là nền tảng cốt lõi của CNN, chịu trách nhiệm trích xuất các đặc trưng từ hình ảnh đầu vào. Bộ lọc (filter) sẽ trượt qua ảnh và tính toán phép tích chập giữa ảnh và bộ lọc đó.
Công thức của phép tích chập hai chiều:
\[Y[i,j] = \sum_{m} \sum_{n} X[i+m, j+n] \cdot K[m,n]\]
Trong đó:
- \( X \): Ma trận đầu vào biểu diễn hình ảnh.
- \( K \): Ma trận kernel (bộ lọc).
- \( Y[i,j] \): Giá trị đầu ra tại vị trí \( (i,j) \) sau khi thực hiện phép tích chập.
2.2. Activation Layer
Sau khi thực hiện phép tích chập, dữ liệu sẽ đi qua lớp kích hoạt để thêm tính phi tuyến vào mô hình. Hàm kích hoạt phổ biến nhất là ReLU (Rectified Linear Unit):
\[\text{ReLU}(x) = \max(0, x)\]
ReLU giúp loại bỏ các giá trị âm trong đầu ra của phép tích chập, giữ lại các giá trị dương và giúp tăng tốc quá trình huấn luyện.
2.3. Pooling Layer
Lớp gộp có nhiệm vụ giảm kích thước không gian của bản đồ đặc trưng, giúp giảm số lượng tham số và tính toán trong mạng. Lớp gộp còn làm cho mô hình bền vững hơn với các phép biến đổi như dịch chuyển hoặc xoay ảnh.
Phổ biến nhất là Max Pooling, với công thức:
\[Y[i,j] = \max(X[i:i+f, j:j+f])\]
Trong đó \( f \) là kích thước của cửa sổ gộp.
2.4. Fully Connected Layer
Sau khi đi qua nhiều lớp tích chập và gộp, các bản đồ đặc trưng sẽ được làm phẳng thành một vector một chiều và đưa vào các lớp hoàn toàn kết nối.
Lớp này sử dụng hàm kích hoạt softmax cho các bài toán phân loại đa lớp:
\[\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}}\]
Trong đó:
- \( z_i \): Đầu ra của nơ-ron tại lớp fully connected.
- \( n \): Số lớp phân loại đầu ra.
2.5. Backpropagation
Quá trình huấn luyện CNN sử dụng thuật toán lan truyền ngược để tối ưu hóa các tham số bằng cách giảm thiểu hàm mất mát (loss function). Hàm mất mát phổ biến cho bài toán phân loại là cross-entropy:
\[L = – \sum_{i} y_i \log(\hat{y_i})\]
Trong đó:
- \( y_i \): Giá trị thực tế (ground truth) cho lớp \( i \).
- \( \hat{y_i} \): Xác suất dự đoán của mô hình cho lớp \( i \).
2.6. Triển khai CNN bằng PyTorch
Dưới đây là một ví dụ đơn giản về cấu trúc CNN với PyTorch để phân loại ảnh MNIST:
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# Lớp tích chập đầu tiên: 1 kênh đầu vào, 32 kênh đầu ra, kernel size là 3x3
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
# Lớp tích chập thứ hai: 32 kênh đầu vào, 64 kênh đầu ra, kernel size là 3x3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
# Lớp gộp: kernel size là 2x2
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
# Lớp fully connected đầu tiên: từ 64 * 7 * 7 nút tới 128 nút
self.fc1 = nn.Linear(64 * 7 * 7, 128)
# Lớp fully connected thứ hai: từ 128 nút tới 10 nút (ứng với 10 lớp phân loại cho các chữ số 0-9)
self.fc2 = nn.Linear(128, 10)
# Hàm kích hoạt ReLU
self.relu = nn.ReLU()
def forward(self, x):
# Tích chập với conv1, sau đó là ReLU và Max Pooling
x = self.pool(self.relu(self.conv1(x)))
# Tích chập với conv2, sau đó là ReLU và Max Pooling
x = self.pool(self.relu(self.conv2(x)))
# Làm phẳng từ tensor 4 chiều xuống 2 chiều để đưa vào fully connected layers
x = x.view(-1, 64 * 7 * 7)
# Lớp fully connected đầu tiên với ReLU
x = self.relu(self.fc1(x))
# Lớp fully connected cuối cùng, đầu ra là 10 lớp phân loại
x = self.fc2(x)
return xGiải thích:
- conv1, conv2: Các lớp tích chập để trích xuất đặc trưng.
- pool: Lớp Max Pooling giảm kích thước ảnh.
- fc1, fc2: Các lớp fully connected thực hiện phân loại cuối cùng.
- relu: Hàm kích hoạt ReLU.
Đây là một ví dụ đơn giản về CNN. Các cấu trúc CNN thực tế có thể phức tạp hơn, bao gồm nhiều tầng tích chập và gộp để trích xuất các đặc trưng phức tạp từ ảnh.
3. Các khái niệm chính trong CNN
3.1. Stride
Stride là bước nhảy của cửa sổ tích chập khi nó di chuyển qua ảnh đầu vào. Giá trị stride quyết định tốc độ di chuyển của cửa sổ. Nếu stride bằng 1, cửa sổ tích chập sẽ di chuyển từng bước một qua các pixel, còn nếu stride bằng 2, cửa sổ sẽ di chuyển cách 2 pixel một lần.
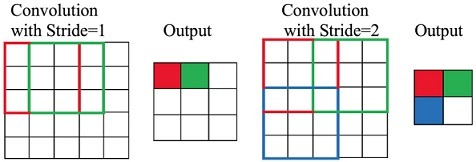
Giá trị stride càng lớn, kích thước của đầu ra sẽ nhỏ hơn vì cửa sổ tích chập sẽ bỏ qua nhiều pixel hơn. Điều này có thể làm giảm độ phân giải của đầu ra, nhưng đồng thời giảm thiểu khối lượng tính toán.
3.2. Padding
Padding là kỹ thuật thêm các pixel giả (thường là giá trị 0, gọi là zero padding) xung quanh biên của ảnh đầu vào. Điều này giúp duy trì kích thước đầu ra sau khi tích chập.
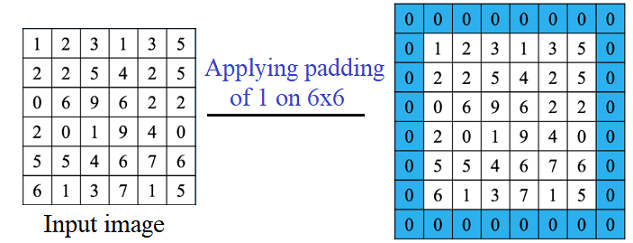
Trong nhiều trường hợp, người ta thêm padding để kích thước đầu ra của lớp tích chập không bị giảm. Ví dụ, nếu không có padding, mỗi lần tích chập có thể làm giảm kích thước không gian của ảnh đầu ra.
3.3. Filters (Kernels)
Filters hay còn gọi là kernels là các ma trận nhỏ được áp dụng lên ảnh đầu vào trong quá trình tích chập. Các bộ lọc này thực hiện việc quét qua toàn bộ ảnh đầu vào, tính toán các giá trị mới dựa trên phép nhân tích chập giữa bộ lọc và các phần tương ứng của ảnh.
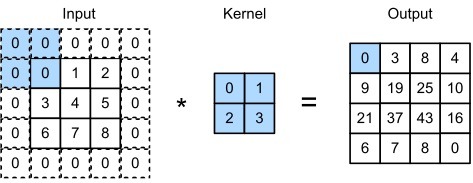
Mỗi bộ lọc sẽ phát hiện các đặc trưng cụ thể, chẳng hạn như cạnh, đường nét, hoặc chi tiết phức tạp hơn ở các lớp sâu. Mỗi lớp tích chập trong mạng CNN có thể sử dụng nhiều bộ lọc để phát hiện nhiều đặc trưng khác nhau.
3.4. Feature Maps
Feature Maps (Bản đồ đặc trưng) là kết quả đầu ra của một lớp tích chập sau khi áp dụng các bộ lọc lên ảnh đầu vào. Đây là nơi lưu trữ các đặc trưng đã được phát hiện bởi các bộ lọc trong quá trình tích chập.
Feature maps thể hiện sự hiện diện của các đặc trưng (như cạnh, góc) trong một bức ảnh tại các vị trí không gian khác nhau. Các feature maps càng sâu trong mạng CNN thì chứa các đặc trưng càng phức tạp, trừu tượng hơn.
4. Quá trình huấn luyện trong CNN
Quá trình huấn luyện trong CNN nhằm mục đích tối ưu hóa các tham số (weights) của các lớp tích chập, giúp mạng có khả năng nhận diện và phân loại hình ảnh một cách chính xác. Dưới đây là các bước chính trong quá trình huấn luyện của CNN:
4.1. Chuẩn bị dữ liệu
Trước khi bắt đầu quá trình huấn luyện, dữ liệu cần được chuẩn bị cẩn thận:
Tiền xử lý dữ liệu
Các hình ảnh đầu vào thường cần được điều chỉnh kích thước, chuẩn hóa giá trị pixel về một khoảng giá trị nhất định (ví dụ: từ 0 đến 1), và đôi khi được áp dụng các kỹ thuật tăng cường dữ liệu (data augmentation) như xoay, lật ảnh để tăng tính đa dạng của dữ liệu.
Ví dụ code với pytorch:
# 1. Định nghĩa các phép biến đổi (transform) cho dữ liệu
transform = transforms.Compose([
transforms.Resize((28, 28)), # Thay đổi kích thước ảnh về 28x28
transforms.ToTensor(), # Chuyển đổi ảnh thành tensor
transforms.Normalize((0.1307,), (0.3081,)) # Chuẩn hóa dữ liệu với giá trị trung bình và độ lệch chuẩn
])
Phân chia dữ liệu
Bộ dữ liệu thường được chia thành 3 phần:
- Dữ liệu huấn luyện (training set): Dùng để huấn luyện mô hình.
- Dữ liệu kiểm định (validation set): Dùng để đánh giá mô hình trong quá trình huấn luyện nhằm ngăn chặn hiện tượng overfitting.
- Dữ liệu kiểm tra (test set): Dùng để đánh giá mô hình sau khi hoàn thành huấn luyện.
4.2. Truyền dữ liệu qua mạng
Quá trình huấn luyện bắt đầu bằng cách truyền dữ liệu qua mạng CNN. Các bước chính bao gồm:
Forward pass
Trong bước này, dữ liệu đầu vào đi qua các lớp của mạng CNN, bắt đầu từ lớp tích chập, lớp kích hoạt (ReLU), lớp pooling (giảm kích thước), và cuối cùng là lớp fully connected (kết nối đầy đủ).
- Các lớp tích chập (convolutional layers) thực hiện tích chập với các bộ lọc (filters) để phát hiện các đặc trưng của ảnh.
- Các lớp pooling giảm kích thước của bản đồ đặc trưng (feature maps), giúp giảm khối lượng tính toán và trích xuất các đặc trưng chính.
- Cuối cùng, lớp fully connected tạo ra dự đoán (output) về lớp của ảnh.
4.3. Tính toán hàm mất mát (Loss function)
Sau khi nhận được đầu ra từ mạng, một hàm mất mát (loss function) được sử dụng để đo lường sự khác biệt giữa dự đoán của mạng và giá trị nhãn thực tế của dữ liệu:
Hàm mất mát phổ biến: Đối với các bài toán phân loại hình ảnh, hàm mất mát phổ biến nhất là cross-entropy loss, giúp tính toán mức độ sai lệch giữa xác suất dự đoán của mạng và nhãn thực tế.
Ví dụ code pytorch sử dụng cross-entropy loss:
model = SimpleCNN()
criterion = nn.CrossEntropyLoss() # Hàm mất mát Cross-Entropy
...
...
outputs = model(inputs) # Forward pass
loss = criterion(outputs, labels) # Tính toán hàm mất mát4.4. Lan truyền ngược (Backpropagation)
Sau khi tính toán hàm mất mát, quá trình lan truyền ngược (backpropagation) bắt đầu để cập nhật các tham số (weights) của mạng:
Tính gradient: Quá trình này sử dụng đạo hàm của hàm mất mát với từng trọng số (weight) của các lớp thông qua quy tắc chuỗi (chain rule). Điều này cho phép tính toán được gradient, cho biết trọng số nào cần điều chỉnh và điều chỉnh bao nhiêu.
Cập nhật weights: Các tham số weights của mạng được cập nhật bằng cách sử dụng thuật toán tối ưu hóa, phổ biến nhất là stochastic gradient descent (SGD) hoặc các biến thể của nó như Adam. Các tham số này được điều chỉnh để làm giảm hàm mất mát trong các lần lặp tiếp theo.
4.5. Early stopping
Quá trình trên (forward pass, tính hàm mất mát, backpropagation) diễn ra trong nhiều lần lặp gọi là epoch:
Trong mỗi epoch, mạng sẽ trải qua toàn bộ dữ liệu huấn luyện. Sau đó, mạng tiếp tục được đánh giá trên bộ dữ liệu kiểm định (validation set) để theo dõi độ chính xác và kiểm tra tình trạng overfitting.
Early stopping: Trong quá trình huấn luyện, nếu độ chính xác trên tập kiểm định bắt đầu giảm mặc dù độ chính xác trên tập huấn luyện tăng, quá trình huấn luyện có thể được dừng sớm (early stopping) để tránh hiện tượng overfitting.
5. Ứng dụng thực tế của CNN
Mạng Nơ-ron tích chập (CNN) là một trong những công nghệ quan trọng và được sử dụng rộng rãi trong nhiều lĩnh vực liên quan đến xử lý hình ảnh và dữ liệu không gian. Dưới đây là các ứng dụng thực tế phổ biến của CNN:
5.1. Image Recognition & Classification
CNN đã đạt được nhiều thành công vượt trội trong các bài toán nhận diện và phân loại hình ảnh. Các mô hình CNN có thể phân loại các đối tượng trong ảnh với độ chính xác rất cao.
Ứng dụng: Phân loại động vật, nhận diện các loại phương tiện giao thông, phân loại hoa và thực phẩm, v.v.
Ví dụ thực tế: Trong Google Photos, CNN được sử dụng để phân loại hình ảnh thành các nhóm dựa trên nội dung như con người, phong cảnh, đồ vật.
5.2. Optical Character Recognition – OCR
CNN không chỉ ứng dụng cho hình ảnh mà còn được áp dụng trong xử lý ngôn ngữ tự nhiên và nhận diện ký tự quang học (OCR), giúp máy tính nhận diện và chuyển đổi văn bản từ hình ảnh sang dạng văn bản số.
Ứng dụng: Quét và nhận diện văn bản trong các tài liệu giấy, biển báo giao thông, sách, hoặc hóa đơn.
Ví dụ thực tế: Google Translate sử dụng CNN trong tính năng dịch trực tiếp từ hình ảnh bằng cách nhận diện văn bản trong ảnh và dịch sang ngôn ngữ khác.
5.3. Image Segmentation
Phân đoạn ảnh là quá trình chia một bức ảnh thành các phần hoặc đối tượng khác nhau dựa trên các đặc điểm. CNN giúp phân đoạn các vùng khác nhau trong ảnh và xác định các đặc trưng riêng biệt của từng vùng.
Ứng dụng: Phân đoạn trong y tế để xác định các tế bào ung thư hoặc các mô bất thường trong ảnh y khoa, phân đoạn đường trong hình ảnh vệ tinh.
Ví dụ thực tế: Trong y học, CNN giúp phân đoạn các cơ quan nội tạng hoặc vùng mô ung thư từ các ảnh chụp CT hoặc MRI, hỗ trợ chẩn đoán và phẫu thuật.
5.4. Autonomous Driving
CNN đóng vai trò quan trọng trong các hệ thống lái xe tự động, giúp xe nhận diện và phân tích môi trường xung quanh, từ đó đưa ra quyết định về điều hướng và tránh vật cản.
Ứng dụng: Nhận diện biển báo giao thông, làn đường, người đi bộ, phương tiện khác và các vật thể nguy hiểm.
Ví dụ thực tế: Xe tự lái của Tesla sử dụng CNN để xử lý thông tin từ camera và cảm biến, giúp xe di chuyển an toàn trên đường.
5.5. Action Recognition & Video Analysis
CNN cũng được mở rộng sang phân tích video, giúp nhận diện hành động, phân tích chuyển động và trích xuất thông tin từ các đoạn video.
Ứng dụng: Phân tích chuyển động trong các đoạn video thể thao, nhận diện các hành động bất thường trong video giám sát.
Ví dụ thực tế: Các hệ thống giám sát an ninh sử dụng CNN để phát hiện hành vi bất thường hoặc phát hiện sự kiện trong thời gian thực.
6. Kết luận
Convolutional Neural Networks (CNN) là một trong những mô hình quan trọng và mạnh mẽ nhất trong lĩnh vực Deep Learning, đặc biệt hiệu quả cho các bài toán xử lý hình ảnh và nhận diện thị giác. CNN tận dụng các lớp tích chập để tự động trích xuất các đặc trưng từ dữ liệu mà không cần can thiệp của con người trong việc lựa chọn các đặc trưng phù hợp.
Nhờ vào cấu trúc phân cấp, CNN có thể học từ các đặc trưng cơ bản (như cạnh, góc) đến các đặc trưng phức tạp hơn (như hình dạng, đối tượng) khi độ sâu của mạng tăng lên. Các lớp tích chập, lớp gộp, và lớp fully connected kết hợp với nhau giúp CNN có khả năng xử lý dữ liệu lớn và đạt độ chính xác cao trong các bài toán phân loại, nhận diện đối tượng, và các nhiệm vụ khác liên quan đến thị giác máy tính.
Mặc dù có cấu trúc phức tạp và đòi hỏi nhiều tài nguyên tính toán, CNN vẫn đang được nghiên cứu và cải thiện với các phiên bản tiên tiến hơn như ResNet, Inception, YOLO, và nhiều hơn nữa, giúp nâng cao hiệu quả và tốc độ huấn luyện mô hình.